AWD-LSTM是目前最优秀的语言模型之一。在众多的顶会论文中,对字级模型的研究都采用了AWD-LSTMs,并且它在字符级模型中的表现也同样出色。
本文回顾了论文——Regularizing and Optimizing LSTM Language Models ,在介绍AWD-LSTM模型的同时并解释其中所涉及的各项策略。该论文提出了一系列基于词的语言模型的正则化和优化策略。这些策略不仅行之有效,而且能够在不改变现有LSTM模型的基础上使用。
AWD-LSTM即ASGD Weight-Dropped LSTM。它使用了DropConnect及平均随机梯度下降的方法,除此之外还有包含一些其它的正则化策略。我们将在后文详细讲解这些策略。本文将着重于介绍它们在语言模型中的成功应用。
实验代码获取:awd-lstm-lm GitHub repository
LSTM中的数学公式:
- it = σ(Wixt + Uiht-1)
- ft = σ(Wfxt + Ufht-1)
- ot = σ(Woxt + Uoht-1)
- c’t = tanh(Wcxt + Ucht-1)
- ct = it ⊙ c’t + ft ⊙ c’t-1
- ht = ot ⊙ tanh(ct)
其中, Wi, Wf, Wo, Wc, Ui, Uf, Uo, Uc都是权重矩阵,xt表示输入向量,ht表示隐藏单元向量,ct表示单元状态向量, ⊙表示element-wise乘法。
接下来我们将逐一介绍作者提出的策略:
权重下降的LSTM
RNN的循环连接容易导致过拟合问题,如何解决这一问题也成了一个较为热门的研究领域。Dropouts的引入在前馈神经网络和卷积网络中取得了巨大的成功。但将Dropouts引入到RNN中却反响甚微,这是由于Dropouts的加入破坏了RNN长期依赖的能力。
研究学者们就此提出了许多解决方案,但是这些方法要么作用于隐藏状态向量ht-1,要么是对单元状态向量ct进行更新。上述操作能够解决高度优化的“黑盒”RNN,例如NVIDIA’s cuDNN LSTM中的过拟合问题。
但仅如此是不够的,为了更好的解决这个问题,研究学者们引入了DropConnect。DropConnect是在神经网络中对全连接层进行规范化处理。Dropout是指在模型训练时随机的将隐层节点的权重变成0,暂时认为这些节点不是网络结构的一部分,但是会把它们的权重保留下来。与Dropout不同的是DropConnect在训练神经网络模型过程中,并不随机的将隐层节点的输出变成0,而是将节点中的每个与其相连的输入权值以1-p的概率变成0。
Regularization of Neural Networks using DropConnect
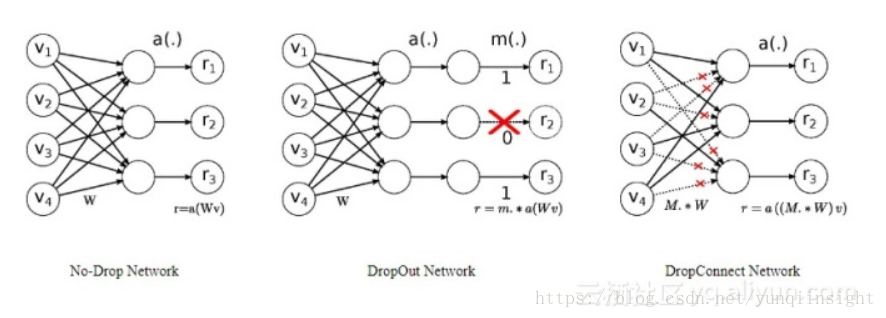
DropConnect作用在hidden-to-hidden权重矩阵(Ui、Uf、Uo、Uc)上。在前向和后向遍历之前,只执行一次dropout操作,这对训练速度的影响较小,可以用于任何标准优化的“黑盒”RNN中。通过对hidden-to-hidden权重矩阵进行dropout操作,可以避免LSTM循环连接中的过度拟合问题。
你可以在 awd-lstm-lm 中找到weight_drop.py 模块用于实现。
作者表示,尽管DropConnect是通过作用在hidden-to-hidden权重矩阵以防止过拟合问题,但它也可以作用于LSTM的非循环权重。
使用非单调条件来确定平均触发器
研究发现,对于特定的语言建模任务,传统的不带动量的SGD算法优于带动量的SGD、Adam、Adagrad及RMSProp等算法。因此,作者基于传统的SGD算法提出了ASGD(Average SGD)算法。
Average SGD
ASGD算法采用了与SGD算法相同的梯度更新步骤,不同的是,ASGD没有返回当前迭代中计算出的权值,而是考虑的这一步和前一次迭代的平均值。
传统的SGD梯度更新:
w_t = w_prev - lr_t * grad(w_prev)AGSD梯度更新:
avg_fact = 1 / max(t - K, 1)
if avg_fact != 1:
w_t = avg_fact * (sum(w_prevs) + (w_prev - lr_t * grad(w_prev)))
else:
w_t = w_prev - lr_t * grad(w_prev)其中,k是在加权平均开始之前运行的最小迭代次数。在k次迭代开始之前,ASGD与传统的SGD类似。t是当前完成的迭代次数,sum(w_prevs)是迭代k到t的权重之和,lr_t是迭代次数t的学习效率,由学习率调度器决定。
但作者也强调,该方法有如下两个缺点:
- 学习率调度器的调优方案不明确
- 如何选取合适的迭代次数k。值太小会对方法的有效性产生负面影响,值太大可能需要额外的迭代才能收敛。
基于此,作者在论文中提出了使用非单调条件来确定平均触发器,即NT-ASGD,其中:
