Spark总结

Spark 集中运行的模式

概述
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
Spark 提供了三种部署方式分别是: Standalone(独立模式), Mesos(使用模式), Yarn(Yarn模式)Spark默认的是Standalone(独立模式)。Spark之所以能做实时的计算愿意在于有低延迟的执行引擎(相应的时间大约为:100ms+),相比于Record的处理的框架(Strom),RDD在数据采集能做高效率的容错的处理。
集群环境搭建
安装包下载:链接:http://pan.baidu.com/s/1kVKzVKj 密码:6k5g 如果无法下载请联系作者,或:http://www.apache.org/dyn/closer.lua/spark/spark-1.5.2/spark-1.5.2-bin-hadoop2.6.tgz
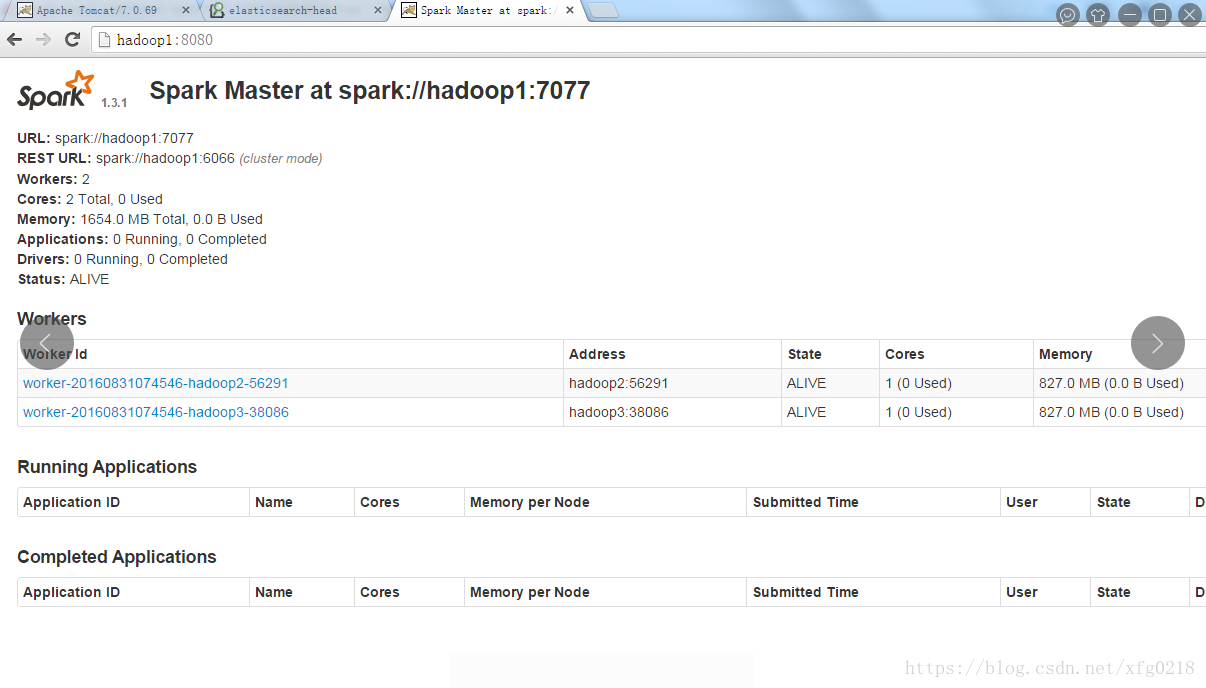
单机版配置spark集群
[root@hadoop1 local]# tar -zxvf spark-1.3.1-bin-hadoop2.6.tgz
[root@hadoop1 local]# cd spark-1.3.1-bin-hadoop2.6/
[root@hadoop1 local]# vi /etc/profile
加入以下配置:
export SPARK_HOME=/usr/local/spark-1.3.1-bin-hadoop2.6
[root@hadoop1 local]# source /etc/profile
[root@hadoop1 spark-1.3.1-bin-hadoop2.6]# cd conf/
[root@hadoop1 conf]# cp spark-env.sh.template spark-env.sh.template_back
[root@hadoop1 conf]# mv spark-env.sh.template spark-env.sh
[root@hadoop1 conf]# vi spark-env.sh
加入以下参数:
export JAVA_HOME=/home/jdk1.7
export SPARK_MASTER_IP=hadoop1
export SPARK_MASTER_PORT=7077
[root@hadoop1 conf]# cp slaves.template slaves
[root@hadoop1 conf]# vi slaves
hadoop2
hadoop3
[root@hadoop1 local]# scp -r spark-1.3.1-bin-hadoop2.6/ hadoop2:$PWD
[root@hadoop1 local]# scp -r spark-1.3.1-bin-hadoop2.6/ hadoop3:$PWD
[root@hadoop1 /]# cd usr/local/spark-1.3.1-bin-hadoop2.6/sbin/
[root@hadoop1 sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark-1.3.1-bin-hadoop2.6/sbin/../logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop1.out
hadoop2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.3.1-bin-hadoop2.6/sbin/../logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop2.out
hadoop3: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.3.1-bin-hadoop2.6/sbin/../logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop3.out
[root@hadoop1 sbin]# jps
8784 Master
8880 Jps
[root@hadoop2 /]# jps
6421 Worker
6477 Jps
[root@hadoop3 /]# jps
5999 Worker
http://hadoop1:8080/
集群版搭建
Zookeeper 能正常启动
[root@hadoop1 sbin]# ./stop-all.sh
A)、修改配置文件
[root@hadoop1 conf]# vi spark-env.sh
替换成一下信息:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=hadoop1:2181,hadoop2:2181,hadoop3:2181
-Dspark.deploy.zookeeper.dir=/spark"
