一、问题现象
系统在双十一期间出现频繁内存飙升现象,内存在几天内直接飙升到报警阈值。在堆内存空间由3g调整到4g后,依然出现堆内存超过阈值问题,同时在重启若干次内存依然会飙升堆积。同时也发现了jvm一直不出现full gc,young gc稍微有点颤抖并出现young gc回收慢现象,很诡异,where is the full gc?!如图所示:
同时可以看到,young gc后,内存逐渐飙升,时快时慢,可以看到有时young gc回收不了多少空间,如图:
而cpu使用率也随着young gc事件的产生出现抖动,很不平稳,如图:
流量大时,最恐怖的是这样:
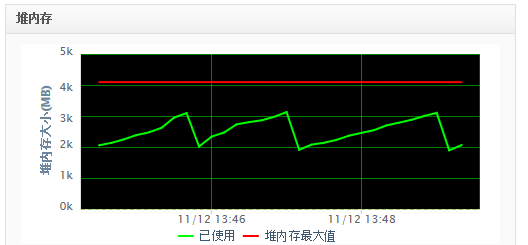
于是怀疑有内存泄露问题,dump了3g多的线上内存镜像,进行分析。同时也找了架构,给出的意见是更改触发full gc条件,降低tomcat线程数。
二、分析过程
怀疑内存泄露,于是使用工具分析dump文件,but….
分析使用工具:
分析过程中遇到了一个问题,由于MAT本身是eclipse的分支,众所周知eclipse是个java写的编译器,限制于jvm堆内存。3g多的dump文件导入MAT会直接把MAT的内存撑满,当时分析的时候忘记了可以直接改MAT的配置文件提升堆内存。于是找了个神奇的命令行工具-BHeapSampler,当然这货也是java写的,分析速度很快,生成报告也很直接,很给力!
当然后来就想起了MAT能够调整堆内存,这里先说明一下使用BHeapSampler,话说这东西在网上的文档挺少的,只能看着官方文档摸索学习。
执行命令java -jar -Xmx4g -Xms4g bheapsampler.jar ~/Desktop/jmap-20161114094315.bin
解释:~/Desktop/jmap-20161114094315.bin是我导出的dump文件, -Xmx4g和-Xms4g同样需要配置堆内存,3g多的dump文件给了4g做分析。
