概述:
hive是什么呢?
(1).由Facebook开源,最初用于解决海量结构化的日志数据统计问题
(2).是一个构建在Hadoop之上的数据仓库 (虽然是数据仓库,但是它并不存储任何数据)
(3).Hive定义了一种类似于SQL查询语言:HQL(非常类似于MySQL中的SQL语句,同时做了扩展)
(4).通常用于离线数据处理(与MapReduce原理一样,只不过它是将HQL语句转换成MapReduce程序运行)
(5).可以认为是一个HQL=>MapReduce的语言翻译器
(6).底层支持多种不同的执行引擎(默认是MapReduce)
(7).支持不同的压缩格式、存储格式以及自定义函数
(8).Hive中的数据库及表就是HDFS中的目录/文件夹,数据是文件,元数据信息可以存储在任意的一个关系型数据库中(比如:MySQL、SqlServer、Oracle等,默认是Derby),数据存储在HDFS中
Hive的工作原理简单来说就是一个查询引擎
HIve构建于Hadoop集群之上
1)HQL中对查询语句的解释、优化、查询都是由HIve完成的
2)所有的数据都是存储在Hadoop(HDFS)中
3)HQL语句全部转化为MapReduce任务,在Hadoop中执行,当然也有一些没有MR任务的如:select * from A
4)Hadoop和HIve都是采用UTF-8来进行编码的
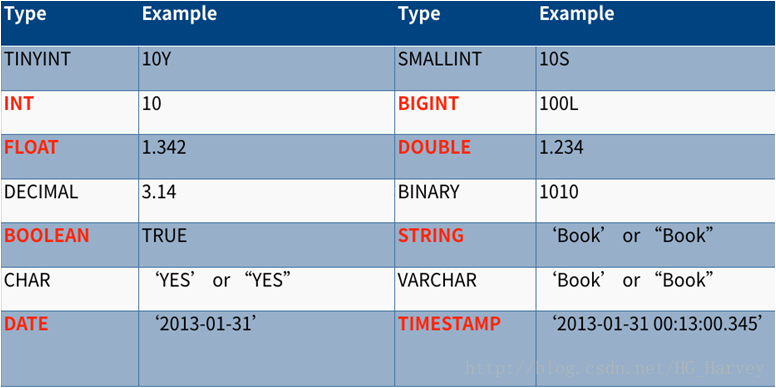
Hive中的基本数据类型
红色部分为最常用
Hive中的复杂数据类型
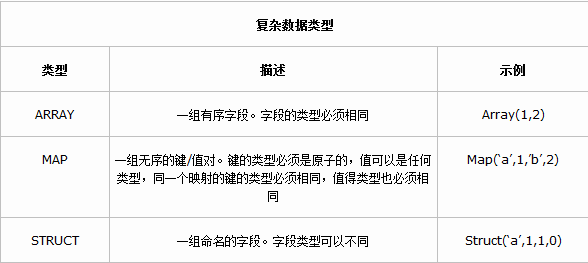
由上图可见,Hive中有三种复杂的数据类型:Array Map Struct 其中Array 和Map与Java中Array和Map相似,
而Struct与C语言中的Struct类型,它封装了一个命名字段的集合,复杂数据类型允许任意层次的嵌套。
复杂数据类型的声明必须用尖括号声明其中的数据类型,参考如下:
CREATE TABLE A(
col1 ARRAY< INT>,
col2 MAP< STRING,INT>,
col3 STRUCT< a:STRING,b:INT,c:DOUBLE>
)Hive架构图
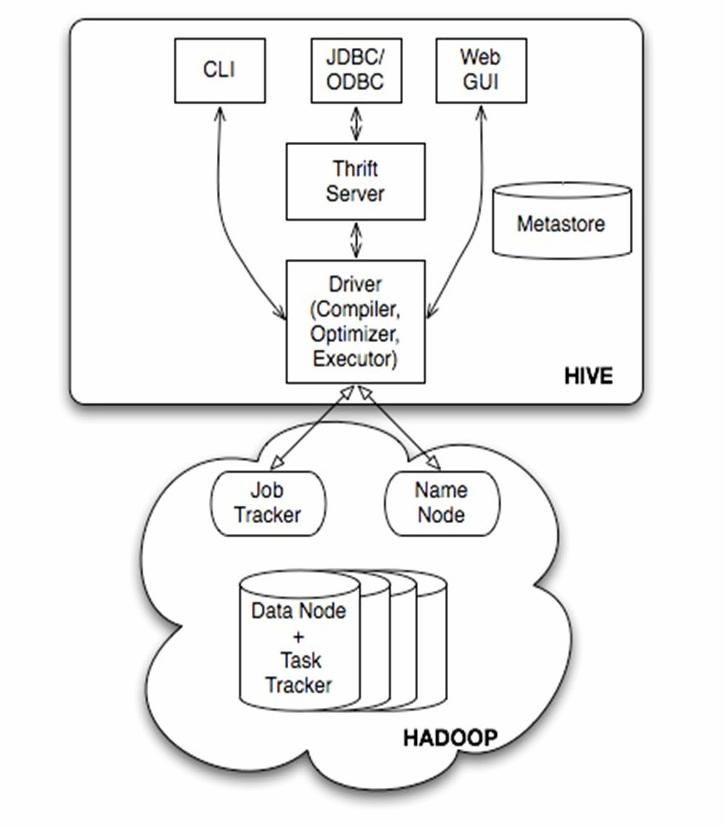
Hive结构体系主要分为以下几个部分:
(1)用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是CLI,Cli启动的时候,会同时启动一个Hive副本。Client是Hive的客户端,用户连接至Hive Server。在启动 Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。 WUI是通过浏览器访问Hive。
(2)Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
(3)解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
(4)Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。
Hive的执行命令:因为Hive是基于Hadoop之上的,我们首先启动Hadoop集群,然后去hive目录中bin/下的hiveserver2
[hadoop@Master hive]$ bin/hiveserver2hiveserver2启动后,我们再去启动beeline命令,远程服务(默认端口号 10000)
[hadoop@Master hive]$ bin/beeline -u jdbc:hive2://Master:10000 -n hadoophive的远程服务端口号也可以在hive-default.xml文件中配置,修改hive.server2.thrift.port对应的值即可。
< property>
< name>hive.server2.thrift.port< /name>
< value>10000< /value>
< description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.< /description>
< /property>Hive数据存储的概念:
1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
(1):db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
(2):table:在hdfs中表现所属db目录下一个文件夹
(3):external table:外部表, 与table类似,不过其数据存放位置可以在任意指定路径
普通表: 删除表后, hdfs上的文件都删了
External外部表删除后, hdfs上的文件没有删除, 只是把文件删除了
(4): partition:在hdfs中表现为table目录下的子目录
(5):bucket:桶, 在hdfs中表现为同一个表目录下根据hash散列之后的多个文件, 会根据不同的文件把数据放到不同的文件中
写到这里,我们开始真正进入到Hive来进行实际的操作,如果大家学过SQL语句的话会感觉到很简单,基本相同。
