数据库基础
一、数据库简介
数据库:存放数据的仓库
sql及其规范
sql是Structured Query Language(结构化查询语言)的缩写。SQL是专为数据库而建立的操作命令集,是一种功能齐全的数据库语言。
在使用它时,只需要发出“做什么”的命令,“怎么做”是不用使用者考虑的。SQL功能强大、简单易学、使用方便,已经成为了数据库操作的基础,并且现在几乎所有的数据库均支持sql。
<1> 在数据库系统中,SQL语句不区分大小写(建议用大写) 。但字符串常量区分大小写。建议命令大写,表名库名小写; <2> SQL语句可单行或多行书写,以“;”结尾。关键词不能跨多行或简写。 <3> 用空格和缩进来提高语句的可读性。子句通常位于独立行,便于编辑,提高可读性。 SELECT * FROM tb_table WHERE NAME="YUAN"; <4> 注释:单行注释:-- 多行注释:/*......*/ <5>sql语句可以折行操作 <6> DDL,DML和DCL
MYSQL常用命令
--
-- 启动mysql服务与停止mysql服务命令:
--
-- net start mysql
-- net stop mysql
--
--
-- 登陆与退出命令:
--
-- mysql -h 服务器IP -P 端口号 -u 用户名 -p 密码 --prompt 命令提示符 --delimiter 指定分隔符