B)、修改slaves
[root@hadoop1 conf]# vi slaves
# A Spark Worker will be started on each of the machines listed below.
hadoop3
[root@hadoop1 conf]# scp spark-env.sh hadoop2:/usr/local/spark-1.3.1-bin-hadoop2.6/conf/
[root@hadoop1 conf]# scp spark-env.sh hadoop3:/usr/local/spark-1.3.1-bin-hadoop2.6/conf/
[root@hadoop1 conf]# scp slaves hadoop2:/usr/local/spark-1.3.1-bin-hadoop2.6/conf/
[root@hadoop1 conf]# scp slaves hadoop3:/usr/local/spark-1.3.1-bin-hadoop2.6/conf/
[root@hadoop1 sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop1.out
hadoop3: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop3.out
[root@hadoop2 sbin]# ./start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop2.out
[root@hadoop1 sbin]# jps
13946 Master
3101 QuorumPeerMain
14112 Jps
[root@hadoop2 logs]# jps
9839 Master
9963 Jps
2668 QuorumPeerMain
[root@hadoop3 logs]# jps
8225 Jps
8105 Worker
2943 QuorumPeerMain
在Status 刚启动时会出现RECOVERING(恢复)状态,是在回复之前的状态以及数据。
[root@hadoop1 start_sh]# cat spark_start.sh
echo "######## hadoop--master 以及hadoop3 workers ###################"
# 启动hadoop--master 以及hadoop3 workers
cd /usr/local/spark/sbin
./start-all.sh
echo "######################## hadoop2-master #########################"
# 启动hadoop2--master
ssh hadoop2 "cd /usr/local/spark/sbin;./start-master.sh"
运行实例
1-1)、启动程序
启动多个master
[root@hadoop1 bin]#./spark-shell --master spark://hadoop1:7077,hadoop2:7077 --executor-memory 512m --total-executor-cores 7
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
16/10/02 19:55:37 INFO SecurityManager: Changing view acls to: root
16/10/02 19:55:37 INFO SecurityManager: Changing modify acls to: root
16/10/02 19:55:37 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
16/10/02 19:55:37 INFO HttpServer: Starting HTTP Server
16/10/02 19:55:40 INFO Server: jetty-8.y.z-SNAPSHOT
16/10/02 19:55:40 INFO AbstractConnector: Started [email protected]:38364
16/10/02 19:55:40 INFO Utils: Successfully started service 'HTTP class server' on port 38364.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.3.1
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_80)
Type in expressions to have them evaluated.
********************
scala>
1-2)、执行wc程序
scala> sc
res2: org.apache.spark.SparkContext = org.apache.spark.SparkContext@30fed8b
scala> sc.textFile("hdfs://hadoop1:9000/wordcount").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).saveAsTextFile("hdfs://hadoop1:9000/sparkWordCount")
*************
16/10/02 20:11:40 INFO TaskSetManager: Finished task 4.0 in stage 0.0 (TID 4) in 137 ms on hadoop3 (5/8)
16/10/02 20:11:40 INFO TaskSetManager: Starting task 6.0 in stage 0.0 (TID 6, hadoop3, NODE_LOCAL, 1295 bytes)
16/10/02 20:11:40 INFO TaskSetManager: Finished task 5.0 in stage 0.0 (TID 5) in 116 ms on hadoop3 (6/8)
16/10/02 20:11:41 INFO TaskSetManager: Starting task 7.0 in stage 0.0 (TID 7, hadoop3, NODE_LOCAL, 1296 bytes)
16/10/02 20:11:41 INFO TaskSetManager: Finished task 6.0 in stage 0.0 (TID 6) in 170 ms on hadoop3 (7/8)
16/10/02 20:11:41 INFO TaskSetManager: Finished task 7.0 in stage 0.0 (TID 7) in 172 ms on hadoop3 (8/8)
****************
16/10/02 20:11:45 INFO TaskSetManager: Finished task 5.0 in stage 1.0 (TID 13) in 64 ms on hadoop3 (6/8)
16/10/02 20:11:45 INFO TaskSetManager: Starting task 7.0 in stage 1.0 (TID 15, hadoop3, PROCESS_LOCAL, 1056 bytes)
16/10/02 20:11:45 INFO TaskSetManager: Finished task 6.0 in stage 1.0 (TID 14) in 59 ms on hadoop3 (7/8)
16/10/02 20:11:45 INFO DAGScheduler: Stage 1 (sortBy at <console>:22) finished in 4.065 s
****************
16/10/02 20:11:48 INFO TaskSetManager: Starting task 7.0 in stage 3.0 (TID 23, hadoop3, PROCESS_LOCAL, 1045 bytes)
16/10/02 20:11:48 INFO TaskSetManager: Finished task 6.0 in stage 3.0 (TID 22) in 97 ms on hadoop3 (7/8)
16/10/02 20:11:48 INFO TaskSetManager: Finished task 7.0 in stage 3.0 (TID 23) in 147 ms on hadoop3 (8/8)
16/10/02 20:11:48 INFO DAGScheduler: Stage 3 (sortBy at <console>:22) finished in 1.260 s
***************
16/10/02 20:12:18 INFO TaskSetManager: Finished task 6.0 in stage 4.0 (TID 30) in 2099 ms on hadoop3 (7/8)
16/10/02 20:12:19 INFO DAGScheduler: Stage 4 (saveAsTextFile at <console>:22) finished in 29.988 s
16/10/02 20:12:19 INFO TaskSetManager: Finished task 7.0 in stage 4.0 (TID 31) in 1022 ms on hadoop3 (8/8)
可以访问一下URL查看运行的信息:
http://hadoop1:8080/app/?appId=app-20161002195653-0000
http://hadoop1:4040/jobs/job/?id=1
http://hadoop1:4040/stages/stage/?id=4&attempt=0
http://hadoop1:4040/stages/stage/?id=3&attempt=0
1-3)、查看HDFS信息
[root@hadoop1 logs]# hadoop fs -ls /wordcount
Found 8 items
-rw-r--r-- 3 root supergroup 4436 2016-09-28 11:26 /wordcount/capacity-scheduler.xml-rw-r--r-- 3 root supergroup 952 2016-09-28 11:26 /wordcount/core-site.xml
-rw-r--r-- 3 root supergroup 9683 2016-09-28 11:26 /wordcount/hadoop-policy.xml
-rw-r--r-- 3 root supergroup 1149 2016-09-28 11:26 /wordcount/hdfs-site.xml