创建数据库:Create
Create databases mydb; //创建一个数据库 //对应的HDFS路径为:/user/hive/warehouse/mydb.db是否存在关键字:if not exists
create databases if not exists mydb;//如果此名称数据库不存在的话再创建查询数据库:show
show databases mydb;//查询mydb数据库模糊查询:
show databases like 'my*'//查询以my开头的数据库查看数据库的详细信息:desc
desc databases mydb; //查看详细信息desc database extended mydb; //查看详细信息使用此数据库:use
use mydb; //如果你想操作此数据库或者此库的表 必须要use这个库名 //如果不适用use 默认是default查看数据库的创建语句:
show create databases mydb; //会显示出这个库的创建语句删除数据库:drop
drop databases mydb; //这里要注意,如果这个库中有多个表,这也删除会报错,必须先将里面表删除再删库级联删除:cascade
drop databases if exists mydb cascade; //通过关键字Cascade进行级联删除,切记慎用。修改:alter //目前Hive并不支持数据库重命名,但是支持修改表名称。
创建表:
create table mystudent(id int,name string,age int) //字段和指明类型
row format delimited fields terminated by '\t'; //这里是告诉Hive数据中是什么分隔符将本地文件student.txt数据导入到student表中:
load data local inpath '/home/hadoop/data/student.txt' overwrite into table student;
//local表示本地文件导入
//overwrite覆盖该表数据
//into到你想要到的表中将HDFS中的student.txt文件导入到student表中:
load data inpath '/user/hadoop/student.txt'overwrite into student;
//去掉local文件导入Load:如果将本地文件导入到表中其实就是复制操作,源文件还存在。
如果从HDFS导入的话是剪切操作,HDFS文件会消失。
复制表:
create table stduent1 like student; //只复制student的表结构create table student1 as select * from student; //完全复制,表结构和数据create table stduent1 as select id,name from stduent; //只复制想要的数据 如ID Name查看表信息:desc
desc extended student; //详细信息desc formatted student; //使用formatted格式化查看,比上图各有结构感,常用。修改表名:alter
alter table student rename to student001; //将student表名修改为student001删除表:drop
drop table student; //删除此表清空表中数据:truncate
truncate table student; //清空student表中数据以上就是Hive表中最基础的操作,我们接下来要看复杂的数据类型:
我们创建一个带有数组的表:array
create table tb_array01(name string,work_array array<string>)
row format delimited fields terminated by '\t' //array前面数据是以tab分割的
collection items terminated by ','; //array中是以,分割数据的数据:如果你导入的数据为null的话 就vi编辑这个文件,将name 和后面地区缩在一起,重新Tab分割并保存就可以了。
zhangsan beijing,shanghai,tianjin,hangzhou
lisi changchu,chengdu,wuhan
导入数据:Load
load data local inpath '/home/hadoop/data/array.txt' overwrite into table tb_array01;结果:
+----------------+----------------------------------------------+
| tb_array.name | tb_array.work |
+----------------+----------------------------------------------+
| zhangsan | ["beijing","shanghai","tianjin","hangzhou"] |