-- mysql -h 127.0.0.1 -P 3306 -uroot -p123
-- quit------exit----\q;
--
--
-- \s; ------my.ini文件:[mysql] default-character-set=gbk [mysqld] character-set-server=gbk
--
-- prompt 命令提示符(\D:当前日期 \d:当前数据库 \u:当前用户)
--
-- \T(开始日志) \t(结束日志)
--
-- show warnings;
--
-- help() ? \h
--
-- \G;
--
-- select now();
-- select version();
-- select user;
--
-- \c 取消命令
--
-- delimiter 指定分隔符
二、.数据库操作(DDL)
1.查看:
(1)查看所有数据库:show databases;
(2)查看某一数据库创建编码:show create database num;
2.创建:
create database if not exists sxmu; (如果不存在则创建,若存在不创建也不报错,但会warning.查看warning:show warnings;)
create database if not exists num character set gbk;
3.删除:drop database if exists kokusho;
4.修改:alter database num character set gbk;
5 使用:切换:use sxmu;
检测当前数据库:select database();
注:数据库文件默认存放路径(C:\ProgramData\MySQL\MySQL Server 5.7\Data)
默认创建的所有数据库都是一个文件夹,每一张表都是该文件夹下的一个文件。
故如果要迁移数据库文件,可直接复制数据库文件夹
select user();
select now();
三、数据表操作
主键:非空且唯一(not null,unique)
数据类型:
数值类型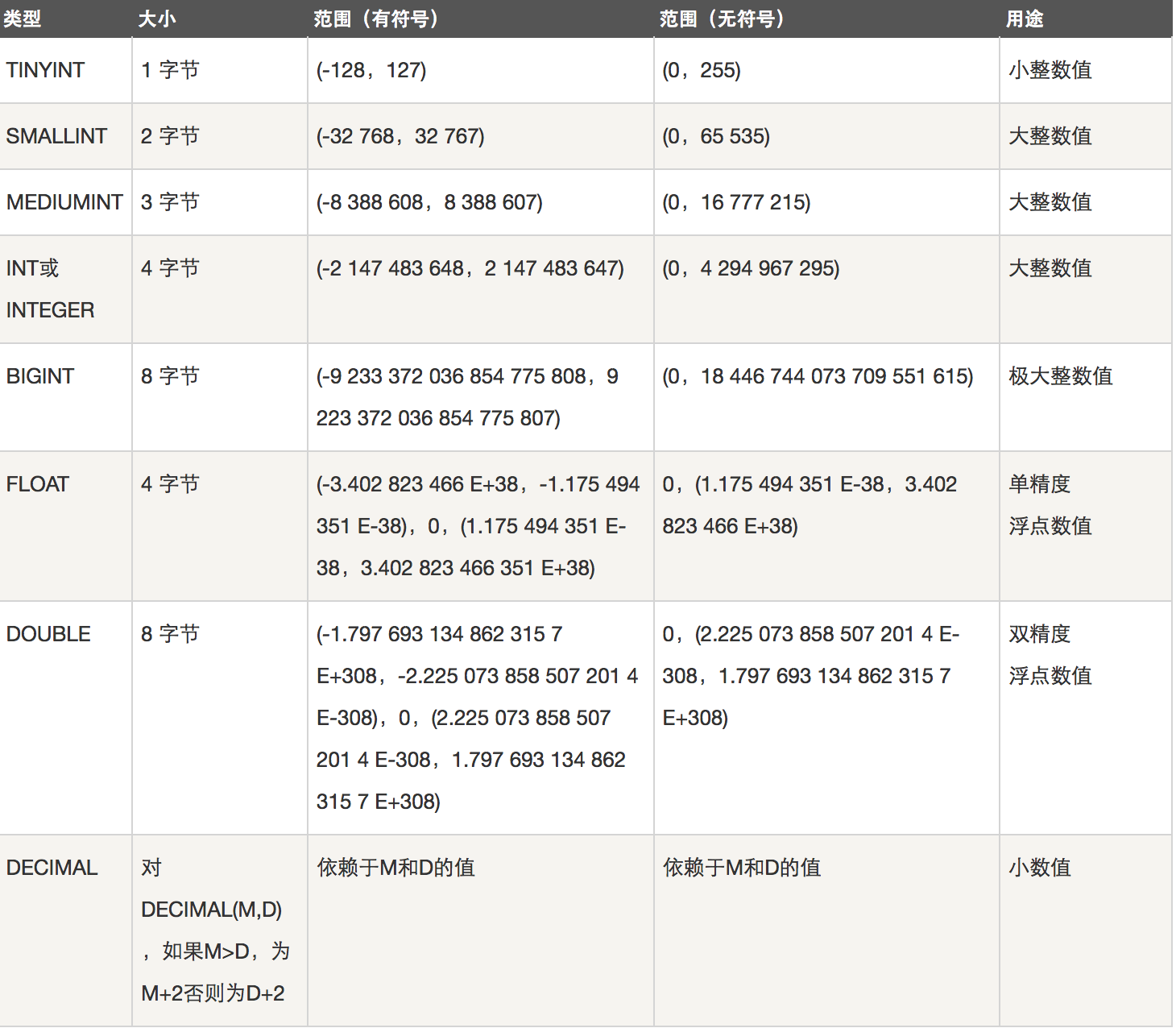
日期和时间类型
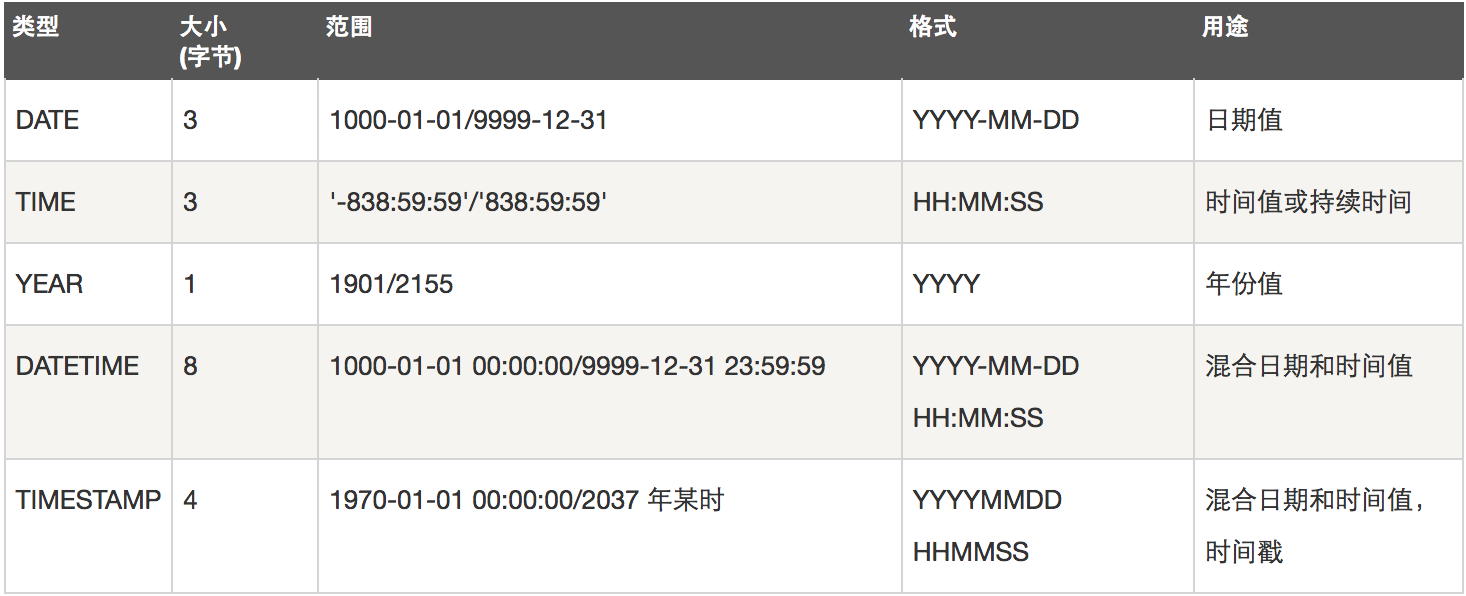
字符串类型
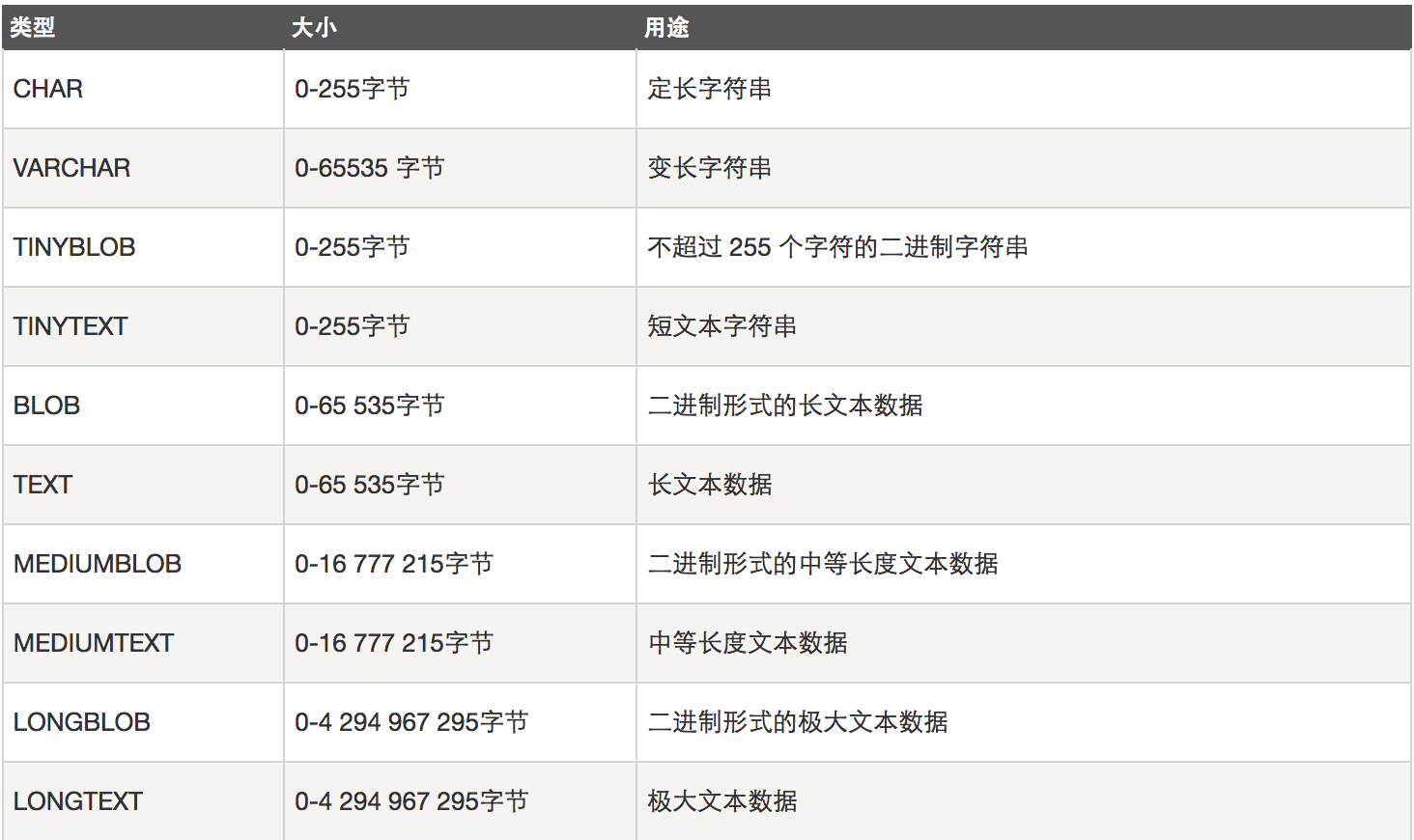
创建表:
create table tab_name(
field1 type[完整性约束条件],
field2 type,
...