- 当验证度量不能改善多个循环时,就会触发平均值。这是由非单调区间的超参数n保证的。因此,每当验证度量没有在n个周期内得到改进时,就会使用到ASGD算法。通过实验发现,当n=5的时候效果最好。
- 整个实验中使用一个恒定的学习速率,不需要进一步的调整。
正则化方法
除了上述提及的两种方法外,作者还使用了一些其它的正则化方法防止过拟合问题及提高数据效率。
长度可变的反向传播序列
作者指出,使用固定长度的基于时间的反向传播算法(BPTT)效率较低。试想,在一个时间窗口大小固定为10的BPTT算法中,有100个元素要进行反向传播操作。在这种情况下,任何可以被10整除的元素都不会有可以反向支撑的元素。这导致了1/10的数据无法以循环的方式进行自我改进,8/10的数据只能使用到部分的BPTT窗口。
为了解决这个问题,作者提出了使用可变长度的反向传播序列。首先选取长度为bptt的序列,概率为p以及长度为bptt/2的序列,概率为1-p。在PyTorch中,作者将p设为0.95。
base_bptt = bptt if np.random.random() < 0.95 else bptt / 2其中,base_bptt用于获取seq_len,即序列长度,在N(base_bptt, s)中,s表示标准差,N表示服从正态分布。代码如下:
seq_len = max(5, int(np.random.normal(base_bptt, 5)))学习率会根据seq_length进行调整。由于当学习速率固定时,会更倾向于对段序列而非长序列进行采样,所以需要进行缩放。
lr2 = lr * seq_len / bpttVariational Dropout
在标准的Dropout中,每次调用dropout连接时都会采样到一个新的dropout mask。而在Variational Dropout中,dropout mask在第一次调用时只采样一次,然后locked dropout mask将重复用于前向和后向传播中的所有连接。
虽然使用了DropConnect而非Variational Dropout以规范RNN中hidden-to-hidden的转换,但是对于其它的dropout操作均使用的Variational Dropout,特别是在特定的前向和后向传播中,对LSTM的所有输入和输出使用相同的dropout mask。
点击查看官方awd-lstm-lm GitHub存储库的Variational dropout实现。详情请参阅原文。
Embedding Dropout
论文中所提到的Embedding Dropout首次出现在——《A Theoretically Grounded Application of Dropout in Recurrent Neural Networks》一文中。该方法是指将dropout作用于嵌入矩阵中,且贯穿整个前向和反向传播过程。在该过程中出现的所有特定单词均会消失。
Weight Tying(权重绑定)
权重绑定共享嵌入层和softmax层之间的权重,能够减少模型中大量的参数。
Reduction in Embedding Size
对于语言模型来说,想要减少总参数的数量,最简单的方法是降低词向量的维数。即使这样无法帮助缓解过拟合问题,但它能够减少嵌入层的维度。对LSTM的第一层和最后一层进行修改,可以使得输入和输出的尺寸等于减小后的嵌入尺寸。
Activation Regularization(激活正则化)
L2正则化是对权重施加范数约束以减少过拟合问题,它同样可以用于单个单元的激活,即激活正则化。激活正则化可作为一种调解网络的方法。
loss = loss + alpha * dropped_rnn_h.pow(2).mean()Temporal Activation Regularization(时域激活正则化)
同时,L2正则化能对RNN在不同时间步骤上的输出差值进行范数约束。它通过在隐藏层产生较大变化对模型进行惩罚。
loss = loss + beta * (rnn_h[1:] - rnn_h[:-1]).pow(2).mean()其中,alpha和beta是缩放系数,AR和TAR损失函数仅对RNN最后一层的输出起作用。
模型分析
作者就上述模型在不同的数据集中进行了实验,为了对分分析,每次去掉一种策略。
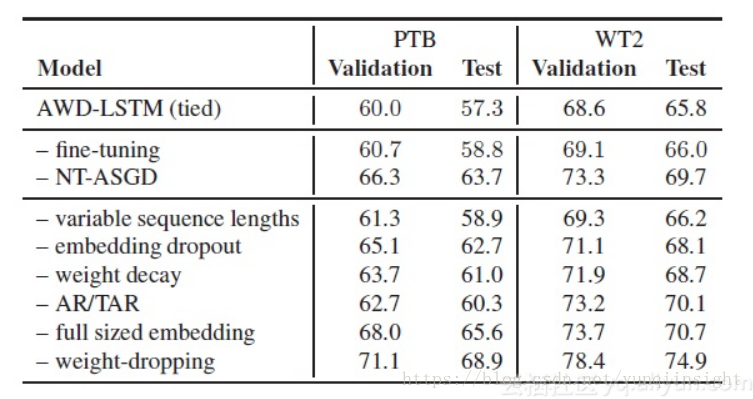
图中的每一行表示去掉特定策略的困惑度(perplexity)分值,从该图中我们能够直观的看出各策略对结果的影响。
实验细节
数据——来自Penn Tree-bank(PTB)数据集和WikiText-2(WT2)数据集。
网络体系结构——所有的实验均使用的是3层LSTM模型。
批尺寸——WT2数据集的批尺寸为80,PTB数据集的批尺寸为40。根据以往经验来看,较大批尺寸(40-80)的性能优于较小批尺寸(10-20)。
总结
该论文很好的总结了现有的正则化及优化策略在语言模型中的应用,对于NLP初学者甚至研究者都大有裨益。论文中强调,虽然这些策略在语言建模中获得了成功,但它们同样适用于其他序列学习任务。
原文链接
本文为云栖社区原创内容,未经允许不得转载。