实验环境
Hadoop版本:Hadoop2.7.3
linux版本:Ubuntu
JDK版本:JDK1.7
实验步骤
- 设置HADOOP的PATH和HADOOP CLASSPATH(这里假设java的相关路径已经配置好)
export HADOOP_HOME=/home/luchi/Hadoop/hadoop-2.7.3
export PATH=${HADOOP_HOME}/bin:$PATH
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar- 编辑CountWord.java文件
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}- 编译WordCount.java
注意这里使用的是Hadoop下面的javac进行编译的:
首先转到WordCount.java所在的目录(如果没有转到该子目录,使用路径名的话,那么也就相当于编译一个java包,这里需要在上面的代码上加上相应的包名)
$ hadoop com.sun.tools.javac.Main WordCount.java使用这个命令之后,会生成三个文件:
WordCount
WordCount.class
第一个和第二个其实是WordCount类的两个子静态类,中间用$表示隶属关系
4. 将.class文件打包成jar包
jar cf wc.jar WordCount*.class注意,这里用的是JDK1.7的jar命令,区别于后文的hadoop jar命令
5. 在HDFS文件系统上创建input目录,作为输入文件目录
我是在/user目录下创建了一个input子目录,下面有两个文件file1和file2:
luchi@ubuntu:~/Desktop$ hdfs dfs -ls /user/input
Found 2 items
-rw-r--r-- 1 luchi supergroup 68 2016-10-16 09:40 /user/input/file1
-rw-r--r-- 1 luchi supergroup 15 2016-10-16 09:40 /user/input/file2
file1和file2的文件是:
luchi@ubuntu:~/Desktop$ hdfs dfs -cat /user/input/file1 /user/input/file2
i have a dream
that everyone should chase his dream
and be honest
this is cat 2
注意:这里不需要创建output目录,因为在执行完map-reduce工作之后,会自动生成该目录
6. 执行map-reduce工作
hadoop jar wc.jar WordCount /user/input /user/output需要注意的是,如果WordCount有包名,那么需要在上述命令里面的WordCount前面加上包名
执行成功的显示如下:
16/10/16 10:45:53 INFO mapreduce.Job: Job job_local98859034_0001 completed successfully
16/10/16 10:45:53 INFO mapreduce.Job: Counters: 35
File System Counters
FILE: Number of bytes read=10886
FILE: Number of bytes written=850552
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=234
HDFS: Number of bytes written=106
HDFS: Number of read operations=22
HDFS: Number of large read operations=0
HDFS: Number of write operations=5
Map-Reduce Framework
Map input records=4
Map output records=17
Map output bytes=148
Map output materialized bytes=182
Input split bytes=206
Combine input records=17
Combine output records=16
Reduce input groups=16
Reduce shuffle bytes=182
Reduce input records=16
Reduce output records=16
Spilled Records=32
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=105
Total committed heap usage (bytes)=455553024
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=83
