一:myisam是把总的记录数记录在磁盘上,查的时候直接返回。innodb是把所有的记录一条条的查出来去计数。
注意这里是没有过滤条件的count(*),如果where后面有条件,myisam也是一条条的统计。
二:为什么innodb不像myisam一一样呢?
因为mvcc机制。不同会话可能返回的值不一样。

其实innodb对count(*)还是做了优化的。普通索引上市主键,主键上是每一行,所以统计普通索引即可。空间占用更小
尽量减少扫描数量是数据库设计的通用原则
show table status 不准确
解决办法:
一:用缓存
问题一;可能有丢失更新问题。
redis加一之后还没有持久化,异常重启。
没有异常重启,逻辑也有问题:
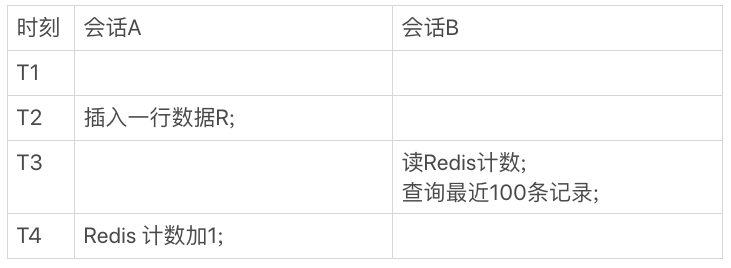

上边的问题是数据不一致。
解决办法二:数据库保存记录数,至少 保证了会话一致性

count(*)数据库做了优化,首选
count(1) 就是统计记录数
,count(主键) ,找出记录数,找到主键统计
count(字段) 统计字段不为空的记录数