-rw-r--r-- 3 root supergroup 620 2016-09-28 11:26 /wordcount/httpfs-site.xml
-rw-r--r-- 3 root supergroup 3523 2016-09-28 11:26 /wordcount/kms-acls.xml
-rw-r--r-- 3 root supergroup 5511 2016-09-28 11:26 /wordcount/kms-site.xml
-rw-r--r-- 3 root supergroup 823 2016-09-28 11:26 /wordcount/yarn-site.xml
[root@hadoop1 logs]# hadoop fs -ls /sparkWordCount
Found 9 items
-rw-r--r-- 3 root supergroup 0 2016-10-02 20:12 /sparkWordCount/_SUCCESS
-rw-r--r-- 3 root supergroup 744 2016-10-02 20:12 /sparkWordCount/part-00000
-rw-r--r-- 3 root supergroup 540 2016-10-02 20:12 /sparkWordCount/part-00001
-rw-r--r-- 3 root supergroup 63 2016-10-02 20:12 /sparkWordCount/part-00002
-rw-r--r-- 3 root supergroup 69 2016-10-02 20:12 /sparkWordCount/part-00003
-rw-r--r-- 3 root supergroup 158 2016-10-02 20:12 /sparkWordCount/part-00004
-rw-r--r-- 3 root supergroup 260 2016-10-02 20:12 /sparkWordCount/part-00005
-rw-r--r-- 3 root supergroup 801 2016-10-02 20:12 /sparkWordCount/part-00006
-rw-r--r-- 3 root supergroup 9121 2016-10-02 20:12 /sparkWordCount/part-00007
[root@hadoop1 logs]# hadoop fs -cat /sparkWordCount/part-00000
(,2229)
(the,134)
(<property>,71)
(</property>,71)
(for,65)
(of,64)
*******
Spark 对每一个文件进行了处理,并保存了不同的文件中。
1-4)、spark-submit提交JAR运行在集群中实例
启动集群:
[root@hadoop1 bin]#./spark-submit --master spark://hadoop1:7077,hadoop1:7077
--executor-memory 512m --total-executor-cores 7 --class cn.****.spark.WordCount
/root/spark-1.0-SNAPSHOT.jar hdfs://hadoop1:9000/wc hdfs://hadoop1:9000/out0001
Spark - submit 参数详解
| 标记 |
描述 |
| --master |
表示要连接的集群管理器 |
| --deploy-mode |
选择在本地启动驱动器程序,还是在集群中的一台工作节点机器上启动。在客户端模式下,spark-submit会将驱动器程序运行在spark-submit被调用的这台机器上。在集群模式下,驱动器程序会被传输并被执行于集群的一个工作节点上,默认是本地模式。 |
| --class |
运行Java或者Scala程序应用的主类 |
| --name |
应用的显示名,会显示在spark的网页用户界面中 |
| --jars |
需要上传并放在应用的CLASSPATH中的JAR包的雷彪。如果应用依赖于少量第三方的jar包,可以把它们放在这个参数中 |
| --files |
需要放在应用工作目录中的文件。这个参数一般用来放需要分发到各节点的数据文件 |
| --py-files |
需添加到PYTHONPATH中的文件的雷彪。其中可以包含.py /.egg以及.zip文件 |
| --executor-memory |
执行器进程使用的内存量,以字节为单位,可以使用后缀指定更大的单位,比如512M或者15g |
| --driver-memory |
驱动器进程使用的内存量,以字节为单位。可以使用后缀指定更大的单位,比如512m或者15g |
| --total-executor-cores |
运行在集群机器上的总核数 |
| --spark.shuffle.memoryFraction |
参数说明:该参数用于设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2。也就是说,Executor默认只有20%的内存用来进行该操作。shuffle操作在进行聚合时,如果发现使用的内存超出了这个20%的限制,那么多余的数据就会溢写到磁盘文件中去,此时就会极大地降低性能。 参数调优建议:如果Spark作业中的RDD持久化操作较少,shuffle操作较多时,建议降低持久化操作的内存占比,提高shuffle操作的内存占比比例,避免shuffle过程中数据过多时内存不够用,必须溢写到磁盘上,降低了性能。此外,如果发现作业由于频繁的gc导致运行缓慢,意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
|
| --spark.storage.memoryFraction |
参数说明:该参数用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6。也就是说,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘。 参数调优建议:如果Spark作业中,有较多的RDD持久化操作,该参数的值可以适当提高一些,保证持久化的数据能够容纳在内存中。避免内存不够缓存所有的数据,导致数据只能写入磁盘中,降低了性能。但是如果Spark作业中的shuffle类操作比较多,而持久化操作比较少,那么这个参数的值适当降低一些比较合适。此外,如果发现作业由于频繁的gc导致运行缓慢(通过spark web ui可以观察到作业的gc耗时),意味着task执行用户代码的内存不够用,那么同样建议调低这个参数的值。
|
| --spark.default.parallelism |
参数说明:该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。 参数调优建议:Spark作业的默认task数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。通常来说,Spark默认设置的数量是偏少的(比如就几十个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。试想一下,无论你的Executor进程有多少个,内存和CPU有多大,但是task只有1个或者10个,那么90%的Executor进程可能根本就没有task执行,也就是白白浪费了资源!因此Spark官网建议的设置原则是,设置该参数为num-executors * executor-cores的2~3倍较为合适,比如Executor的总CPU core数量为300个,那么设置1000个task是可以的,此时可以充分地利用Spark集群的资源。
|
| --executor-cores |
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。 参数调优建议:Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
|
| --num-executors |
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。 参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
|
运行实例一:
./bin/spark-submit
--master spark:// hadoop1:7077,hadoop2:7077,hadoop3:7077
--deploy-mode cluster
--class com.databricks.examples.SparkExample
--name "WordCount"
--jars cn.****.spark.WordCount /root/spark-1.0-SNAPSHOT.jar
--total-executor-core 20
--executor-memory 10g
运行实例二:
spark-submit \
--master spark:// hadoop1:7077,hadoop2:7077,hadoop3:7077 \
--num-executors 100 \
--executor-memory 6G \
--executor-cores 4 \
--total-executor-cores 400 \
--driver-memory 1G \
--conf spark.default.parallelism=1000 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.3
Spark RDD实例详解
1-1)、读取文件详解
textFile("hdfs://hadoop1:9000/sparkMLlib/text.txt") ----> 读取HDFS文件
textFile("date.txt") ----> 读取当前文件下的文件
textFile("file://input/date.txt") ----> 本地指定目录下的文件
textFile("/input/data.txt") ----> 本地指定目录下的文件
textFile("/input/001.txt,input/002.txt") ----> 读取多个文件
textFile("/input") ----> 读取目录
textFile("/input/*.txt") ----> 含通配符的路径
textFile("/input/*.gz") ----> 读取压缩文件
// read()是DataFrameReader类型,load可以将数据读取出来
DataFrame peopleDF = sqlContext.read().format("json").load("D:\\text.json")
// 通过mode来指定输出文件的是append。创建新文件来追加文件
peopleDF.select("name").write().mode(SaveMode.Append).save("E:\\personNames");