BHeapSampler会在bheapsampler.jar的目录下生成名为memory_paths.txt的分析报告文件,是内存对象的引用链。
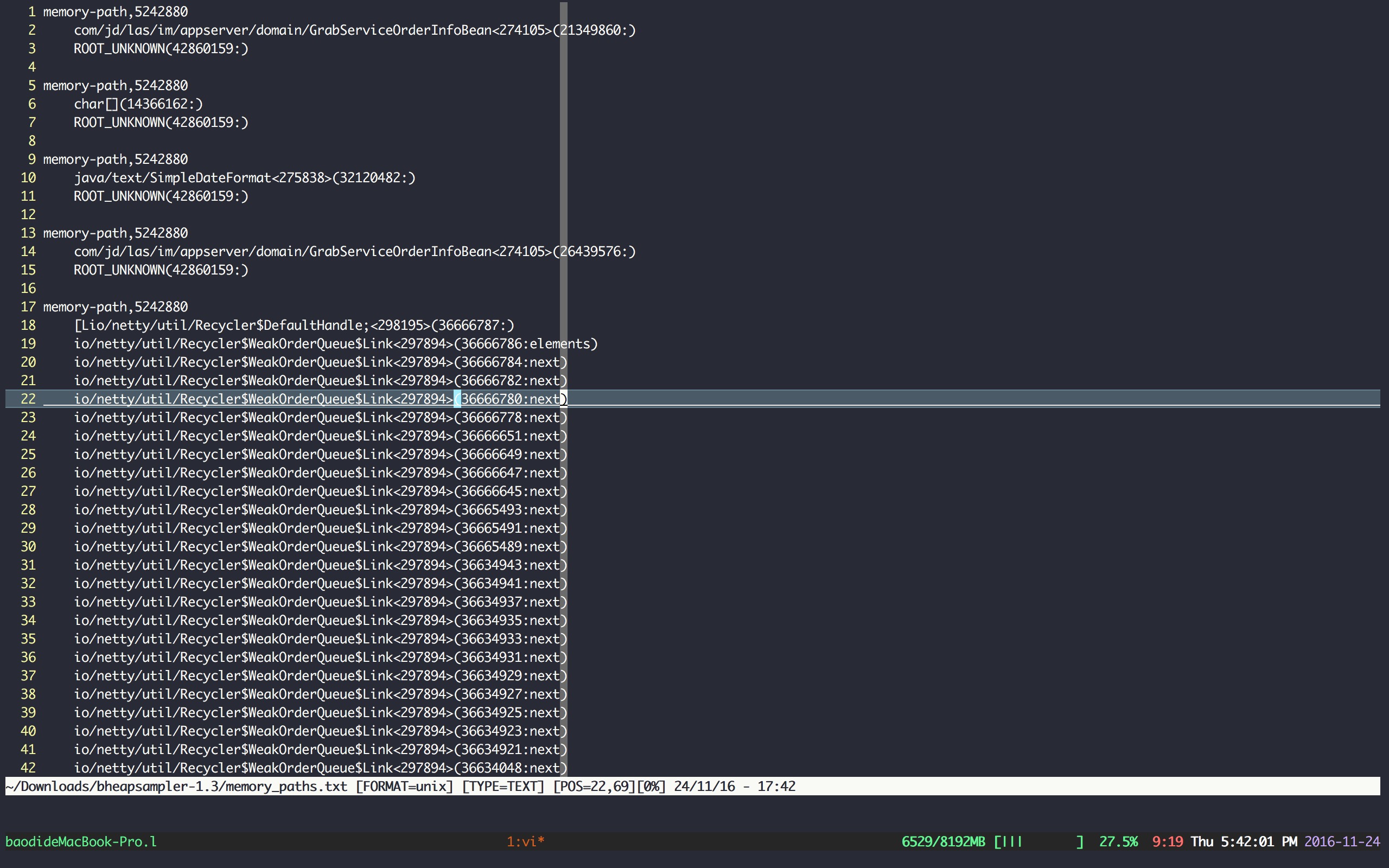
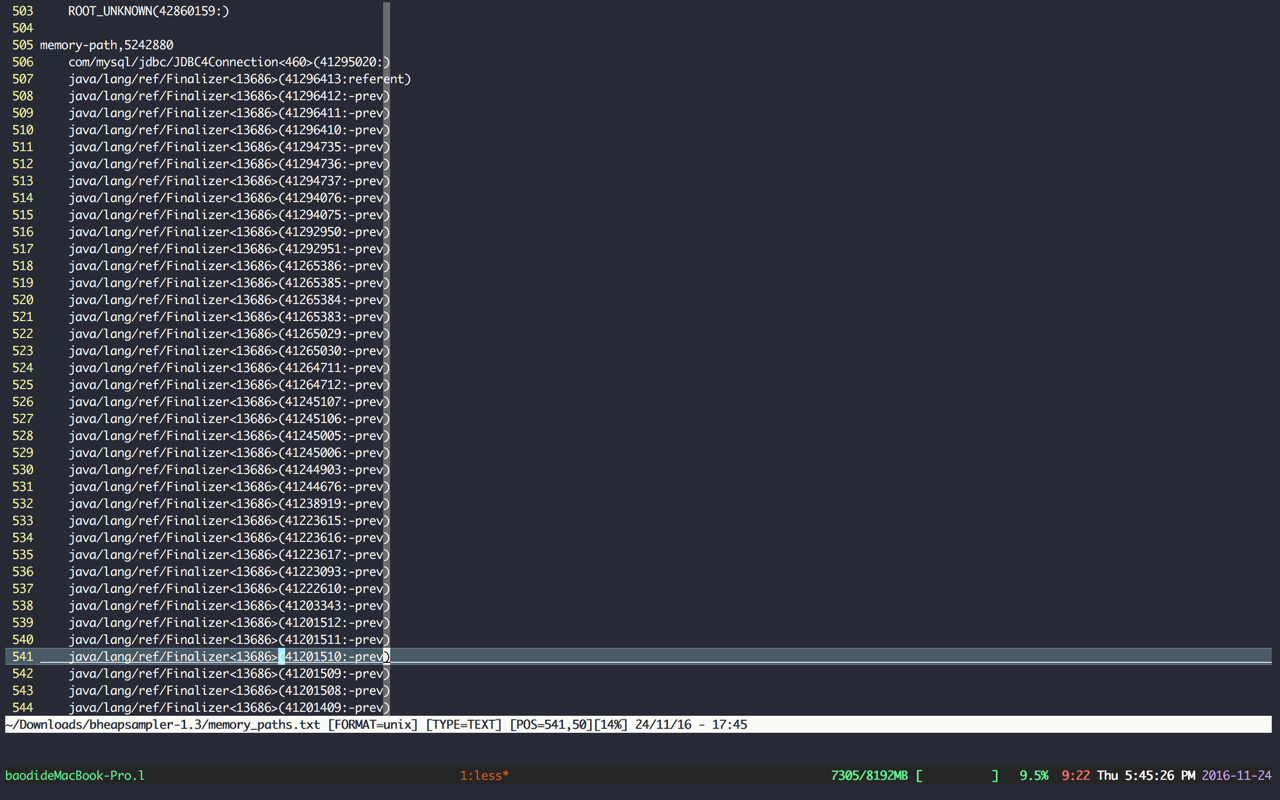
可以看到有大量的io/netty/util/Recycler
Link和com/mysql/jdbc/JDBC4Connection的java/lang/ref/Finalizer对象。
已知netty的Recycler中的WeakOrderQueue用于netty对大量连接产生的对象回收时进行缓存池化操作,下次再用到该对象时从池中取出,减少了过量创建对象和销毁对象产生的压力。
已知mysql的Connection/J中调用了finalize(),在finalize()方法中会调用cleanup()方法,该方法用于关闭connection连接。
查阅netty相关资料,在netty的github上找到了一个issue #4147,大致可以看出,netty实现的Recycler并不保证池的大小,也就是说有多少对象就往池中加入多少对象,从而可能撑满服务器。通过在jvm启动时加入-Dio.netty.recycler.maxCapacity.default=0参数来关闭Recycler池,前提:netty version>=4.0。所以可怀疑为内存泄露!
而对于Finalizer众所周知的是,它会将要回收的对象进行一次挽救,所谓的挽救就是finalize方法里面再对要回收的引用进行重新引用,finalize中的引用会加入ReferenceQueue中,再下次gc时检查ReferenceQueue中的对象是否依然存在引用,没有则进行回收。而Finalizer的垃圾回收线程级别非常低,在高并发情况下很难被gc到。仔细思考下Connection/J驱动中覆盖finalize方法的目的是释放连接,但导致了在并发高的情况下ReferenceQueue中大量引用没被回收。所以可怀疑为内存泄露!
