Date: 2018.9.21
1、参考
https://blog.csdn.net/SoaringLee_fighting/article/details/82155608
https://blog.csdn.net/SoaringLee_fighting/article/details/81743505
https://blog.csdn.net/SoaringLee_fighting/article/details/81906495
https://blog.csdn.net/SoaringLee_fighting/article/details/82530435
2、前言
最近三个月的时间,都在进行解码库的arm架构汇编优化,包括arm32位汇编优化和arm64位汇编优化。在arm32位入门之后,只要掌握了两种架构的寄存器和指令集差异之后,就可以很快上手编写arm64位汇编代码了。下面就arm32位和arm64位架构、寄存器和指令差异进行分析总结。
3、架构差异
ARM是RISC(精简指令集)处理器,不同于x86指令集(CISC,复杂指令集)。
Arm32位是ARMV7架构,32位的,对应处理器为Cortex-A15等; iphone5以前均是32位的;
需要注意:ARMV7-A和ARMV7-R系列支持neon指令集,ARMv7-M系列不支持neon指令集。
ARM64位采用ARMv8架构,64位操作长度,对应处理器有Cortex-A53、Cortex-A57、Cortex-A73、iphones的A7和A8等。
4、寄存器差异
ARM32位通用寄存器和ARM64位通用寄存器差异详见:ARM寄存器及其说明
ARM32位neon寄存器和ARM64位neon寄存器差异:
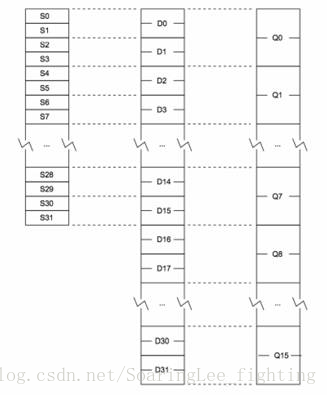
32位下 NEON寄存器:
包括:
- 32个S寄存器,S0~S31,(单字,32bit)
- 32个D寄存器,D0~D31,(双字,64bit)
- 16个Q寄存器,Q0~Q15,(四字,128bit)
使用注意:
1、NEON寄存器将每个寄存器均视为一个向量,该向量又包含1,2,4,8或16个大小和类型均相同的元素。也可以将各个元素当做标量访问。
NEON的这三种寄存器是重叠的,物理地址是一样的。
2、NEON寄存器在使用时,如果用到d8~d15寄存器,需要先入栈保存vpush {d8-d15},使用完之后要出栈vpop {d8-d15}。
64位下NEON寄存器:
包括:
- 32个B寄存器(B0~B31),8bit
- 32个H寄存器(H0~H31),半字 16bit
- 32个S寄存器(S0~S31),单子 32bit
- 32个D寄存器(D0~D31),双字 64bit
- 32个Q寄存器(V0~V31),四字 128bit
不同位数下寄存器之间的关系如下图所示:
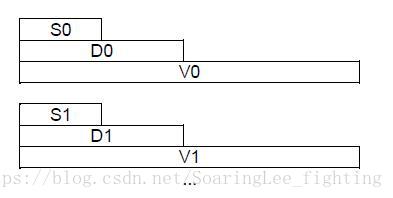
其中S0是D0的低半部分,D0是V0的低半部分 。
注意:
64位下NEON寄存器与32位下NEON寄存器之间的关系不同!