// 直接读取JSON文件格式的数据
val dataFrame = sqlContext.read.json(path)
WordCount 实例
1-1)、Win版Wordcount
1-2)、集群版的Wordcount
package Hellword
import org.apache.spark.rdd.RDD
import org.apache.spark.{ SparkConf, SparkContext }
object WordCount {
def main(args: Array[String]) {
//创建sparkconf
val conf = new SparkConf().setAppName("WordCount")
//创建sparkcontext
val sc = new SparkContext(conf)
//读取hdfs中的数据
val lines: RDD[String] = sc.textFile(args(0))
//切分单词
val words: RDD[String] = lines.flatMap(_.split(" "))
//将单词计算
val wordAndOne: RDD[(String, Int)] = words.map((_, 1))
//分组聚合
val result: RDD[(String, Int)] = wordAndOne.reduceByKey((x, y) => x + y)
//排序
val finalResult: RDD[(String, Int)] = result.sortBy(_._2, false)
//将数据存储到HDFS中
finalResult.saveAsTextFile(args(1))
//释放资源
sc.stop()
}
}
[root@hadoop1 testDate]# spark-submit --master spark://hadoop1:7077,hadoop2:7077 --executor-memory 512m --total-executor-cores 7 --class WordCount /usr/local/testDate/SparkProject-1.0.jar hdfs://hadoop1:9000/sparkSql/persion.text hdfs://hadoop1:9000/sparkWordCount
[root@hadoop1 ~]# hadoop fs -cat /sparkWordCount/part-00000
(xiaoxiao,2)
(24,2)
(25,2)
(10,2)
[root@hadoop1 ~]# hadoop fs -cat /sparkWordCount/part-00001
(4,1)
(dageda,1)
(8,1)
(dada,1)
(6,1)
(2,1)
(xiaoli,1)
(26,1)
(xiaodaye,1)
(xiaowang,1)
(39,1)
(7,1)
(5,1)
(27,1)
(9,1)
(3,1)
(xiaozhang,1)
(daye,1)
(12,1)
(1,1)
(xiaolizi,1)
(23,1)
1-3)、Java版WordCount
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
public class JavaWordCount {
public static void main(String[] args) {
// 设置win下运行的配置
System.setProperty("hadoop.home.dir",
"E:\\winutils-hadoop-2.6.4\\hadoop-2.6.4");
// 初始化conf
SparkConf conf = new SparkConf().setAppName("JavaWordCount").setMaster("local");
// 初始化JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 获取输入放入内容
JavaRDD<String> stringJavaRDD = sc.textFile(args[0]);
// 获取数据并进行分割
JavaRDD<String> words = stringJavaRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(s.split(" "));
}
});
// 把元素编程元组
JavaPairRDD<String, Integer> wordAndOne = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s, 1);
}
});
// 对数据进行迭代累加
JavaPairRDD<String, Integer> result = wordAndOne.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1 + i2;
}
});
// 反转顺序
JavaPairRDD<Integer, String> switchedPair = result.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> tp) throws Exception {
return new Tuple2<Integer, String>(tp._2, tp._1);
}
});
// 排序并调换顺序
JavaPairRDD<String, Integer> finalResult = switchedPair.sortByKey(false).mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
public Tuple2<String, Integer> call(Tuple2<Integer, String> tp) throws Exception {
// 把数据进行调换
return tp.swap();
}
});
finalResult.saveAsTextFile(args[1]);
// 释放资源
sc.stop();
}
}
详细的运行过程请查看:
http://blog.csdn.net/xfg0218/article/details/53456484
Spark执行过程
Spark计算模型
1-1)、RDD 总结
概述:
RDD(Resilient Distributed Dataset)即使分布式数据集,是spark最基本的数据抽象,它代表了一个不可变、可分区、里面的元素可以并行计算的集合。
特点:
1、自动容错、位置感知性调度和伸缩性
2、RDD 允许用户把数据放在内存中,下次读取时可以在内存中直接读取
RDD的属性
是数据的最基本的数据单位,对于RDD来说,每一个分片都会计算一个任务处理,并决定计算的粒度,没有没有执行,则会使用默认的值,默认的值就是程序分配到的CPU CORE的个数。
Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
算子
Spark 提供了很多API,RDD提供了两个API,是TransFormation与Actions
TransFormation:转换操作,返回值还是一个RDD,如:map , filter , union
Actions:行动操作,返回结果是把RDD持久化起来,如count , collect , save
TransFormation采用的是懒策略,如果只是将TransFormation提交是不会提交任务来执行的,任务执行只会在action被提交时才被触发。
1-1)、常用的常用的Transformation
执行后不会马上执行,直到遇到action
| 转换 |
含义 |
| map(func) |
返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
| filter(func) |
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
| flatMap(func) |
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
| mapPartitions(func) |
类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) |
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是 (Int, Interator[T]) => Iterator[U] |
| sample(withReplacement, fraction, seed) |
根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 |
| union(otherDataset) |
对源RDD和参数RDD求并集后返回一个新的RDD |
| intersection(otherDataset) |
对源RDD和参数RDD求交集后返回一个新的RDD |
| distinct([numTasks])) |
对源RDD进行去重后返回一个新的RDD |
| groupByKey([numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) |
|
| sortByKey([ascending], [numTasks]) |
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
| sortBy(func,[ascending], [numTasks]) |
与sortByKey类似,但是更灵活 |
| join(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
| cogroup(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD |
| cartesian(otherDataset) |
笛卡尔积 |
| pipe(command, [envVars]) |
|
| coalesce(numPartitions) |
|
| repartition(numPartitions) |
|
| repartitionAndSortWithinPartitions(partitioner) |
|
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir",
"E:\\winutils-hadoop-2.6.4\\hadoop-2.6.4");
val conf = new SparkConf().setAppName("SparkText").setMaster("local")
val sc = new SparkContext(conf)
// 通过并行化把array转化为rdd,2代表分区的数量
val rdd1: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5, 6, 7), 2)