fieldn type
)[character set xxx];
创建员工表:
CREATE TABLE employee(
id TINYINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(25),
gender BOOLEAN,
age INT,
department VARCHAR(20),
salary DOUBLE(7,2)
)
表结构:
1.查看
查看表结构:desc employee;
show columns from employee;
查看创建表语句:show create table employee;
查看当前数据库所有表:show tables;
2.增加字段:alter table employee add is_married tinyint(1);
alter table employee add entry_date date not null;
alter table employee add A int,add b varchar(20);
3.删除字段:alter table employee drop A;
alter table employee drop b,drop entry_date;
删除表:drop table emp;
4.修改字段信息:alter table employee modify age smallint not null default 18 after name;
alter table employee change department depart varchar(20) after salary;
修改表名: rename table employee to emp;
修改表所用字符集: alter table student character set utf8;
四、表记录操作
插入:/*insert [into] tab_name (field1,filed2,.......) values (value1,value2,.......);*/ insert into emp (id,age,name,gender,salary,depart,is_married) values(1,18,'alex',0,1700,'技术部',1); INSERT INTO emp(name,salary,depart) VALUES ('瞎驴',30000,'python'); INSERT INTO emp(name,salary,depart) VALUES ('xialv',30000,'python'), ('小雨',5000,'销售部'), ('冰冰',9000,'销售部'); insert emp set name='珊珊'; insert into emp values(10,'丹丹',29,0,3000,'销售部',1); INSERT INTO emp(name,salary,depart) VALUES ('yuan',30000,'python'); 修改:UPDATE emp SET salary=salary+20000 WHERE name='yuan'; UPDATE emp SET salary=salary+20000,depart='保安部' WHERE name='xialv'; 删除:DELETE FROM emp WHERE id=11 OR id=2; delete from emp; (删除表内容) truncate table emp; (先直接删除整个表,在创建一个相同表结构的空表。大量数据时使用,直接删除表速度快。) ---准备表数据 CREATE TABLE ExamResult( id INT PRIMARY KEY auto_increment, name VARCHAR (20), JS DOUBLE , Django DOUBLE , OpenStack DOUBLE ); insert into examresult(name) value('周守成'); INSERT INTO ExamResult VALUES (1,"yuan",98,98,98), (2,"xialv",35,98,67), (3,"alex",59,59,62), (4,"wusir",88,89,82), (5,"alvin",88,98,67), (6,"yuan",86,100,55); 查询:select [distinct] *|filed1,field2| [as 别名]|[别名] from tab_name; 练习:select * from examresult; select name,JS,Django,flask from examresult; select name 姓名,JS+10 as JS,Django+10 as Django,flask+10 as flask from examresult; select distinct name from examresult; //去重 (1)where:where字句中可使用[比较运算符:< > <= >= <> !=,between and,in,like,逻辑运算符:and or not] 练习:select name,JS+Django+flask as 总成绩 from examresult where JS+flask+Django>200; select name,JS from examresult where JS!=80; select name,JS from examresult where JS between 90 and 100; select name,JS from examresult where JS in(88,99,77); select name,JS from examresult where name like 'y%'; // %: 任意多个字符 select name,JS from examresult where name like 'y_'; // _:一个字符 select name,JS from examresult where name='yuan' and JS>80; select name from examresult where JS is null; //空考的学生 (2)order by 指定排序的列(排序的列可以使表中的列名,也可以是select语句中的别名) --asc为升序,desc为降序,默认为asc,order by应为于select语句的结尾 select name,JS from examresult order by JS; select name,JS from examresult where JS between 70 and 100 order by JS; //默认升序 select name,JS from examresult where JS between 70 and 100 order by JS desc; //降序 select name,JS+Django+flask as 总成绩 from examresult order by 总成绩 desc; select name,JS+Django+flask as 总成绩 from examresult where name='yuan' order by 总成绩 desc; 注:select JS as JS总成绩 from examresult where JS总成绩>70; 这条语句不能正确执行 select语句的执行顺序:from 表名 -> where -> select ->......->order by (3)group by:分组查询 --常和聚合函数配合使用 注:-- 按分组条件分组后每一组只会显示第一条记录 -- group by字句,其后可以接多个列名,也可以跟having子句,对group by 的结果进行筛选。 