| lisi | ["changchu","chengdu","wuhan"] |
+----------------+----------------------------------------------+练习:查询张三和李四第一个工作地点在哪
select name,work_array[0] from tb_array01; //[0]表示从第一个开始
结果:
+-----------+-----------+
| name | _c1 |
+-----------+-----------+
| zhangsan | beijing |
| lisi | changchu |
+-----------+-----------+
查询张三第二个工作地点:
select name,work_array[2] from tb_array01 where name ='zhangsan';
结果:
+-----------+----------+
| name | _c1 |
+-----------+----------+
| zhangsan | tianjin |
+-----------+----------+
查询所有人工作地区次数:
select name,size(work_array) from tb_array01; //用size函数查看某字段内的次数
结果:
+-----------+------+
| name | _c1 |
+-----------+------+
| zhangsan | 4 |
| lisi | 3 |
+-----------+------+建议读者先看提供的数据,然后分析这里面有什么类型,有哪些分隔符,然后自己去尝试建表
创建一个带有Map类型的表:Map
create table tb_map01(name string,score_map map<string,int>)
row format delimited fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':';
数据:
zhangsan math:80,chinese:89,english:95
lisi chinese:60,math:80,english:99
导入数据:Load
load data local inpath'/home/hadoop/data/map.txt'overwrite into table tb_map01;
结果:
+----------------+----------------------------------------+
| tb_map01.name | tb_map01.score_map |
+----------------+----------------------------------------+
| zhangsan | {"math":80,"chinese":89,"english":95} |
| lisi | {"chinese":60,"math":80,"english":99} |
+----------------+----------------------------------------+
练习:查询数据和英语的成绩
select name,score_map['english'],score_map['math'] from tb_map01;
结果:
+-----------+------+------+
| name | _c1 | _c2 |
+-----------+------+------+
| zhangsan | 95 | 80 |
| lisi | 99 | 80 |
+-----------+------+------+
创建一张带有结构体的表:Struct
create table tb_scruct01(ip string,name_age struct<name:string,age:int>)
row format delimited fields terminated by '#'
collection items terminated by ':';数据:
192.168.1.1#zhangsan:40
192.168.1.2#lisi:50
192.168.1.3#wangwu:60
192.168.1.4#zhaoliu:70
导入数据:Load
load data local inpath '/home/hadoop/data/struct.txt'overwrite into table tb_scruct01;
结果:
+-----------------+-------------------------------+
| tb_scruct01.ip | tb_scruct01.name_age |
+-----------------+-------------------------------+
| 192.168.1.1 | {"name":"zhangsan","age":40} |
| 192.168.1.2 | {"name":"lisi","age":50} |
| 192.168.1.3 | {"name":"wangwu","age":60} |