但是上面分析来说,还是怀疑,或者说是我们的基本类库产生了一些我们可能不可探知的或不好调整的问题。其实如果控制好gc,有可能在业务对象空间中找回netty和jdbc产生的泄露。
后来想到了修改MAT的启动配置参数,接下来说明一下MAT的内存分析过程。打开MAT安装目录,下面会有一个MemoryAnalyzer.ini的配置文件。该配置文件完全是eclipse的配置文件格式,跟eclipse配置方式相同,下面是我的配置参数:
-startup
../Eclipse/plugins/org.eclipse.equinox.launcher_1.3.100.v20150511-1540.jar
–launcher.library
../Eclipse/plugins/org.eclipse.equinox.launcher.cocoa.macosx.x86_64_1.1.300.v20150602-1417
-vmargs
-Xmx5g
-Xmx5g
-Xms5g
-server
-Dorg.eclipse.swt.internal.carbon.smallFonts
-XstartOnFirstThread
注意引用部分的是这次要加的参数。参数说明:
-vmargs:后面的参数都是jvm参数啦
-Xmx5g:最大堆内存5g
-Xms5g:启动或最小堆内存为5g,最大最小配置相同防止抖动现象
-server:与tomcat的运行模式是相同的,C2级别的编译优化,同时在也使用了并发gc等特性
在配置完MAT的堆内存参数后,来看看MAT导入dump文件分析的结果:
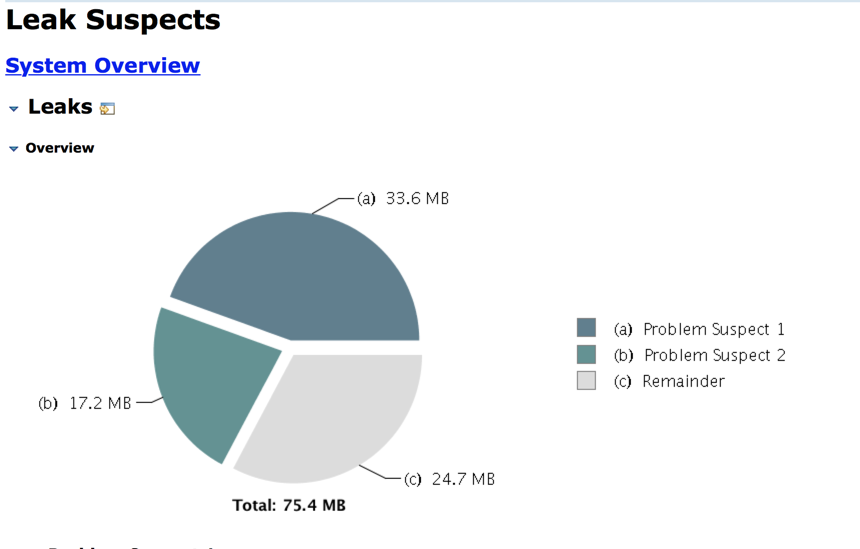
MAT分析疑似出现了Memory Leak。
其中33.6M的由WebappClassLoader中引用了一些HashMap
