Redis现在是比较流行的缓存数据库,一般刚接触的时候都会发现其可以存储字符串(string)、哈希表(hash)、列表(list)、集合(set)、有序集合(sorted set)等。redis是一个key-value存储,value可以包含上面列出的多种结构,但是key都是字符串。也就是说key是string类型,value为上面类型的一种。
由于以上每种数据结构的存储指令在redis中都不一样,单个看来想要使用redis必须要先区分要存储的对象的结构,然后选择相应的指令。但是这样使用起来确实是很不利的,如果一次要存入多种形式的值,我就要实现多种存储方式。
为了便于开发和使用redis引入了对象,即对象存储。上面的每种数据结构都是一种对象,所以,在项目中只需要实现对象的存储即可。
Redis中每个对象都有一个redisObject结构,该结构中和保存数据相关的三种属性分别是存储数据的类型type、值的编码属性encoding和指针ptr属性:
typedef struct redisObject{
//类型
unsigned type:4;
//编码
unsigned encoding:4;
//指向底层实现数据结构的指针
void *ptr
//虚拟内存和其他信息等.....
}robj;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
| 类型常量 | 对象的名称 | type值 |
|---|---|---|
| REDIS_STRING | 字符串对象 | string |
| REDIS_LIST | 列表对象 | list |
| REDIS_HASH | 哈希对象 | hash |
| REDIS_SET | 集合对象 | set |
| REDIS_ZSET | 有序集合对象 | zset |
获取存储值的类型编码指令:
TYPE key
如,我在redis中存入一个字符串的值:
[root@iZ8vb8r420ejxfron03cj7Z ~]# redis-cli
127.0.0.1:6379> set msg "rhett"
OK
127.0.0.1:6379> get msg
"rhett"
127.0.0.1:6379> type msg
string- 1
- 2
- 3
- 4
- 5
- 6
- 7
| 编码常量 | 对象的名称 | type值 |
|---|---|---|
| REDIS_ENCODING_INT | 整数 | int |
| REDIS_ENCODING_EMBSTR | embstr编码的简单动态字符串(SDS) | list |
| REDIS_ENCODING_RAW | 简单动态字符串 | raw |
| REDIS_ENCODING_HT | 字典 | hashtable |
| REDIS_ENCODING_LINKEDLIST | 双端链表 | linkedlist |
| REDIS_ENCODING_ZIPLIST | 压缩列表 | ziplist |
| REDIS_ENCODING_INTSET | 整数集合 | intset |
| REDIS_ENCODING_SKIPLIST | 跳跃表和字典 | skiplist |
redis中的示例:
[root@iZ8vb8r420ejxfron03cj7Z ~]# redis-cli
127.0.0.1:6379> set msg "rhett"
OK
127.0.0.1:6379> object encoding msg
"embstr"- 1
- 2
- 3
- 4
- 5
特点:快速、非关系、内存存储、不使用表(必要时才用,少量数据,专属命令)
比较:MySQL:关系数据库,大量,增改删查
Redis:服务器关闭时,紧凑的格式将存储在内存中的数据写入硬盘
持久化方法:1.时间点转储:指定时间段内有指定数量的写操作执行
2.将所有修改了数据库的命令全部写入一个只追加文件里面
结构类型(5种)
String:字符串、整数、浮点数
List:链表
Set:唯一无序集,不重复
Hash:键值对,无序散列表
Zset:有序集
String命令:对给定键中的值获取GET、设置SET、删除DEL
$redis-cli
redis 127.0.0.1:6379>set hello world
redis 127.0.0.1:6379>get hello
redis 127.0.0.1:6379>del hello
List:
RPUSH:推入右端,返回长度
LRANGE:获取列表在给定范围上的所有值
LINDEX:获取列表在给定位置上的单个元素
LPOP:从左端弹出一个值并返回弹出的值
Set:
SADD:将给定元素加入集合
SMEMBERS:返回集合包含的所有元素
SISMEMBER:检查给定元素是否存在于集合中
SREM:如果在,移除
Hash:
HSET:关联指定键值对
HGET:获取键的值
HGETALL:获取所有键值对
HDEL:移除键
Zset:
ZADD:给定分值的成员添加到有序集合里
ZRANGE:根据元素位置,从中取多个元素
ZRANGEBYSCORE:获取给的分值范围内所有元素
ZREM:删除给定成员
下面以redis3.2的正式版源码分析集中存储机构:
typedef char *sds;
/*下面是sds数据结构的具体实现*/
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};

