原文链接:http://www.sohu.com/a/133767871_473476
正文开始前,先讲个故事。
场景:理综开卷考试:(选择题;试卷下发限时一天;答题过程不限)
人物:学渣A、学渣B、学渣C
经过:
学渣A单打独斗,很快交卷,不出意外考砸了;
学渣B叫来很多“学弱”,每道题都要经讨论决定答案。最终B拿到比A高很多的分数;但由于众口不一,浪费了B大量打游戏的时间;
学渣C只叫来为数不多的几个偏科“学弱”,他们每人都有自己最擅长的科目。C做好自己确定的题目后,把卷子扔给其他人就去打游戏了,最后一个人答完,C随便看了看就交卷了,结果成绩居然比B还高了一些,这让花费了大量时间、欠下众多人情的B愤愤不平……
如果将上述场景类比到数据科学领域,A的做法是传统的训练分类器的办法,精度低,无法最大程度掌握训练数据中的信息,所以在测试数据上的表现往往不尽如人意;于是科学家们秉承“人多力量大”的基本原则,就像上述B和C一样,尝试着运用了多训练器一起解决问题的办法,这就是“集成学习”的思想雏形。

图1 传统方法vs集成学习
同样是叫来了自己的朋友们,但是B和C采用了完全不同的策略来完成那份试卷。如果把“叫朋友”类比到机器学习领域的话,两位同学的策略正对应着“集成思想”孕育出的两大利器:
B同学的“人海战术”---Bagging(Bootstrap Aggregation)
C同学的“逐个击破”---Boosting
作者接下来会根据自己对这两个算法的理解,力求以通俗的语言辅以图解来解释这两个“集成学习”中的著名思想。读者可以类比于场景中B、C同学的策略来辅助理解。(下面内容中相关术语均针对“分类”问题)
B同学的“人海战术”---Bagging
全称Bootstrap Aggregation,是一种在原始数据集上通过有放回抽样重新选出N个新数据集来训练分类器的集成技术。

图2 Bagging流程
如图2所示,一次完整的Bagging迭代过程可以分为以下两步:
①对原始数据(M个观测记录)进行m次随机有放回抽样,生成一份训练样本(m个观测记录, m < M)
②运用任一机器学习算法对产生的训练样本进行训练,得到一个分类器
至此我们完成了一次Bagging迭代并得到了一个分类器,重复此过程任意次(如果每次迭代选用的分类器能力不够强,则迭代次数较多为好),最后将每个迭代过程得到的分类器Ci进行组合即可。
C同学的“逐个击破”---Boosting
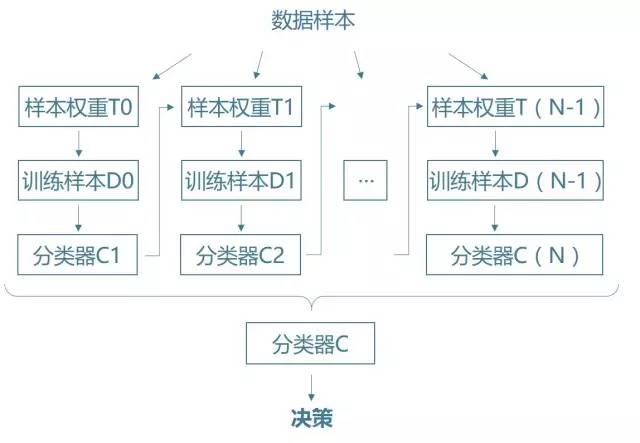
图3 Boosting流程
同样是根据“集成学习”思想提出的算法,Boosting的核心原理与Bagging一样,对原始样本抽样来训练多个分类器,综合得到效果强大的最终模型,不过与后者不同的是,Boosting在每次抽取样本之前会对每一条观测数据赋予相应的权重,如同每次模拟考试之后老师往往会给予成绩不理想的学生更多的关注一样,Boosting通过这种赋予样本权重的方法来优化每一轮迭代所产生的基分类器。
一次完整的Boosting迭代共有以下三步:
①对已经被赋予权重的样本进行抽样(权重高的样本被抽到的概率大),得到训练样本
②运用任一机器学习算法对产生的训练样本进行训练,得到一个分类器
③总结分类器在这一轮迭代中的样本上的分类表现,以此为根据产生新的样本权重
这样每次迭代都会得到一个基于上一轮训练结果的“训练器2.0”,最后的分类器结果自然变现不俗。
应用案例
1 模型介绍
本文主要聚焦于机器学习领域的分类问题,更具体的说是“二分类”问题,这类问题在平时生活以及业界都有很高的出场率:我昨天的订单今天会不会发货?这位客户下个月会不会及时还款?A厂的这台机器今天会不会出现故障…
对于这些疑问,最原始的办法是根据一些已知信息来人为判断,而引入机器学习的知识以后,我们可以建立模型来对这些未知的结果进行预测。
作者选取了Kaggle社区上的一个二分类问题的数据集来展现“集成学习”思想的威力。上文提到“集成学习”只是一种朴素的思想,而要解决实际问题则需要实实在在落地的模型,这里要介绍由这种思想衍生出的两种著名机器学习算法:随机森林(RF)以及梯度提升树(GBDT)。
*由于GBDT的运行速度过慢,所以作者选取了这一算法的进阶版:XGBoost,下文中出现的所有GBDT均可以等价理解为XGBoost