neon寄存器 v0~v31使用说明:
v0~v7:用于参数传递和返回值,子程序不需要保存;
v8~v15:子程序调用时必须入栈保存(低64位);
v16~v31:子程序使用时不需要保存。
具体可参考:
http://infocenter.arm.com/help/topic/com.arm.doc.ihi0055b/IHI0055B_aapcs64.pdf 5.1.2 SIMD and Floating-Point Registers
5、A64指令集特有的指令及其用法(指令差异)
AARCH64是全新32位固定长度指令集,支持64位操作数的新指令,大多数指令可以具有32位或64位参数。
- 32位neon指令都是以V开头,而64位neon指令没有V;
- 32位寄存器需要保存的是r4~r11,q4~q7,而64位寄存器需要保存的是x19~x29
,v8~v15; - 64位下NEON寄存器与32位下NEON寄存器之间的关系不同;
- 向64位或者更低位的矢量寄存器中写数据时,会将高位置零;
- 在AArch64中,没有通用寄存器的SIMD和饱和算法指令。只有neon寄存器才有SIMD或饱和算法指令;
- ARM64下没有swap指令和条件执行指令。
- 关于指令中立即数取值范围的说明:
不同指令中的#或者#<具有不同的取值范围,这个取决于所使用的指令,比如:
mov <wd>, #<imm> //该指令中立即数范围为-65536~65535。
cmp <wn>, #<imm> //该指令中#<imm>为无符号立即数,取值范围为0~4095(12 bit)。
特别说明:大部分ARM指令中的立即数不能是负数,需要注意不同指令的取值范围。
- 更多ARM32和ARM64位对应关系可以参考文档: ARM.Reference_Manual中5.7.23小节 。
1. shl和ushr指令
shl <V>.<d>, <V>.<n>, #<shift>
ushr <V>.<d>, <V>.<n>, #<shift>
ushr d2, d2, #8
使用注意事项:这两条指令只能操作64位数据,即只能对D寄存器进行处理。
ushr最多只能进行64位数据的右移,并且右移时会影响V2寄存器的高64位数据(清零),因此高64位数据需要在右移前保存,否则相关数据会被修改。
2. INS指令
用法与MOV指令基本一样,可以实现neon标量与neon标量之间的传送,以及ARM寄存器与neon标量之间的传送。
INS <Vd>.<Ts>[index1], <Vn>.<Ts>[index2]
INS <Vd>.<Ts>[index1], Rn
3. SUQADD、USQADD指令
既有标量用法,也有矢量用法。
SUQADD <V><d>, <V><d> // signed saturating accumulate of unsigned value
SUQADD <Vd>.<T>, <Vn>.<T>
USQADD <V><d>, <V><d> // unsigned saturating accumulate of signed value
USQADD <Vd>.<T>, <Vn>.<T>
4. RBIT、REV指令
RBIT <Wd>, <Wn> //reverse bits
REV <Wd>, <Wn> //reverse bytes
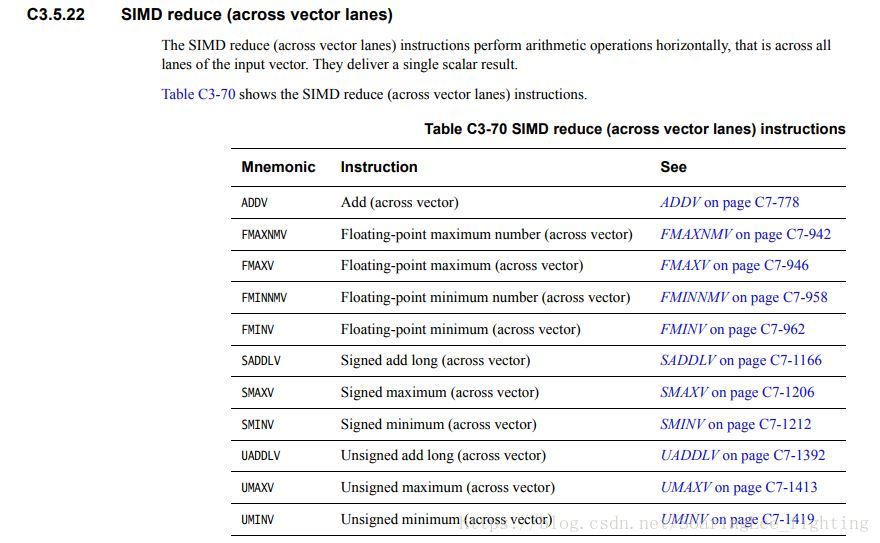
5. ADDV,SADDLV,SMAXV,SMINV (Vector Reduce(across lanes))
后缀带V指令:
ADDV <V><d>, <Vn><T> // Integer sum element to scalar(vector)
SADDLV <V><d>, <Vn><T> // Signed Interger sum elements to long scalar(vector)
SMAXV <V><d>, <Vn><T> // Signed Interger maximum elements to scalar(vector)
SMINV <V><d>, <Vn><T> // Signed Interger minimum elements to scalar(vector)
eg.:
addv B0, v1.8B // 将v1寄存器中的低64位中8个8位数据相加求和后,赋给v0的最低8位。
用法说明:
vector reduce instrunctions perform arithmetic operations horizontally, that is across all lanes of the input vector. they deliver a single scalar result.
更多详细解释可以参考:https://static.docs.arm.com/ddi0487/a/DDI0487A_j_armv8_arm.pdf
6. sxtw使用注意事项
负数在使用时必须进行符号扩展!
