线性模型的基本形式
给定d个特征值的示例x=(x1,x2,x3.....xd),xi是x在第i个属性上的取值。线性模型试图通过属性的线性组合来进行预测的函数,其形式为
f(x)=w1x1+w2x2+w3x3+...+wdxd
向量形式为f(x)=w^T*X+b
线性模型简单易建模,体现了机器学习的重要思想,具有诸多优点。
其思维导图如下:
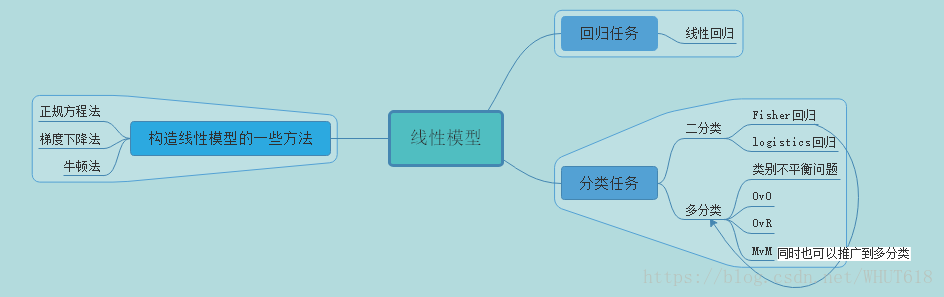
今日学习 主要有回归任务和分类任务。
1.线性回归
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。线性回归中的数据呈现线性关系,其表达形式为y = w(T)x+b。其中w为系数向量组,x为特征值向量组,b为常值系数。
我们通常将数据集分为训练集和测试集,使用训练集来确定待定系数,测试集来测试误差,通过代价函数进行优化。
- 训练模型的一些方法:正规方程法,梯度下降法等。
- 测试模型的一些方法:留出法,交叉验证法,自助法等。
在另一篇文章里有使用c++的实现。
2.logistic回归
logistics回归虽然叫回归,但其实是一个二分类算法,用来处理分类任务。
我们通过找一个单调可微函数将分类任务与线性回归模型结合起来。
在二分类中,输出标记y属于0或1,而线性回归模型产生的预测值z=w^T+b是一个实值,所以我们需要进行一个转换,使得实值z为0/1。
于是我们找到了一个单调可微的单位跃阶函数的替代函数
y=1/(1+e^-z) ,
它也就是对数几率函数(logistic fiction),其中z=w^T*x+b.
该函数的值正好是[0,1],我们可以通过y>0.5时y值认为1,y<0.5时为0,等于0.5时随机为0/1。来达到分类的效果。
由于对数函数是任意阶可导的凸函数,我们可以使用梯度下降法以及牛顿法来求得全局最优解,并通过logistics函数对应的代价函数来确定分类的阙值。
3.线性判别分析
线性判别分析亦称Fisher判别分析,简称为LDA。
它的基本思想非常朴素:给定训练集,将训练集从高维度投影到低维度,使得同类样例的投影点尽可能接近,异类的投影点尽可能远离。
我们通常通过“类内散度矩阵”来控制类内距离,使其尽可能的小。而通过“类间散度矩阵”来控制类与类之间的距离,使其尽可能的大。
LDA还可以通过全局散度矩阵和以上两类矩阵相结合进行推广到多分类,还是一种经典的监督降维的方法。
4.多分类学习
在现实中,我们经常遇到多分类问题。我们可以利用二分类的分类器来解决多分类的问题,
其基本思路是“拆解法”,即将多分类任务拆解为若干个二分类任务求解。最为经典的拆分方式有:一对一(简称OvO),一对其余(简称OvR),多对多(简称MvM)。
- OvO:给定数据集D,yi属于{C1,C2.....CN},OvO将这N个类别两两相匹配,从而产生N(N-1)/2个二分类的任务,最终可将预测最多的类别作为预测结果。
- OvR:OvR将一个样例作为正例而其余全部作为反例的来训练N个分类器。测试时,若只有一个分类器预测为正例,则该类别的标记就作为分类结果。若有多个分类器预测为正类,则选取置信度最大的类别的标记作为分类结果。
- MvM:该方法每次将若干个作为正类,若干个其他类作为反类,我们通常通过”纠错输出码“(简称ECOC)来选取正反类。ECOC通常需要进行编码:将N个类别划分M次,每次划分将一部分划为正类,一部分反类,从而形成一个二分类训练集。这样可以训练出M个分类器。 编码之后还需要解码:M个分类器分别进行预测,这些预测标记形成一个编码,然后将预测编码和每个类别各自的编码进行比较,返回最小距离的类别为最终结果。(采用海明距离和欧式距离)。
5.类别不平衡问题
在现实生活中,我们很容易选取到正例和反例数量相差很大的样本数据集,这样训练出的学习器往往没有价值。这便是类别不平衡问题,,它指在分类任务中不同类别的训练样例数目有很大的差别的情况。
在线性分类器中,我们通常通过判断y/(1-y)是否大于1来预测是否为正例。当正反例数目不同,我们设m+为正例数目,m-为反例数目时,若y/(1-y)>(m+/m-),则为正例。
我们执行该不等式时,需令y`/(1-y`)=y/(1-y)*m-/m+ ,这就是不平衡学习的一个基本策略——”再缩放“。
---因为我们未必能通过基于训练集来推断出真实几率,所以再缩放的实操并不简单。现有技术大体上有三种做法:
- 欠采样法:去除一些反例使得正反例数目相近,然后再学习。其代表算法EasyEnsemble利用了集成学习机制,该算法避免了有可能去除重要信息的可能性。
- 过采样法:增加一些正例使得正反例数目相近,然后再学习。其代表算法SMOTE是通过对训练集例的正例进行插值来产生额外的正例。该算法很好的缓解了过拟合问题。
- 阙值移动法:基于原数据集进行学习,在用训练好的分类器进行预测时,将y`/(1-y`)=y/(1-y)*m-/m+ 嵌入其决策过程中。