图4 思想与模型
2 准确率对比
由于这两种算法都是在“决策树”这一基本分类器上应用“集成学习”思想得到,所以作者分别用决策树(DT)、随机森林(RF)、XGBoost三种算法对数据进行了训练,还选用了支持向量机(SVM)作为另一单分类器来进行对比,同时这四种算法可以与文章开头的小场景进行类比,其中:
决策树(DT)与支持向量机(SVM)作为单分类器对应于A的方法;
随机森林(RF)作为Bagging的代表对应于B的方法;
最后XGBoost作为Boosting的代表对应于C的方法。
下面进入没有对比就没有伤害的环节,来看一下不同算法的表现:
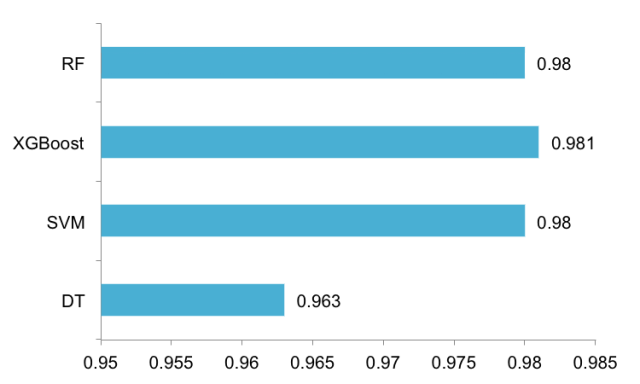
图5 传统方法vs集成学习
由于这份数据已经采取预处理,所以总体分类准确率较高,不过由图5可以看出,同为单一分类器的DT与SVM表现差别还是很明显;不过RF与XGBoost已经与SVM的表现相差无几,作者这里选取了1000个样本作为测试数据,0.98的含义是在1000个样本中有20个分类错误。
虽然RF、XGBoost的表现已经追上甚至赶超了SVM,但是作者认为“集成学习”的威力应该不止于此,由于这次运用的模型参数均为默认参数,所以作者在对RF、XGBoost的模型参数进行调试(这是个十分费力的过程)后又做了新一轮的预测,见证奇迹的时刻:

图6 调参后模型准确率
在整体预测率都较高的情况下,应用了“集成学习”思想的算法在准确度上还是实现了某种程度的碾压。
3 调参经验
从图6可以看出,对于RF与XGBoost模型的参数调整还是得到了正反馈的效果,所以针对具备编程经验或者感兴趣的同学,作者在这里简单介绍一下自己的调参经验:
①RF:参数较少,只有生成森林所需树的棵数(ntree)与节点分裂时所需的特征个数(mtry),作者选取交叉验证的方法由参数的初始值开始搜寻,最终由预先设定的判别表征(RMSE、MAPE…)来决定参数。
②XGBoost:参数很多(这也是此算法的一个缺点),具体的解释可以参考这篇文章http://blog.csdn.net/zc02051126/article/details/46711047, 这里不做冗余的介绍。 以下只列出作者在这个案例中主要调整的几个参数:max_depth、eta、min_child_weight,选用的方法依然是交叉验证进行参数遍历。值得一提的是,其中“min_child_weight”这一参数对于类别分布不平衡的问题十分重要,由于作者工作的领域与工业界接触较多,经常会遇到正负样本分布极不均匀(通常<1:10000)的情形,所以XGBoost这一算法在合适的调参后往往会有比较理想的表现。
4 运行时间对比
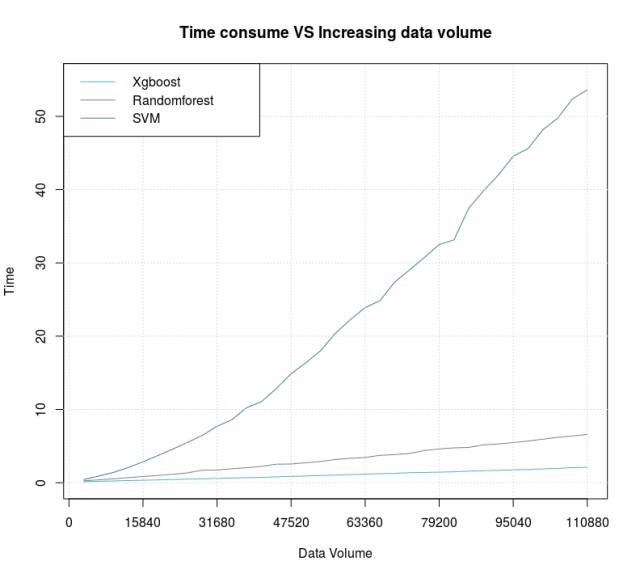
图 7 运行时间 VS 数据量
最后给出一个运行时间上的对比作为文章的结尾,作者以3000为跨度逐步增加数据的容量,可以看出“集成学习”的算法在运行速度上表现出了碾压级别的优势,可以说是又准又快的算法。