本文是从0开始编写一个Scrapy爬虫案例,将结果保存为本地json格式,其中会介绍一些文件的作用。适合新手一起共同学习入门。文末会给出完整可操作的代码
一、爬取的网站
我们打算爬取的是:http://www.itcast.cn/channel/teacher.shtml网站所有老师的姓名,职称和信息
 在浏览器中右键"检查"或者F12(笔记本需要Fn+F12)可以出现上述调试页面,谷歌插件xpath helper大家推荐大家去下载,比较好用。
在浏览器中右键"检查"或者F12(笔记本需要Fn+F12)可以出现上述调试页面,谷歌插件xpath helper大家推荐大家去下载,比较好用。
二、爬取的详细步骤
1.创建爬虫项目
创建爬虫项目的命令如下:
scrapy startproject 项目名
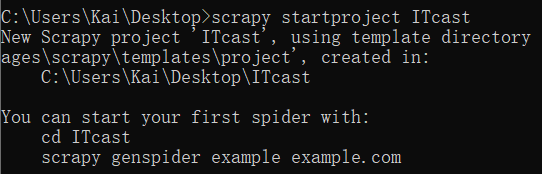
此时在桌面就出现了我们创建的项目文件夹,初始创建所含的内容如下:
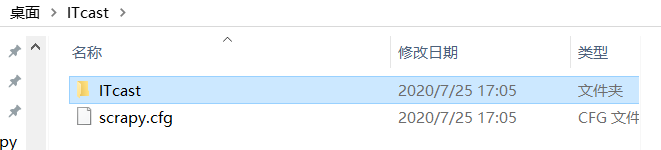


这里我们解释一下每个文件的作用
scrapy.cfg:项目的配置文件
spiders/:我们写的爬虫文件放置在这个文件夹下面
init.py:一般为空文件,但是必须存在,没有__init__.py表明他所在的目录只是目录不是包
items.py:项目的目标文件,定义结构化字段,保存爬取的数据
middlewares.py:项目的中间件
pipelines.py:项目的管道文件
setting.py:项目的设置文件
2.创建爬虫文件
进入到刚刚创建的项目中(cd ITcast)
创建爬虫文件命令如下:
scrapy genspider 文件名(在这里面写入我们的爬虫代码)

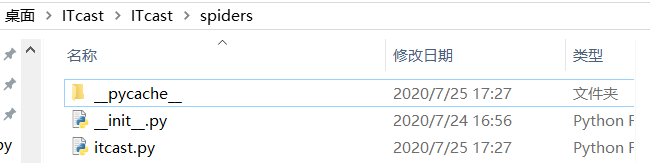
此时spider文件夹下出现了刚刚创建的文件itcast.py
3.编写items.py
该文件用于定义我们要爬取的是哪些具体内容,相当于数据库中的字段或者java中的Pojo类。
import scrapy
class ItcastItem(scrapy.Item):
# define the fields for your item here like:
# 老师姓名
name = scrapy.Field()
# 老师职称
title = scrapy.Field()
# 老师信息
info = scrapy.Field()
4.设置setting.py
该文件为配置文件,文件内容做以下修改:
首先,由于是学习用,可以不遵守robots.txt协议,因此找到ROBOTSTXT_OBEY进行修改
ROBOTSTXT_OBEY = False
其次,我们把ITEM_PIPELINES 注释去掉,得到
ITEM_PIPELINES = {
'Teacher.pipelines.TeacherPipeline': 300,
}
通过以上两个步骤,分别是修改成False和取消注释,我们的配置就完成了。
5.编写itcast.py
import scrapy
from ITcast.items import ItcastItem
class ItcastSpider(scrapy.Spider):
# 爬虫名 启动爬虫时需要的参数 *必须
name = 'itcast'
# 爬取域范围 允许爬虫在这个域名下面进行爬取 可选
allowed_domains = ['http://www.itcast.cn']
# 起始url列表,爬虫执行后第一批请求,将从这个列表里获取
start_urls = ['http://www.itcast.cn/channel/teacher.shtml']
# 解析响应文件 //div[@class='li_txt']是xpath语法 大家可以学一学
def parse(self, response):
node_list = response.xpath("//div[@class='li_txt']")
items = [] # 用来存储所有的item字段
for node in node_list:
# 创建item字段对象,用来存储信息
item = ItcastItem()
name = node.xpath("./h3/text()").extract()
title = node.xpath("./h4/text()").extract()
info = node.xpath("./p/text()").extract()
# 注意 这里返回的不是文本而是一个xpath对象
# 需要用.extrac()将xpath对象转化为 Unicode字符串
item['name'] = name[0]
item['title'] = title[0]
item['info'] = info[0]
items.append(item)
return items # 返回给engine引擎
6.开始爬取,并保存为json格式
下面开始爬取所需信息,cmd命令如下:
scrapy crawl 项目名 -o 项目名.json
这里我的命令即为:scrapy crawl itcast -o itcast.json
这里还可以存储为csv格式:scrapy crawl 项目名 -o 项目名.csv
 这里可以看到爬取的信息为json格式,同时spider文件夹下出现了itcast.json的本地文件。
这里可以看到爬取的信息为json格式,同时spider文件夹下出现了itcast.json的本地文件。

这里打开itcast.json文件可以看到格式是以Unicode编码:

我们需要json转化器查看,点击json在线解析https://www.json.cn/,复制进去即可解析:

至此,整个的scrapy爬取工作完成了!
最后的源码详见:
https://github.com/zmk-c/scrapy/tree/master/scrapy_itcast
一波福利,学习scrapy入门的视频:https://www.bilibili.com/video/BV1jx411b7E3