// 对数据进行过滤
val filter: RDD[Int] = rdd1.map(_ * 10).filter(_ % 2 == 0)
// 保存数据到HDFS
// filter.saveAsTextFile("hdfs://hadoop1:9000/sparkText")
// 构造数据
val pa: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5, 6, 7, 8, 9), 2)
// val by: ((Int) => Nothing) => RDD[Int] = pa.map(_ * 10).sortBy(_, true)
// 或者写成这样 parallelize.map(_ * 10).sortBy(x => x, true)
val rdd2 = sc.parallelize(Array("a b c d", "e f g h", "j sds sds sds", "asd asd"))
val map: RDD[String] = rdd2.flatMap(_.split(" "))
// flatMap相当于去除list
val rdd3 = sc.parallelize(List(List("a a", "b b"), List("c c", "d d"), List("e e", "f f")))
val map1: RDD[String] = rdd3.flatMap(_.flatMap(_.split(" ")))
// 求并集
// val rdd6 = sc.parallelize(List(1, 2, 3, 4, 5))
// val rdd7 = sc.parallelize(List(6, 7, 8, 9))
val rdd4 = Array(1, 2, 3, 4, 5)
val rdd5 = Array(6, 7, 8, 9)
val union: Array[Int] = rdd4.union(rdd5)
println("union = " + union.toBuffer)
// 求交叉集
val rdd6 = sc.parallelize(List(1, 2, 3, 4, 5))
val rdd7 = sc.parallelize(List(6, 7, 8, 9))
val intersection: RDD[Int] = rdd6.intersection(rdd7)
println("intersection = " + intersection)
// 对数据去重在统计个数
val collect: Array[Int] = rdd6.distinct().collect()
println("collect = " + collect)
// join数据
val rdd8 = sc.parallelize(List(("tom", 1), ("jerry", 2), ("kitty", 3)))
val rdd9 = sc.parallelize(List(("tom", 1), ("xiaoxu", 45), ("xiaozhang", 324)))
// 完全连接
val join: RDD[(String, (Int, Int))] = rdd8.join(rdd9)
println("join = " + join)
// 左外连接
val join1: RDD[(String, (Int, Option[Int]))] = rdd8.leftOuterJoin(rdd9)
println("join1 = " + join1)
// 右外连接
val join2: RDD[(String, (Option[Int], Int))] = rdd8.rightOuterJoin(rdd9)
println("join2 = " + join2)
//构造数据
val parallelize: RDD[String] = sc.parallelize(List("tom", "jerry"))
val parallelize1: RDD[String] = sc.parallelize(List("tom", "jerry", "shuke"))
// 对数据进行笛卡尔积
val cartesian: RDD[(String, String)] = parallelize.cartesian(parallelize1)
println("cartesian = " + cartesian)
}
1-2) 、常用的Action
| 动作 |
含义 |
| reduce(func) |
通过func函数聚集RDD中的所有元素,这个功能必须是课交换且可并联的 |
| collect() |
在驱动程序中,以数组的形式返回数据集的所有元素 |
| count() |
返回RDD的元素个数 |
| first() |
返回RDD的第一个元素(类似于take(1)) |
| take(n) |
返回一个由数据集的前n个元素组成的数组 |
| takeSample(withReplacement,num, [seed]) |
返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子 |
| takeOrdered(n, [ordering]) |
|
| saveAsTextFile(path) |
将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) |
将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
| saveAsObjectFile(path) |
|
| countByKey() |
针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
| foreach(func) |
在数据集的每一个元素上,运行函数func进行更新。 |
def main(args: Array[String]) {
System.setProperty("hadoop.home.dir",
"E:\\winutils-hadoop-2.6.4\\hadoop-2.6.4");
val conf: SparkConf = new SparkConf().setAppName("text").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
// 构造数据
val parallelize: RDD[Int] = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9))
// 对数据进行统计
val collect: Array[Int] = parallelize.collect()
println("collect = " + collect.toString)
// 查看数据的个数
val count: Long = parallelize.count()
println("count = " + count)
// 获取数据的前两个
val top: Array[Int] = parallelize.top(2)
println("top = " + top)
//获取数据的前一个
val first: Int = parallelize.first()
println("first = " + first)
// 对数据排序后再获取前三个
val ordered: Array[Int] = parallelize.takeOrdered(3)
println("ordered = " + ordered)
}
// 想要了解更多,访问下面的地址
http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html
1-3)、RDD 的特点
package org.apache.spark.rdd
在以上可以看出RDD是一个弹性的可复原的以及分布式的数据集,RDD包含以下五个特点。
mapPartitionsWithIndex
val func = (index: Int, iter: Iterator[(Int)]) => {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
}
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
rdd1.mapPartitionsWithIndex(func).collect
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
aggregate
def func1(index: Int, iter: Iterator[(Int)]) : Iterator[String] = {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
}
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
rdd1.mapPartitionsWithIndex(func1).collect
rdd1.aggregate(0)(math.max(_, _), _ + _)
rdd1.aggregate(5)(math.max(_, _), _ + _)
val rdd2 = sc.parallelize(List("a","b","c","d","e","f"),2)
def func2(index: Int, iter: Iterator[(String)]) : Iterator[String] = {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
}
rdd2.aggregate("")(_ + _, _ + _)
rdd2.aggregate("=")(_ + _, _ + _)
val rdd3 = sc.parallelize(List("12","23","345","4567"),2)
rdd3.aggregate("")((x,y) => math.max(x.length, y.length).toString, (x,y) => x + y)
val rdd4 = sc.parallelize(List("12","23","345",""),2)
rdd4.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)
val rdd5 = sc.parallelize(List("12","23","","345"),2)
rdd5.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
aggregateByKey
val pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2)