按列名分组 select * from examresult group by name; 按位置字段分组 select * from examresult group by 2; 将成绩表按名字分组后,显示每一组JS成绩的分数总和 select name,sum(JS) from examresult group by name; 将成绩表按照名字分组后,显示每一类名字的Django的分数总和>150的类名字和Django总分 select name,sum(Django) from examresult group by name having sum(Django)>150; 查询每个部门中男性和女性的人数 select depart,gender,count(id) from emp group by depart,gender; having 和 where两者都可以对查询结果进行进一步的过滤,差别有: <1>where语句只能用在分组之前的筛选,having可以用在分组之后的筛选; <2>使用where语句的地方都可以用having进行替换 <3>having中可以用聚合函数,where中就不行。 (4)聚合函数:[count,sum,avg,max,min]--常和分组函数配合使用 --统计JS>70的人数 select count(id) from examresult where JS>70; --统计JS的平均分 select sum(JS)/count(name) from examresult; //算上了JS为null的情况 select avg(JS) from examresult; //不算JS为null -- 统计总分大于280的人数有多少? select count(name) from ExamResult where (ifnull(JS,0)+ifnull(Django,0)+ifnull(OpenStack,0))>280; --查询JS总分中最小值 select min(JS) from examresult; select min(ifnull(JS,0)) from examresult; --查询JS+Django+flask总分中最大的 select max(JS+Django+flask) from examresult; (5)limit: select * from examresult limit 3;显示前3条 select * from examresult limit 2,3; //跳过前两条显示接下来的3条 (6)重点: --sql语句书写顺序:select from where group by having order by --sql语句执行顺序:from where select group by having order by 例子: select JS as JS成绩 from examresult where JS成绩>70; //执行不成功 select JS as JS成绩 from examresult where JS成绩>70; //成功执行 (7)使用正则表达式查询 SELECT * FROM employee WHERE name REGEXP '^yu'; SELECT * FROM employee WHERE name REGEXP 'yun$'; SELECT * FROM employee WHERE name REGEXP 'm{2}';
五、外键约束
创建外键
--- 每一个班主任会对应多个学生 , 而每个学生只能对应一个班主任
--1.数据准备:
----主表
CREATE TABLE ClassCharger(
id TINYINT PRIMARY KEY auto_increment,
name VARCHAR (20),
age INT ,
is_marriged boolean -- show create table ClassCharger: tinyint(1)
);
INSERT INTO ClassCharger (name,age,is_marriged) VALUES ("冰冰",12,0),
("丹丹",14,0),
("歪歪",22,0),
("姗姗",20,0),
("小雨",21,0);
----子表
CREATE TABLE Student(
id INT PRIMARY KEY auto_increment,
name VARCHAR (20),
charger_id TINYINT,
foreign key (charger_id) references classcharger(id) on delete cascade
) ENGINE=INNODB;
--切记:作为外键一定要和关联主键的数据类型保持一致
-- [ADD CONSTRAINT charger_fk_stu]FOREIGN KEY (charger_id) REFERENCES ClassCharger(id)
INSERT INTO Student2(name,charger_id) VALUES ("alvin1",2),
("alvin2",4),
("alvin3",1),
("alvin4",3),
("alvin5",5),
("alvin6",3),
("alvin7",3);
--2.外键约束练习
删除班主任丹丹
delete from classcharger where id=2; --会报错
先删除班主任丹丹关联的学生
update student set charger_id=4 where id=1 or id=7;
delete from classcharger where id=2; --成功执行
添加一个学生,班主任选择丹丹
insert into student(name,charger_id) values('sasa',2); --添加失败
-----------增加外键和删除外键---------
ALTER TABLE student ADD CONSTRAINT abc
FOREIGN KEY(charger_id)
REFERENCES classcharger(id);
ALTER TABLE student DROP FOREIGN KEY abc;
alter table student3 drop foreign key student3_ibfk_1;
alter table student3 add constraint s3_fk_c foreign key(charger_id) references C(id) on delete set null;
3.INNODB支持的on语句
--外键约束对子表的含义: 如果在父表中找不到候选键,则不允许在子表上进行insert/update
--外键约束对父表的含义: 在父表上进行update/delete以更新或删除在子表中有一条或多条对
-- 应匹配行的候选键时,父表的行为取决于:在定义子表的外键时指定的
-- on update/on delete子句
-----------------innodb支持的四种方式---------------------------------------
-----cascade方式 在父表上update/delete记录时,同步update/delete掉子表的匹配记录
-----外键的级联删除:如果父表中的记录被删除,则子表中对应的记录自动被删除--------
FOREIGN KEY (charger_id) REFERENCES ClassCharger(id)
ON DELETE CASCADE
------set null方式 在父表上update/delete记录时,将子表上匹配记录的列设为null
-- 要注意子表的外键列不能为not null
FOREIGN KEY (charger_id) REFERENCES ClassCharger(id)
ON DELETE SET NULL
------Restrict方式 :拒绝对父表进行删除更新操作(了解)
------No action方式 在mysql中同Restrict,如果子表中有匹配的记录,则不允许对父表对应候选键
-- 进行update/delete操作(了解)