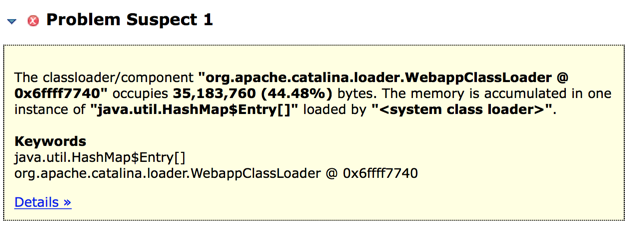
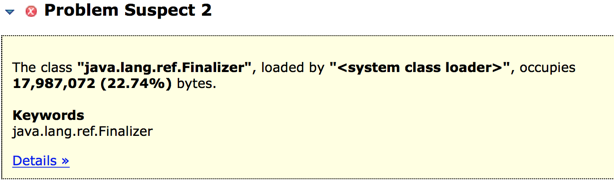
其中17.2M的由Finalizer产生
剩余24.7M的未知问题
Problem1:可以看到大量的JSF(京东的远程调用框架)调用和Work调用线程,其实这是正常的业务请求。
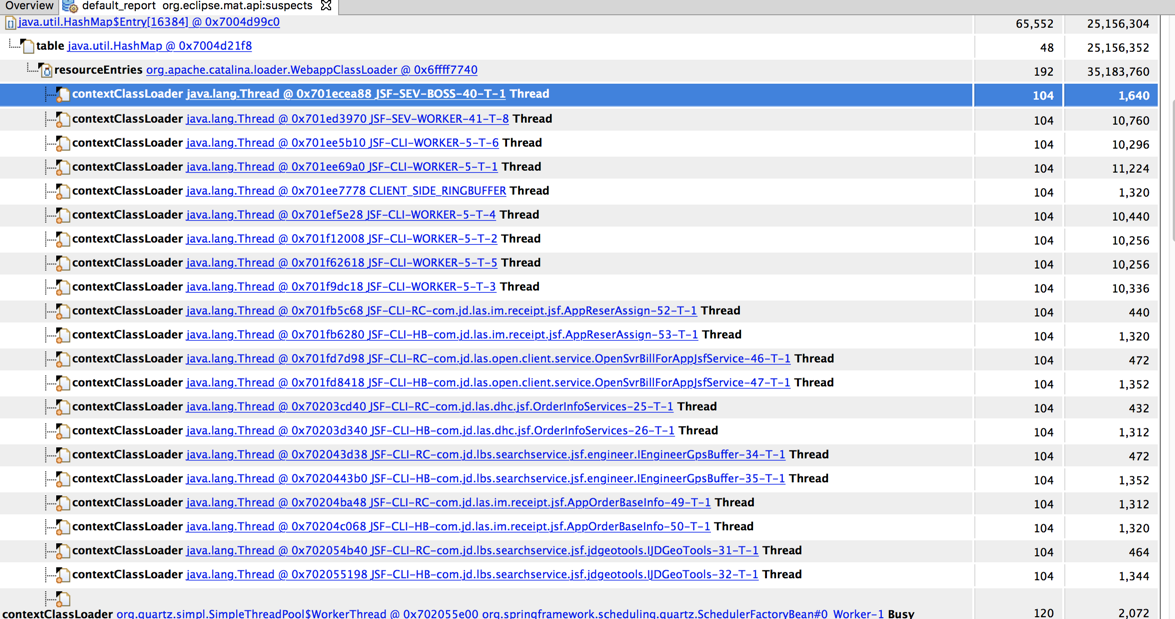
跟踪线程栈,可以看到netty的nio线程。根据BHeapSampler的分析,以及Recycler存在的对象多内存泄露问题,可以想到如果jsf调用多了产生对象比较大,确实会产生内存泄露问题。不过根据这次dump文件看到的jsf调用发现并不多。
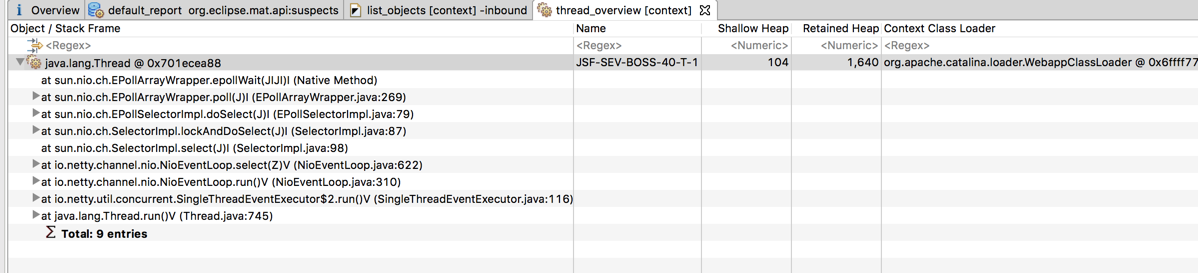
Problem2:下面两个图中可以看到在Finalizer队列中,都是jdbc的东西,与上面用BHeapSampler分析的结果相同,证明可能是Connection/J产生的问题。
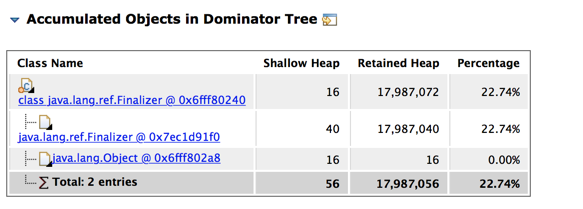
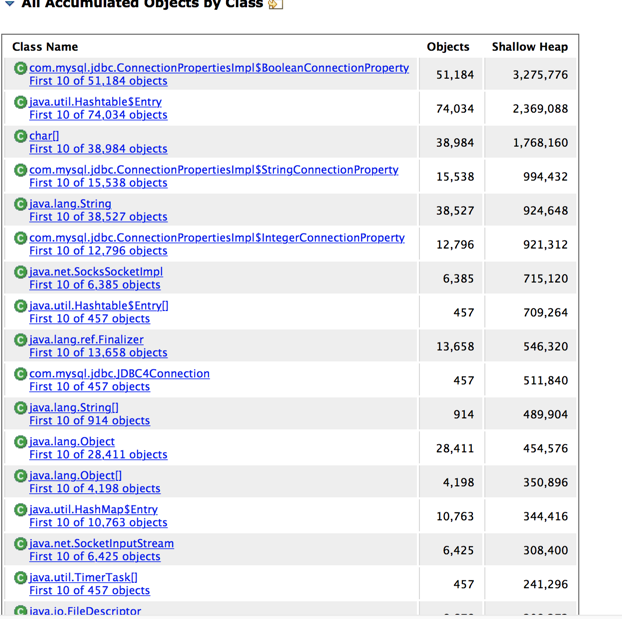
查看里面的深堆对象,可以看到成批的Finalizer,跟踪gc root引用如此恐怖,并且下面的深堆数量也非常多,更加可以确定Connection/J产生了很大问题。
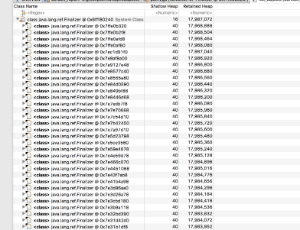
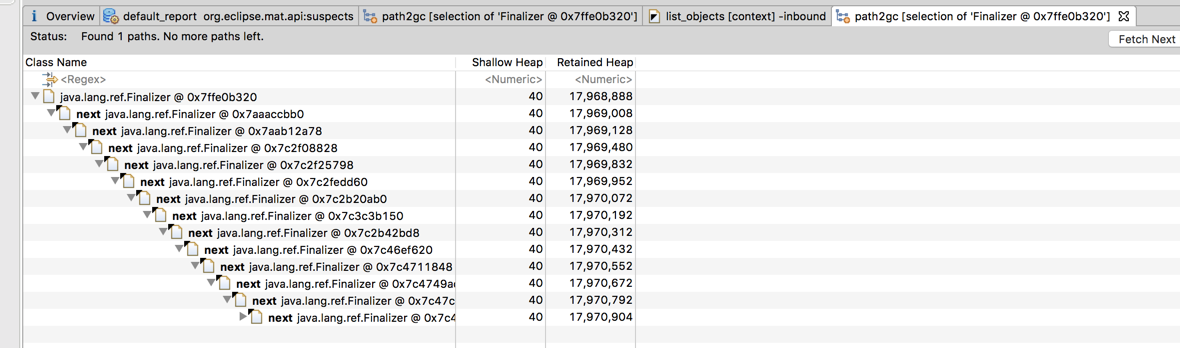
于是经过了上述过程的分析,so貌似得出了一个结论:业务代码没主动产生内存泄露,只是业务请求量造成大量的对象,netty和jdbc导致的一些基本问题…而对于我们能做的来说,其实就是gc和内存配置不太好 - -….