def func2(index: Int, iter: Iterator[(String, Int)]) : Iterator[String] = {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
}
pairRDD.mapPartitionsWithIndex(func2).collect
pairRDD.aggregateByKey(0)(math.max(_, _), _ + _).collect
pairRDD.aggregateByKey(100)(math.max(_, _), _ + _).collect
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
checkpoint
sc.setCheckpointDir("hdfs://node-1.****.cn:9000/ck")
val rdd = sc.textFile("hdfs://node-1.****.cn:9000/wc").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_)
rdd.checkpoint
rdd.isCheckpointed
rdd.count
rdd.isCheckpointed
rdd.getCheckpointFile
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
coalesce, repartition
val rdd1 = sc.parallelize(1 to 10, 10)
val rdd2 = rdd1.coalesce(2, false)
rdd2.partitions.length
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
collectAsMap
val rdd = sc.parallelize(List(("a", 1), ("b", 2)))
rdd.collectAsMap
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
combineByKey
val rdd1 = sc.textFile("hdfs://node-1.****.cn:9000/wc").flatMap(_.split(" ")).map((_, 1))
val rdd2 = rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n)
rdd2.collect
val rdd3 = rdd1.combineByKey(x => x + 10, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n)
rdd3.collect
val rdd4 = sc.parallelize(List("dog","cat","gnu","salmon","rabbit","turkey","wolf","bear","bee"), 3)
val rdd5 = sc.parallelize(List(1,1,2,2,2,1,2,2,2), 3)
val rdd6 = rdd5.zip(rdd4)
val rdd7 = rdd6.combineByKey(List(_), (x: List[String], y: String) => x :+ y, (m: List[String], n: List[String]) => m ++ n)
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
countByKey
val rdd1 = sc.parallelize(List(("a", 1), ("b", 2), ("b", 2), ("c", 2), ("c", 1)))
rdd1.countByKey
rdd1.countByValue
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
filterByRange
val rdd1 = sc.parallelize(List(("e", 5), ("c", 3), ("d", 4), ("c", 2), ("a", 1)))
val rdd2 = rdd1.filterByRange("b", "d")
rdd2.colllect
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
flatMapValues
val a = sc.parallelize(List(("a", "1 2"), ("b", "3 4")))
rdd3.flatMapValues(_.split(" "))
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
foldByKey
val rdd1 = sc.parallelize(List("dog", "wolf", "cat", "bear"), 2)
val rdd2 = rdd1.map(x => (x.length, x))
val rdd3 = rdd2.foldByKey("")(_+_)
val rdd = sc.textFile("hdfs://node-1.****.cn:9000/wc").flatMap(_.split(" ")).map((_, 1))
rdd.foldByKey(0)(_+_)
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
foreachPartition
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
rdd1.foreachPartition(x => println(x.reduce(_ + _)))
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
keyBy
val rdd1 = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)
val rdd2 = rdd1.keyBy(_.length)
rdd2.collect
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
keys values
val rdd1 = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)
val rdd2 = rdd1.map(x => (x.length, x))
rdd2.keys.collect
rdd2.values.collect
-------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------
mapPartitions
1)、- A list of partitions 特点说明
- 查看HDFS上的数据
[root@hadoop1 ~]# hadoop fs -ls /rdd
Found 2 items
-rw-r--r-- 3 root supergroup 14 2016-12-10 17:57 /rdd/1.text
-rw-r--r-- 3 root supergroup 16 2016-12-10 17:58 /rdd/2.text
- 查看分区的数量
scala> val rdd1 = sc.textFile("hdfs://hadoop1:9000/rdd")
rdd1: org.apache.spark.rdd.RDD[String] = hdfs://hadoop1:9000/rdd MapPartitionsRDD[3] at textFile at <console>:21
scala> val rdd2 = rdd1.partitions.length
rdd2: Int = 2
scala> val rdd3 = rdd1.map(x=>(x,1))
rdd3: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[9] at map at <console>:23
scala> rdd3.saveAsTextFile("hdfs://hadoop1:9000/ou1")
[Stage 4: > ( 0 + 2 ) / 2 ]
scala> rdd3.toDebugString
res16: String =
(2) MapPartitionsRDD[9] at map at <console>:23 []
| hdfs://hadoop1:9000/rdd MapPartitionsRDD[3] at textFile at <console>:21 []
| hdfs://hadoop1:9000/rdd HadoopRDD[2] at textFile at <console>:21 []
toDebugString查看RDD的依赖关系。
3、查看处理完的数据
[root@hadoop1 ~]# hadoop fs -cat /ou1/part-00000
(a,1)
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
[root@hadoop1 ~]# hadoop fs -cat /ou1/part-00001
(a,1)
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
可以看出如果没有对数据进行分区,那么就会按照文件的个数生成对应的文件,原因如下:
2)、- A function for computing each split 特点说明
1、创建读取数据得RDD
scala> val rdd1 = sc.textFile("hdfs://hadoop1:9000/rdd")
rdd1: org.apache.spark.rdd.RDD[String] = hdfs://hadoop1:9000/rdd MapPartitionsRDD[20] at textFile at <console>:21
2、对数据进行计算
scala> val rdd2 = rdd1.map(x=>(x,1))
rdd2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[21] at map at <console>:23
3、查看RDD之间的关系
scala> rdd2.toDebugString
res20: String =
(2) MapPartitionsRDD[21] at map at <console>:23 []
| hdfs://hadoop1:9000/rdd MapPartitionsRDD[20] at textFile at <console>:21 []
| hdfs://hadoop1:9000/rdd HadoopRDD[19] at textFile at <console>:21 []
4、对数据重新进行分区
scala> val rdd3 = rdd2.repartition(2)