#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
static inline size_t sdslen(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->len;
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
}
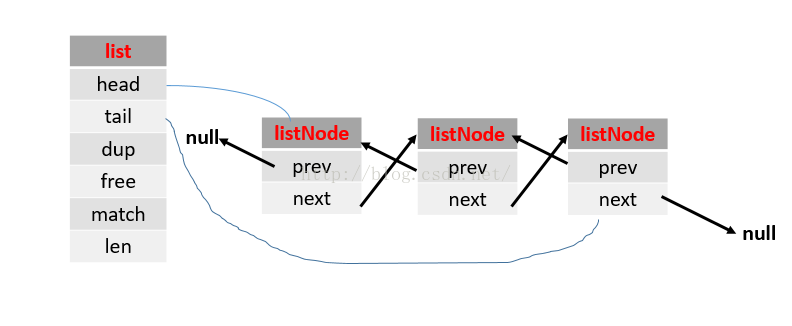
typedef struct listNode { /*节点*/
struct listNode *prev;
struct listNode *next;
void *value; /*value用函数指针类型,决定了value可以是sds,list,set,dict等类型*/
} listNode;
typedef struct list { /*链表结构*/
listNode *head; /*头节点*/
listNode *tail; /*尾节点*/
/*类似java类里的的方法,方便调用*/
void *(*dup)(void *ptr); /*复制节点*/ //说实话,我不是很懂这个函数指针的意思,如有清楚地可以给我留言,谢谢。
void (*free)(void *ptr); /*释放节点*/
int (*match)(void *ptr, void *key); /*匹配节点,返回key值得index,但是我不清楚他在那里实现的*/
unsigned long len; /*记录链表的长度*/
} list;
typedef struct listIter {
listNode *next;
int direction; //标注迭代器的运行方向
} listIter;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask; /*hash表的掩码,总是size-1,用于计算hash表的索引值*/
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;

typedef struct intset { /*整数集合的数据结构*/
uint32_t encoding; //编码方式
uint32_t length;
int8_t contents[];
} intset;
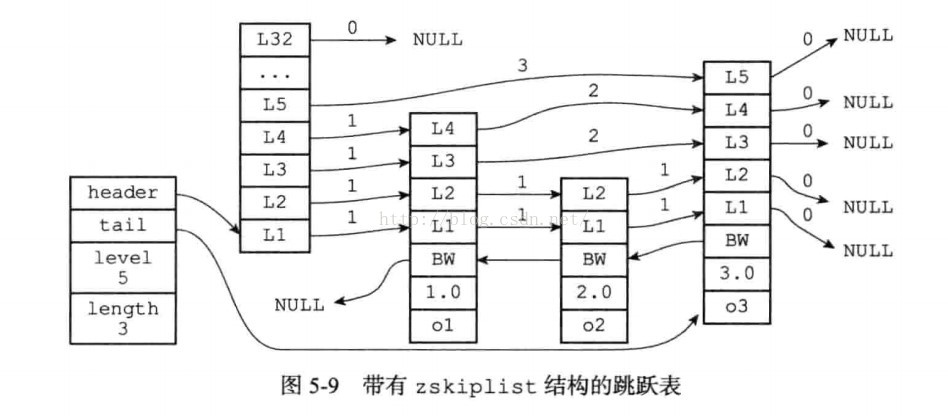
typedef struct zskiplistNode {
robj *obj; //存储对象的指针
double score; //分数
struct zskiplistNode *backward; //后退指针,每次只能退一步
struct zskiplistLevel {
struct zskiplistNode *forward; //前进指针,每次可以跳跃好几步
unsigned int span; //这个就是决定前进指针能跳跃几步的跨度标志
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
typedef struct zlentry {
//prevrawlen为上一个数据结点的长度,prevrawlensize为记录该长度数值所需要的字节数
unsigned int prevrawlensize, prevrawlen;
//len为当前数据结点的长度,lensize表示表示当前长度表示所需的字节数
unsigned int lensize, len;
//数据结点的头部信息长度的字节数
unsigned int headersize;
//编码的方式
unsigned char encoding;
//数据结点的数据(已包含头部等信息),以字符串形式保存
unsigned char *p;
} zlentry;


参考书籍:《Redis设计与实现》
特此声明:本文非本人所原创,是转载他人文章并总结整合方便自己学习的笔记!!!