三、解决方案
解决方案就简单了,配置一下gc和堆内存好了,我们线上服务的默认:
Young GC(PS Scavenge)
Full GC(PS MarkSweep)
这就很尴尬了,为何不是cms或者g1?那就改下吧!于是gc参数:
-XX:+UseConcMarkSweepGC //开启cms gc
-XX:CMSInitiatingOccupancyFraction=80 //老年代占用80%时进行full gc
-XX:+UseCMSInitiatingOccupancyOnly //让cms gc老实一点,用我们的配置来工作
-XX:+CMSClassUnloadingEnabled // 永久代卸载类时进行cms gc操作
可以看到,产生堆满的原因除了gc策略有问题外,还有一种可能:堆空间的老年代和年轻代的占用比例不合适,而对于eden和survivor的比例也不合适,调整之:
-XX:SurvivorRatio=6 //survior占用比例
-XX:NewRatio=4 //年轻代占用比例
-XX:MaxDirectMemorySize=1024M //直接内存大小,这里我们的jsf使用了netty,存在零拷贝,所以最好配置下直接内存
-XX:MaxTenuringThreshold=12 //对象晋升老年代年龄
-XX:PretenureSizeThreshold=5242880 //配置5M的大对象直接进入老年代,做分配担保
同时为了节省内存,开启了逃逸分析和标量替换:
-XX:+DoEscapeAnalysis //开启逃逸分析
-XX:+EliminateAllocations //开启标量替换
整体配置:
-XX:SurvivorRatio=6
-XX:NewRatio=4
-XX:MaxDirectMemorySize=1024M
-XX:MaxTenuringThreshold=12
-XX:PretenureSizeThreshold=5242880
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=80
-XX:+UseCMSInitiatingOccupancyOnly
-XX:+CMSClassUnloadingEnabled
-XX:+DoEscapeAnalysis
-XX:+EliminateAllocations
注意这里没有配置-XX:+CMSParallelRemarkEnabled ,要是发现cms gc有卡顿延迟可以开启。另外对于我们的jsf使用了netty,应该注意:
千万不要开启-XX:+DisableExplicitGC!千万不要开启-XX:+DisableExplicitGC!千万不要开启-XX:+DisableExplicitGC!(重要的事情说三遍) 因为netty要做System.gc()操作,而System.gc()会对直接内存进行一次标记回收,如果通过DisableExplicitGC禁用了,会导致netty产生的对象爆满,boom shakalaka~
而-Dio.netty.recycler.maxCapacity.default=0参数上文只是提起了,并没有最后加入虚拟机参数中,因为刚接手该项目时间不长,不确定因素很多,在排查netty的Recycler的问题时看到项目pom.xml中有单独引用netty包,怀疑是可能项目中除jsf之外另外使用了netty,不敢对其做太大变动。所以该参数需要等熟悉一段项目后再考虑是否加入。目前只使用了基本的jvm参数优化jvm。
接下来提交给架构师审核了下,基本没什么问题,于是提交到运维实施。
四、后续结果(持续观察中)
后续结果还不错,直接上图不解释:
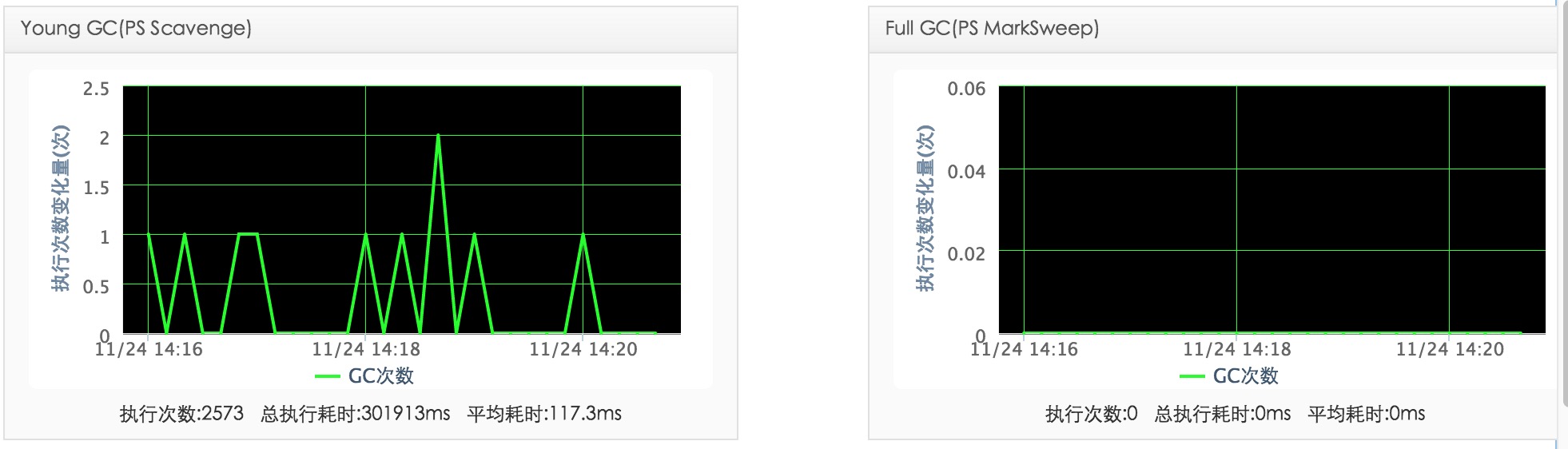
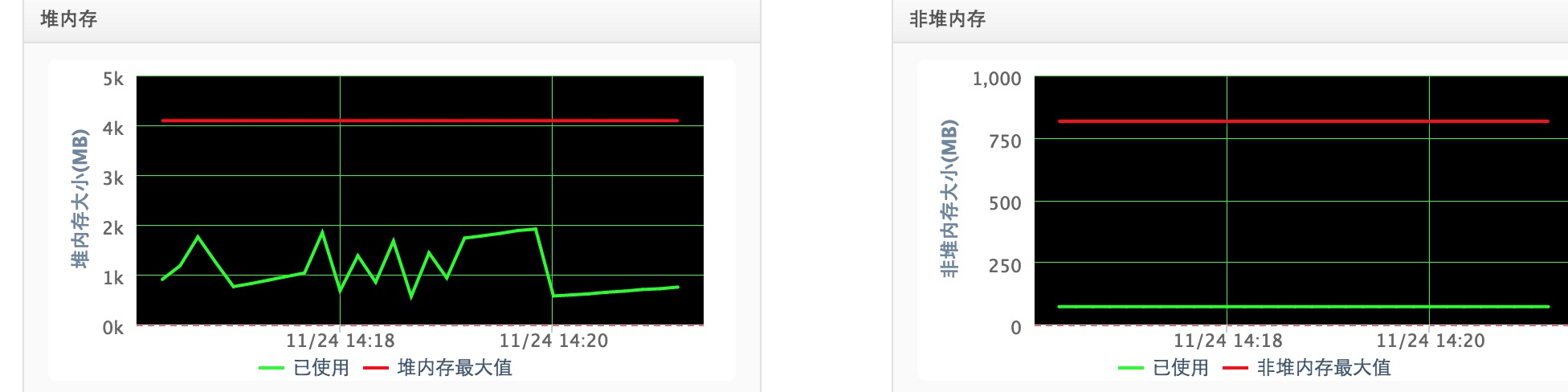
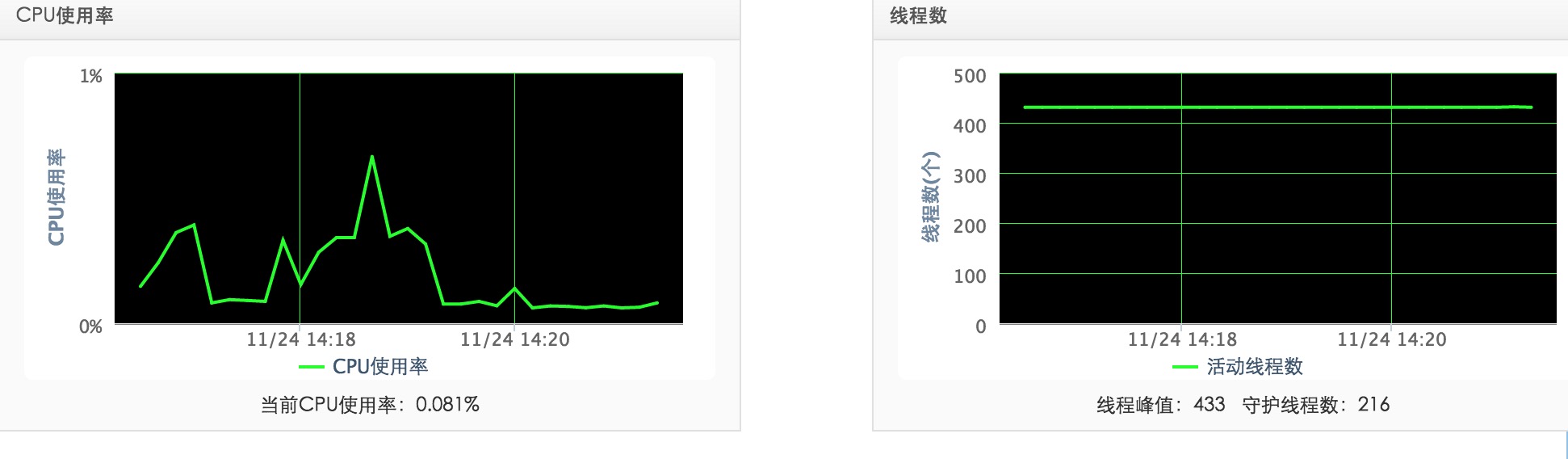