rdd3: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[25] at repartition at <console>:25
5、保存数据
scala> rdd3.saveAsTextFile("hdfs://hadoop1:9000/out")
- 查看数据
[root@hadoop1 ~]# hadoop fs -cat /out/part-00000
(a,1)
(b,1)
(b,1)
(b,1)
(a,1)
(b,1)
(b,1)
(b,1)
[root@hadoop1 ~]# hadoop fs -cat /out/part-00001
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
可以看出repartition方法已经对数据进行了重新分区,进行了shuffer阶段。
7、使用partitionBy对数据进行分区
partitionBy 在PairRDDFunctions 类下
导入需要的包
scala> import org.apache.spark.HashPartitioner
import org.apache.spark.HashPartitioner
重新分区
scala> val rdd4 = rdd2.partitionBy(new HashPartitioner(2))
rdd4: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[27] at partitionBy at <console>:26
保存数据
scala> rdd4.saveAsTextFile("hdfs://hadoop1:9000/ou1")
查看数据
[root@hadoop1 ~]# hadoop fs -cat /ou1/part-00000
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
(b,1)
[root@hadoop1 ~]# hadoop fs -cat /ou1/part-00001
(a,1)
(a,1)
通过以上的实例可以看出通过partitionBy对数据的key进行了hash运算,把相同的数据放在了一起。
- reduceByKey对数据进行分区
scala> val rdd5 = rdd2.reduceByKey(_+_)
rdd5: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[29] at reduceByKey at <console>:26
scala> rdd5.saveAsTextFile("hdfs://hadoop1:9000/out1")
查看数据
[root@hadoop1 ~]# hadoop fs -cat /out1/part-00000
(b,13)
[root@hadoop1 ~]# hadoop fs -cat /out1/part-00001
(a,2)
可以看出在reduceByKey阶段对数据进行了shuffer把相同的key的数据分到了同一个分区中。
- reduceByKey 设置分区
scala> val rdd5 = rdd2.reduceByKey(_+_,1)
rdd5: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[31] at reduceByKey at <console>:26
scala> rdd5.saveAsTextFile("hdfs://hadoop1:9000/ou2")
查看数据
[root@hadoop1 ~]# hadoop fs -cat /ou2/part-00000
(a,2)
(b,13)
由于在reduceByKey阶段设置了分区的数量,所以在以后的运算中会把数据重新分到一个分区中进行运算。
1)、mapPartitionsWithIndex 分区
如果没有指定内存与核数,则默认的是1G内存全部的核数。
[root@hadoop1 start_sh]# spark-shell spark://hadoop1:7077,hadoop2:7077
********************
scala> val func = (index: Int, iter: Iterator[(Int)]) => {
| iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
| }
func: (Int, Iterator[Int]) => Iterator[String] = <function2>
scala> val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:21
scala> rdd1.mapPartitionsWithIndex(func).collect
res0: Array[String] = Array([partID:0, val: 1], [partID:0, val: 2], [partID:0, val: 3], [partID:0, val: 4], [partID:1, val: 5], [partID:1, val: 6], [partID:1, val: 7], [partID:1, val: 8], [partID:1, val: 9])
可以看出mapPartitionsWithIndex会根据数据的个数进行分区
2)、aggregate 聚合分区
scala> val rdd2 = sc.parallelize(List("a","b","c","d","e","f"),2)
rdd2: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[2] at parallelize at <console>:21
scala> rdd2.aggregate("")(_ + _, _ + _)
res1: String = abcdef
scala> rdd2.aggregate("")(_ + _, _ + _)
res2: String = defabc
scala> rdd2.aggregate("-")(_ + _, _ + _)
res43: String = --abc-def
scala> rdd1.aggregate(10)(_ + _, _ + _)
res45: Int = 75
通过以上的例子可以看出aggregate聚类的方法会进行三次的操作,分别是按照分区统计完后再操作aggregate括号中的数据。
3)、对aggregate数据查找最长以及最短的数据并显示
scala> rdd2.aggregate("")((x,y)=>math.max(x.length,y.length).toString,(x,y)=>(x+y))
res47: String = 11
scala> val rdd3 = sc.parallelize(List("12","23","345","4567"),2)
rdd3: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[4] at parallelize at <console>:21
scala> rdd3.aggregate("")((x,y) => math.max(x.length, y.length).toString, (x,y) => x + y)
res48: String = 24
scala> val rdd3 = sc.parallelize(List("12","23","345",""),2)
rdd3: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[5] at parallelize at <console>:21
scala> rdd3.aggregate("")((x,y)=>math.min(x.length,y.length).toString,(x,y)=>x + y)
res61: String = 10
scala> rdd3.aggregate("")((x,y)=>math.min(x.length,y.length).toString,(x,y)=>x + y)
res62: String = 01
Aggregate 先对部分进行聚合再对全局进行聚合。
4)、aggregateByKey实例
RDD的依赖关系
1-1) 、窄依赖--没有进行Shuffer
窄依赖指的是一个父RDD的Partition最多被一个RDD的Partition引用,如:map,filter,union操作。
1-2)、宽依赖--进行Shuffer
宽依赖是一个父RDD被多个子RDD引用,如:groupByKey操作。
注意:窄依赖与宽依赖的依据是是不是执行了Shuffer, JOIN在大多的情况下是宽依赖,如果之前分好组了那么就是窄依赖。
1-3)、Lineage
当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
1-4)、RDD的缓存
Spark 之所以快是因为spark使用了内存的技术,当持久化后会把数据集保存到内存中,在以后运算中速度更快。
1-5)、RDD缓存方式
RDD通过persist 或者cache 的方法计算出来的结果加入到内存中,以便今后是有。
一下源码的查看:
可以看出cache后也是调用的persist,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StorageLevel中定义的。
一下是方法的定义:
RDD 内存的储的机制,如果储存的数据过大,当在内存中占用30%是就会把数据保存到磁盘中,以后运算时也是在磁盘中获取数据。
MEMORY_ONLY是占用CPU最高的一个,是在启动时的默认的缓存方法。建议使用MEMORY_ONLY_SER,MEMORY_ONLY_SER能够高效的使用内存而且确保程序跑的更快
其中广播变量是以MEMORY_AND_DISK方式储存的
DAG的生成 <-- 调用RDD的算子生成了RDD的数组
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage,对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,大多数的情况下是shuffer的操作,因此将spark会将此定义为ShufferMapStage,以便向MapOuputTracker注册shuffer操作,spark通常将shuffer操作定义为stage的边界。由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
WorkCount 图解
1-1 ) 、官方图解
1-2)、个人图解
JAVA调用Scala实例
package JavaScala;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
/**
* Created by Adminon 2016/8/22.