| 192.168.1.4 | {"name":"zhaoliu","age":70} |
+-----------------+-------------------------------+
好了以上就是Hive中三个复杂的数据类型 其实也没什么难得 先观察数据,什么样数据用什么数据类型就可以了。
内部表外部表讲解:
所谓的内部表就是我们创建的普通表,那么它的数据会存储在HDFS/user/hive/warehouse中,元数据存储在Mysql关系型数据库中,被Hive全部管理,删除该表,元数据和HDFS上的数据会全部被删除。
外部表它不被Hive全部管理,因为你删除这个表的时候,元数据可以删除,可是HDFS上的数据你无法删除,因为这个数据可以存放在HDFS中任何目录中,使用你只需要Location指定此数据路径即可。
外部表是再HDFS中已经有数据了,为了用Hive进行分析,在数据不改变的情况下,创建一个外部表
直接指向一个已经存在的文件。
创建一个外部表 :
用关键字:external
指定分隔符:row format delimited fields terminated by '\t'
指定hdfs上的数据:location '/user/hadoop/student';
将本地Student文件上传到HDFS中
create external table waibu_student(id int,name string,age int,sex string)
row format delimited fields terminated by '\t'location '/user/hadoop/student';数据:
1001 zhangsan 18 f
1002 wangwu 20 m
1003 zhaoliu 21 f
结果:
+-------------------+---------------------+--------------------+--------------------+
| waibu_student.id | waibu_student.name | waibu_student.age | waibu_student.sex |
+-------------------+---------------------+--------------------+--------------------+
| 1001 | zhangsan | 18 | f |
| 1002 | wangwu | 20 | m |
| 1003 | zhaoliu | 21 | f |
| NULL | | NULL | |
+-------------------+---------------------+--------------------+--------------------+
练习:
查询年纪大于10但是小于21的数据:
select * from waibu_student where age between 10 and 21;查询前两条数据:
select * from waibu_student limit 2;查询年龄大于18的有多少:此语句跑MapReduce任务
select count(*) from waibu_student where age>18;查询年龄最大,最小,平均 和年龄总和:MR任务
select max(age),min(age),avg(age),sum(age)from waibu_student;Hive中的分区与分桶:
概述:
在hive select查询中,一般情况下,hive会扫描整个表的内容,会消耗很多不必要的时间,因为我们可能不需要全部的数据,因此建表就有了partition(分区)的概念,也就是在创建表的时候建立分区的空间。
hive可以根据某列或者多个列进行分区管理,举个例子:
当前互联网的应用每天都会产生很多的日志文件,几G 几十G甚至更大,我们需要根据日期来存放日志信息,那我们就在产生分区的时候根据日志产生的日期进行分区,每天的日志都放入对应的日期分区中。
将数据进行分区,就是为了提高我们的查询效率。
分区中的分区列是不存在于表中的,但是查询是可以查到的。
分区中不能有中文(web开发中都需要转编码,但是Hive中不支持转码,也就是不支持汉字)
实现细节:
1)一个表可以拥有一个或多个分区,每个分区以文件夹的形式单独存储在表文件夹目录下
2)表和列明不区分大小写
3)分区是以字段的形式在标结构中存在,我们可以通过 show partitions tables 查看表内分区的存在,但是该字段不存储任何数据,在表中也是不实际存在的,仅仅作为分区的表示而已
4)对于分区来说我们不建议直接select *查询,性能低,可能不需要的数据也会被查出,查询添加 where month='2018-08',
这也的话会直接在这个分区内查询数据而不会去查询别处。
实例演示:
创建表,并创建一个分区:
create table partition_order(number string,time string)
partitioned by (month string) //关键字 partitioned by 指定创建的分区列