FULL GC(我们有了full gc!!!):
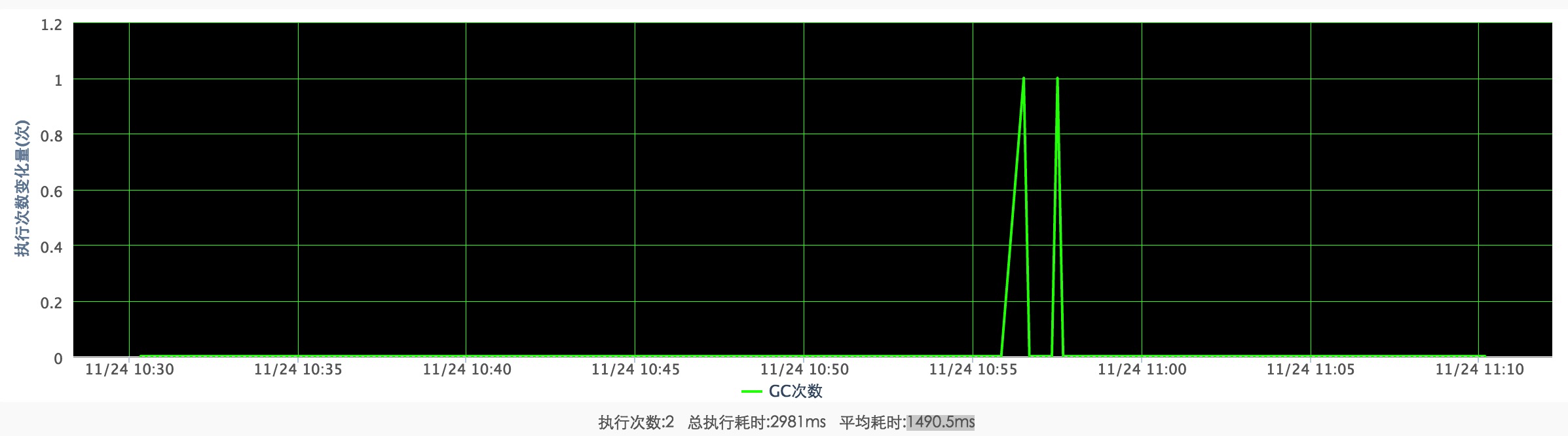
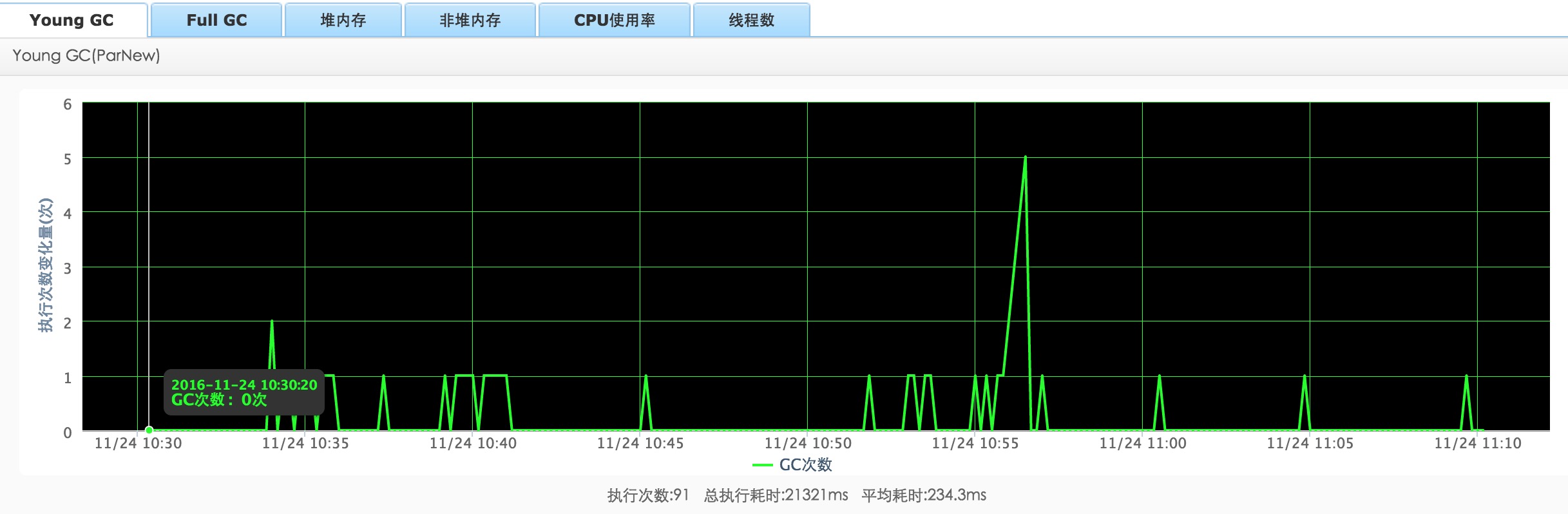
YOUNG GC:
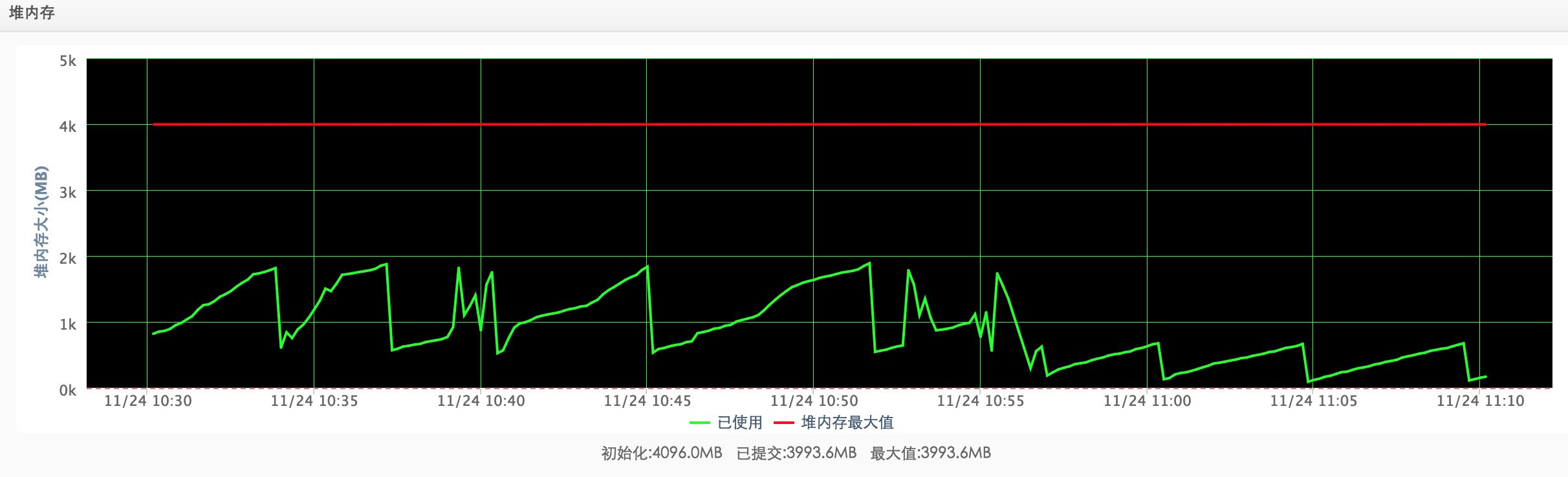
HEAP:
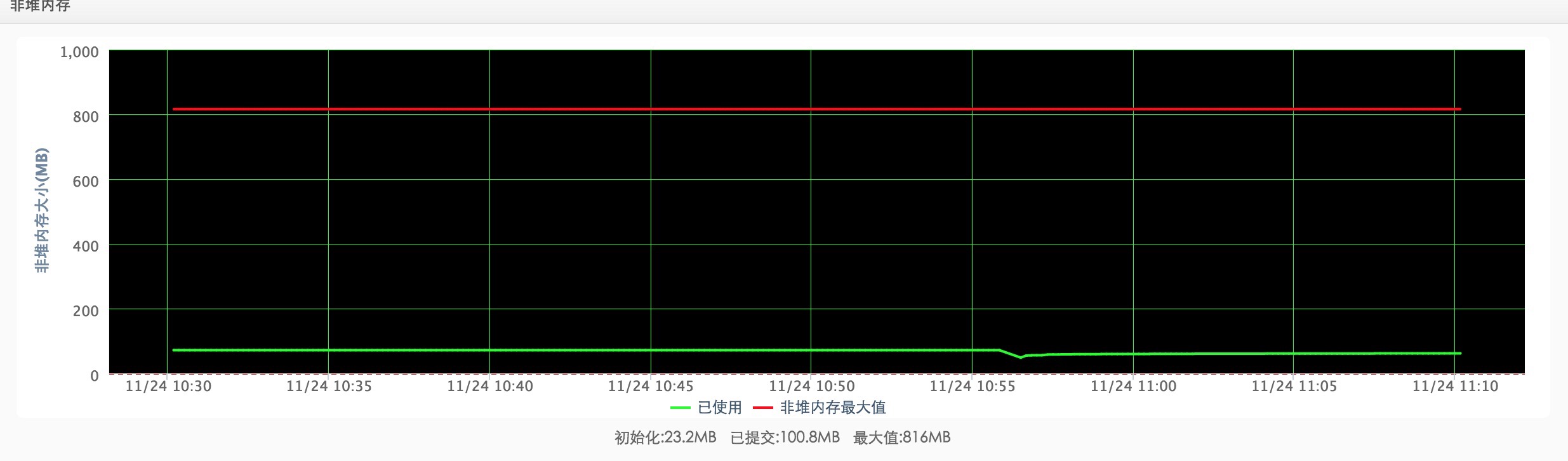
PERM:
五、总结
jvm优化的过程任重而道远,项目优化过程同样任重而道远。线上出现问题不怕,怕的是不出现问题,遇到问题才是好的,冷静分析解决之,这就是进步的过程,人需要进步,项目亦需要进步。平时编写代码严谨,尽量自测、互测,进行压测,可以使用Chaos Monkey法则和Force Bot方法。jvm优化并不复杂,也不高深,推荐阅读《深入理解jvm虚拟机》和 《Java程序性能优化》,前者理论比较强,是理解java底层的必备,后者实践操作比较强,涵盖了jvm优化、故障分析、代码质量优化等很多内容。本次jvm调优经历也是我对这两本书的最佳实践,给自己带来很多感触,在优化后看着内存稳定、gc合理回收、cpu也稳定了还是蛮有成就感的~特此写在wiki上,希望大家遇到了这样的问题能有所参考。