比如:
sxtw x4, w4
7. w寄存器到v寄存器
直接使用dup指令
dup v0.8B, w2
8.常用指令对应关系(arm32---->arm64)
vmovl------>uxtl/sxtl
vqmovn----->sqxtn
vqmovun----->sqxtun
vqrshrun---->sqrshrun
vceq------->cmeq
vcge------->cmge
vadd------>add
vsub------>sub
vaddl----->saddl,uaddl
vaddw----->saddw,uaddw,sw2addw2,uadd
vmull----->smull,smull2,umull,umull2
vmax,vmin----->smax,umax,smin,umin
vmlal--------> smlal,smlal2,umlal,umlal2
vrshl--------> urshl,srshl
vtrn---------> trn1,trn2
vstm/vstr----> stp/str
vld1.32 {d0[]}, [r0], r2-----> ld1r {v0.S}[0], [x0], x2
addgt,addle,subgt,suble----->csel,csetm,cset,csinc,csinv
9. 指令结尾带“2”的寄存器高64位操作:
smull2 v0.4S, v1.4H, v2.4H //将v1和v2高64位中每一个16位相乘,并将结果放在v0的每个32位中。
sqxtn2 v5.8H, v4.4S //将v4中的每个32位元素,饱和缩进到v5高64位的每个16位中。
sxtl2 v16.4S, v17.4H //将v17高64位中的每个16位元素,扩展到v16的每个32位元素中。
10. ADDP,SMAXP,SMINP,UMAXP,UMINP
后缀带P指令:
addp v1.8B, v2.8B, v3.8B // add pairwise
用法说明:
the SIMD pairwise arthmetic instructions perform operations on pairs of adjacent element and deliver a vector result.
11. 替代arm32下条件执行指令的arm64位指令:
arm32位:
bgt,addgt,suble等
arm64位:
b.gt,csinc, csel, cset, csetm, csnev
说明: 在ARM64下没有条件执行指令。
6、AArch32与AArch64的区别
6.1 入栈和出栈:
arm64位(aarch64架构):
(1)arm寄存器入栈和出栈:
入栈:
sub sp, sp, #0x10
stp x8, x9, [sp] // 寄存器成对入栈
出栈:
ldp x8, x9, [sp]
add sp, sp, #0x10 //寄存器成对出栈
原则:1、堆栈入栈和出栈后,SP指针应该保持不变。2、LIFO。 3、特别注意是,从SP位置存取数据都是从低地址开始的。
(2)neon寄存器入栈和出栈:
ARM64位三种入栈出栈方法:
方法一:
stp d8,d9, [sp, #-64]!
stp d10,d11,[sp, #16]!
stp d12,d13,[sp, #16]!
stp d14,d15,[sp, #16]!
ldp d14,d15,[sp], #-16
ldp d12,d13,[sp], #-16
ldp d10,d11,[sp], #-16
ldp d8,d9,[sp], #64 //恢复sp位置
方法二:
stp d8,d9, [sp, #-16]!
stp d10,d11,[sp, #-16]!
stp d12,d13,[sp, #-16]!
stp d14,d15,[sp, #-16]!
ldp d14,d15,[sp], #16
ldp d12,d13,[sp], #16
ldp d10,d11,[sp], #16
ldp d8,d9,[sp], #16 //恢复sp位置
方法三:
.macro push_v_regs
stp d8, d9, [sp, #-16]!
stp d10, d11, [sp, #-16]!
stp d12, d13, [sp, #-16]!
stp d14, d15, [sp, #-16]!
.endm
.macro pop_v_regs
ldp d14, d15, [sp], #16
ldp d12, d13, [sp], #16
ldp d10, d11, [sp], #16
ldp d8, d9, [sp], #16
.endm
arm32位:
push {r4-r11, lr}
vpush {d8-d15}
vpop {d8-d15}
pop {r4-r11, pc}
6.2 4x4矩阵转置:
arm64位(aarch64架构):
.macro transpose4x4B r0,r1,r2,r3,t4,t5,t6,t7
trn1 \t4\().8B, \r0\().8B, \r1\().8B
trn2 \t5\().8B, \r0\().8B, \r1\().8B
trn1 \t6\().8B, \r2\().8B, \r3\().8B
trn2 \t7\().8B, \r2\().8B, \r3\().8B
trn1 \r0\().8B, \t4\().8B, \t6\().8B
trn1 \r1\().8B, \t5\().8B, \t7\().8B
trn2 \r2\().8B, \t4\().8B, \t6\().8B
trn3 \r3\().8B, \t5\().8B, \t7\().8B
.endm
arm32位:
vtrn.16 q0, q1
vtrn.8 d0, d1
vtrn.8 d2, d3
6.3 Difference between AArch64 and AArch32
来源参考:https://www.nxp.com/docs/en/application-note/AN12212.pdf


THE END!