File Output Format Counters
Bytes Written=106
从上面的代码可以看出,了4个map输入,产生了17个map输出,17个combine输入产生了16个combine输出,16个reduce输入产生了16个reduce输出。注意这里的map输入和map输出以及reduce输入和reduce输出指的并不是map和reduce的个数,实际上,FileInputFormat是一个基类,如果不加指定的话,默认的是TextInputFormat,是根据input目录下的文件数来确定map的个数的(对于文件小于block size的情况,对于文件大小大于block的情况则要再分区),这里的input文件夹下面有两个文件,因此,这个任务的job的map个数为2,另一方面,这个hadoop环境是伪分布式的,因此其reduce的个数是1。
- 看一眼我们的输出结果文件:
luchi@ubuntu:~/Desktop$ hdfs dfs -cat /user/output/part-r-00000
2 1
a 1
and 1
be 1
cat 1
chase 1
dream 2
everyone 1
have 1
his 1
honest 1
i 1
is 1
should 1
that 1
this 1
可以看出,词频已经统计完毕了。
代码和结果分析
说明:这是一个HADOOP新手的理解,可能有些地方不对,不对的地方还请指正。
详细的API调用不准备说了,看官方文档即可,因为刚开始学HADOOP,所以还是想把代码执行的经过说下。
代码中TokenizerMapper继承了Mapper这个父类,Mapper这个类是用来进行map操作的,以输入文本为例,代码:
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));这两句指定了输入与输出的路径,本例子中指定的路径是、user/input,接受到这个输入之后,Map-Reduce框架会首先将文本分块,然后每块对应一个map,这里用了4个map输入(指的是有四行文字),每个map是以键值对对应的,key为文本索引位置,value为一行文本的文本,以下面为例(仅仅是示例,没有实际意义):
(0,"i have")
(24,"dream")然后每个map的每个项输入会送入Mapper类,进行map操作,这里使用的是TokenizerMapper这个Mapper子类进行操作。在本例中:
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}TokenizerMapper的作用是,将每个map传来的输入(键值对)进行处理,我们对传进来的传进来的键值对的key并不关心,只有value有作用,上面代码的map方法前两个参数就是这个意思,我们需要对value进行分词处理,这里使用的StringTokenizer这个类进行处理,分词之后,按照(单词,词频)的键值对存储在context中,并作为输出的map,这也是为什么2个map输入会用多个输出map
在这之后,代码中使用了combine操作,其实combine操作买就是局部的reduce,因为在map和reduce之间传递需要带宽,因此combine先是把本地的输出map进行了局部的reduce,比如说,一个map的输出是:
(dream,1)
(dream,1)
经过combine之后的输出是(dream,2),这就减少了传输数据量,减少了带宽的压力。
之后就是reduce操作,当然在reduce之前还是有sort和shuffle过程,shuffle就是把相似的mapper映射到一个reduce块中。本例中reduce是使用IntSumReducer这个类实现的,IntSumReducer继承了Reducer这个父类,和这点Mapper一样。
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}这里的reduce方法和之前的map方法还是有差别的,reduce接受的输入是key一致的,而值的大小不一样的输入,在本例中,key就是word,而values就是该词的词频列表,我们将其相加就得到了这个词的词频。该程序整体的框架如下图:
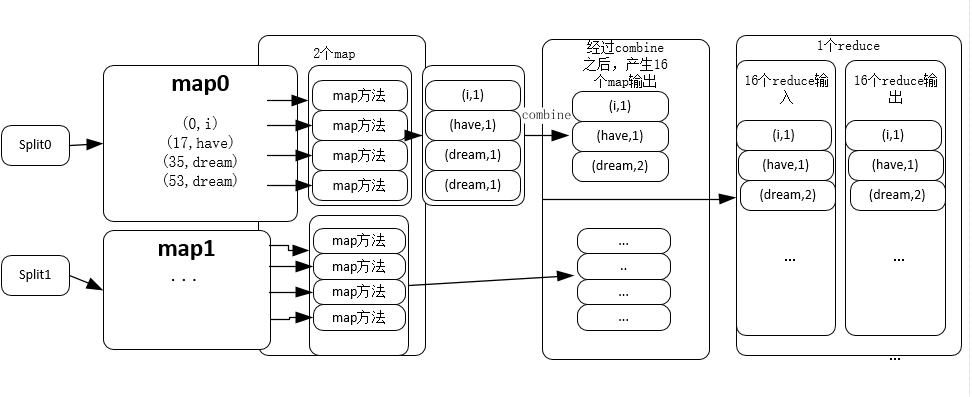
在使用了map方法之后, 本例之中是指TokenizerMapper的map方法,得到17个map,本例子只有两个相同的词就是dream,经过combine之后,将两个(dream,1)合并为(combine,2),得到16个map实际输出,然后这16个输出map经过shuffle和sort送入reduce过程,此时没有单词需要reduce,因为在combine过程中已经将完全一样的词dream合并过了,所以16个reduce输入得到16个reduce输出,然后就得到了结果。
总结
代码执行起来也容易,但是还是有些细节需要探究的,根据这个实验,我粗略的了解了map-reduce的整个过程,当然可能存在一些不当之处,还是需要今后多多学习来补充,欢迎指正。
参考资料:《Hadoop权威指南》