row format delimited fields terminated by '\t';
数据:
10703007267488 2014-05-01 06:01:12.334+01
10101043505096 2014-05-01 07:28:12.342+01
10103043509747 2014-05-01 07:50:12.33+01
10103043501575 2014-05-01 09:27:12.33+01
10104043514061 2014-05-01 09:03:12.324+01
导入数据,并存在哪个分区下:
load data local inpath '/home/hadoop/data/order.txt' overwrite into table partition_order partition(month='2018-08');
//这里导入数据的时候需要指定放入哪个分区列,如果不指定会报需要指定分区列,因该表是分区状态
我们也可以通过alter往表中添加分区:
alter table partition_order add
partition(month=2019)
partition(month=2020); //通过add可以添加多个分区
查看该表内有多少个分区:
show partitions partition_order;从一个分区中查询数据:
select * from partition_order where month ='2018-08'; 动态分区:
如果用上述的静态分区,插入的时候必须首先要知道有什么分区类型,而且每个分区写一个load data,太麻烦。使用动态分区可解决以上问题,其可以根据查询得到的数据动态分配到分区里。其实动态分区与静态分区区别就是不指定分区目录,由系统自己选择。
开启动态分区(默认为false,不开启)
SET hive.exec.dynamic.partition=true;指定动态分区模式,默认为strict,即必须指定至少一个分区为静态分区。
SET hive.exec.dynamic.partition.mode=nonstrict;
//nonstrict模式表示允许所有的分区字段都可以使用动态分区。假设我有一张person01表,内容如下:sex和 time为分区列
+----------------+---------------+---------------+----------------+
| person01.name | person01.nat | person01.sex | person01.time |
+----------------+---------------+---------------+----------------+
| lily | china | man | 2018-08-24 |
| nancy | china | man | 2018-08-24 |
| hanmeimei | america | man | 2018-08-24 |
| jan | china | man | 2018-08-29 |
| mary | america | man | 2018-08-29 |
| lilei | china | man | 2018-08-29 |
| heyong | china | man | 2018-08-29 |
| yiku | japan | man | 2018-08-29 |
| emmoji | japan | man | 2018-08-29 |
+----------------+---------------+---------------+----------------+
我把这张表的数据插入到person2表中,并将sex='man‘作为静态分区,time日期让系统自动分配决定
insert overwrite table person01 partition(sex='man',time)
> select name, nat, time from person03;再次查看分区
show partitions person03;
OK
sex=man/time=2018-08-24
sex=man/time=2018-08-29
Time taken: 0.065 seconds, Fetched: 2 row(s)证明动态分区成功。
Hive分桶:
对于我们没一张表或者分区,hive可以进一步组织成分桶,桶就是更细微的数据范围划分,针对某一个存在的列进行分桶,采用对列值哈希,然后除以桶的个数求余解决该条记录存储在哪个桶中。
把表或分区组织成桶(Bucket)有如下理由:
1)抽样查询,对于非常大的数据据,用户不需要将数据全部查询出来。
2)获得更高的查询效率,使用抽样更高效 ,为了取样,做表连接。
开启强制分桶 :
SET hive.enforce.bucketing = true //在hive2版本后都默认为true了,不需要更改创建带桶(Bucket)的tabe
在这里,我们使用用户ID来确定如何划分桶(Hive使用对值进行哈希并将结果除 以桶的个数取余数
create table bucketed_user(id int,name string) clustered by (id) into 4 buckets;