*/
public class JavaScalaTest {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("JavaWordCount");
// 创建java sparkcontext
JavaSparkContext jsc = new JavaSparkContext(conf);
// 读取数据
JavaRDD<String> lines = jsc.textFile(args[0]);
// 切分
JavaRDD<String> words = lines
.flatMap(new FlatMapFunction<String, String>() {
public Iterable<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
// 遇见一个单词就记作一个1
JavaPairRDD<String, Integer> wordAndOne = words
.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word)
throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
// 分组聚合
JavaPairRDD<String, Integer> result = wordAndOne
.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2)
throws Exception {
return i1 + i2;
}
});
// 反转顺序
JavaPairRDD<Integer, String> swapedPair = result
.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Integer, String> call(
Tuple2<String, Integer> tp) throws Exception {
return new Tuple2<Integer, String>(tp._2, tp._1);
}
});
// 排序并调换顺序
JavaPairRDD<String, Integer> finalResult = swapedPair
.sortByKey(false)
.mapToPair(
new PairFunction<Tuple2<Integer, String>, String, Integer>() {
private static final long serialVersionUID = 1L;
public Tuple2<String, Integer> call(
Tuple2<Integer, String> tp)
throws Exception {
return tp.swap();
}
});
// 保存
finalResult.saveAsTextFile(args[1]);
jsc.stop();
}
}
Spark集群PageRank测试工具
1-1)、软件下载
http://prof.ict.ac.cn/bdb_uploads/bdb_3_1/packages/BigDataBench_V3.2.1_Hadoop.tar.gz
1-2)、执行PageRank算法
./spark-shell --num-executors 10 --driver-memory 10g --executor-memory 10g --executor-cores 10
scala> sc
scala> val iters =10
scala> val lines = sc.textFile("/opt/BigDataBench_V3.2.1_Hadoop_Hive/SearchEngine/PageRank/data-PageRank/Google_genGraph_10.txt")
scala> val links = lines.map{ s =>
val parts = s.split("\\s+")
(parts(0), parts(1))
}.distinct().groupByKey().cache()
scala> var ranks = links.mapValues(v => 1.0)
scala> for (i <- 1 to iters) {
val contribs = links.join(ranks).values.flatMap{ case (urls, rank) =>
val size = urls.size
urls.map(url => (url, rank / size))
}
ranks = contribs.reduceByKey(_ + _).mapValues(0.15 + 0.85 * _)
}
scala> val output = ranks.collect()
scala> output.foreach(tup => println(tup._1 + " has rank: " + tup._2 + "."))
1-3)、查看结果
Spark-bench性能测试
SparkBench是Spark的基准测试组件(集成了很多spark支持的经典测试案列)。 它大致包含四种不同类型的测试案例,包括机器学习,图形处理,流处理和SQL查询。
Spark-Bench所选择的测试案例可以,在不同的工作负载情况下测试出系统瓶颈; 目前,我们大致涵盖了CPU,内存和Shuffle以及IO密集型工作负载(测试案例)。
它还包括一个数据生成器,允许用户生成任意大小的输入数据。
详情请查看:
https://github.com/SparkTC/spark-bench/tree/legacy 或http://blog.csdn.net/xfg0218/article/details/79250019
准备环境
A)、清除前查看
#free -m
#sync
# echo 1 > /proc/sys/vm/drop_caches
#echo 2 > /proc/sys/vm/drop_caches
#echo 3 > /proc/sys/vm/drop_caches
#free -g
1-1)、下载
https://github.com/SparkTC/spark-bench/tree/legacy
1-2)、测试MapReduce和HDFS的运行性能
https://github.com/SparkTC/spark-bench/blob/legacy/readme.md
本实例生成数据300G
A)、修改KMeans配置
$ cat env.sh
# The parameters for data generation. 100 million points roughly produces 36GB data size
NUM_OF_POINTS=200000000
NUM_OF_CLUSTERS=500
DIMENSIONS=60
SCALING=0.6
NUM_OF_PARTITIONS=2
MAX_ITERATION=10
NUM_RUN=1
SPARK_STORAGE_MEMORYFRACTION=0.48
#cd spark-bench-legacy/KMeans/bin
#./gen_data.sh
#cd /KMeans/bin
#./run.sh
#hadoop fs -ls /SparkBench/KMeans/Output
1-3)、测试Spark的运行性能
A)、修改SVM配置
cd /spark-bench-legacy/SVM/conf
#vim env.sh
# for prepare #600M example=40G
NUM_OF_EXAMPLES=500000000 #300000000
NUM_OF_FEATURES=100
NUM_OF_PARTITIONS=10
# for running
MAX_ITERATION=3
SPARK_STORAGE_MEMORYFRACTION=0.79
#cd spark-bench-legacy/SVM/bin
#./gen_data.sh
C)、数据检查
#hadoop fs -ls /SparkBench/SVM/Input
#cd /KMeans/bin
#./run.sh