//clustered by :指定按照哪个列进行分桶 into 4 buckets:分成四个桶桶中的数据可以根据一个或多个列另外进行排序。由于这样对每个桶的连接变成了高效的归并排序。因此可以进一步提升map端连接的效率。以下语法声明一个表使其使用排序桶:
create table bucketd_uses (id int,name string)
clustered by (id) sorted by (id ASC) into 4 buckets;分桶必须用insert 不能使用Load 因为insert是将数据散列到不同的文件里 load是将文件复制
分桶详解:
SELECT * FROM table_name TABLESAMPLE(BUCKET 3 OUT OF 32 ON ID);
//3:第几个桶 32: 32/3 按照几分之几在桶里随机取样
X OF Y
X:从第几个桶开始抽取数据
Y:表示隔几个桶取一个桶
每个桶中如何抽取数据是由总 分桶数除以Y 乘桶中数据
例如:
10个桶 第一个桶中有10条数据
1 of 10 //在第一个桶和第11个桶中取 10/10*10的数据 由于没有第11个桶 所以取得了第一个桶中的10条数据
1 of 20 //在第一个桶和第21个桶中取 10/20*10的数据 由于没有21的 所以取得了第一个桶中的五条数据 随机
2 of 5 //在第二个桶中和第七个桶,12个桶中取 10/5*10 Hive自定义函数 UDF
内置函数:
我们通过如下代码可以查看Hive中提供的内置函数
show functions; //查看所有函数内置可根据desc查看使用方法,在这就不列举。
内置函数:
我们需要导入如下两个Jar包
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.6</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.3.0</version>
</dependency>我们这里做一个取邮箱@后面的数据
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class GetHostUDF extends UDF{ //继承UDF接口
public Text evaluate(Text email){ //方法名必须是evaluate 因为是通过反射找这个名字
String e = email.toString(); //将email转为string类型
String r = e.substring(e.indexOf('@')+1); //+1 一直取到最后
return new Text(r);
}
}我们往表里导入一些测试数据,如下:
0: jdbc:hive2://Master:10000> select * from email;
+-------------------+
| email.email |
+-------------------+
| [email protected] |
| [email protected] |
| [email protected] |
| [email protected] |
+-------------------+
我们通过IDEA将代码打包,然后通过rz命令或者远程工具将jar包放入Linux文件夹内
然后再Hive中通过命令放入Jar包
add jar /home/hadoop/jar/com.hadoop.hive.udf-1.0-SNAPSHOT.jar
//add jar 你jar包存放的路径放入之后我们查看放入的Jar包
0: jdbc:hive2://Master:10000> list jars;
+----------------------------------------------------+
| resource |
+----------------------------------------------------+
| /home/hadoop/jar/com.hadoop.hive.udf-1.0-SNAPSHOT.jar |
+----------------------------------------------------+
然后我们创建函数
create function gethost as 'hiveudf.GetHostUDF';使用创建的gethost函数查询
0: jdbc:hive2://Master:10000> select email,gethost(email)as host from email;
+-------------------+------------+
| email | host |
+-------------------+------------+
| [email protected] | 163.com |
| [email protected] | qq.com |
| [email protected] | gmail.com |
| [email protected] | 126.com |
+-------------------+------------+
如上图我们已经通过我们自己编写的函数来查询数据