1. 数据类型
官网文档:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types
| Hive数据类型 | 长度 | 例子 |
|---|---|---|
| TINYINT | -128 to 127 | 20 |
| SMALINT | -32,768 to 32,767 | 20 |
| INT | -2,147,483,648 to 2,147,483,647 | 20 |
| BIGINT | -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 | 20 |
| BOOLEAN | 布尔类型 | TRUE FALSE |
| FLOAT | 4-byte single precision floating point number | 3.14159 |
| DOUBLE | 8-byte double precision floating point number | 3.14159 |
| STRING | 字符 | ‘lalal” |
| TIMESTAMP | 时间 | |
| DATE | 时间 | |
| BINARY | 字节数组 |
复杂类型数据:
arrays: ARRAY<data_type> (Note: negative values and non-constant expressions are allowed as of Hive 0.14.)
maps: MAP<primitive_type, data_type> (Note: negative values and non-constant expressions are allowed as of Hive 0.14.)
structs: STRUCT<col_name : data_type [COMMENT col_comment], …>
2. DDL
2.1 create table
创建的表和分区信息分别存储在元数据库的tbls和partitions中
mysql> select * from tbls;
+--------+-------------+-------+------------------+-------+------------+-----------+-------+-----------------+----------------+--------------------+--------------------+
| TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | OWNER_TYPE | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT |
+--------+-------------+-------+------------------+-------+------------+-----------+-------+-----------------+----------------+--------------------+--------------------+
| 8 | 1577179125 | 6 | 0 | wzj | USER | 0 | 8 | test_w | EXTERNAL_TABLE | NULL | NULL |
| 9 | 1577179135 | 6 | 0 | wzj | USER | 0 | 9 | test_n | EXTERNAL_TABLE | NULL | NULL |
| 10 | 1577179616 | 6 | 0 | wzj | USER | 0 | 10 | test_cpy | MANAGED_TABLE | NULL | NULL |
| 11 | 1577179667 | 6 | 0 | wzj | USER | 0 | 11 | test_copy | MANAGED_TABLE | NULL | NULL |
| 12 | 1577181315 | 6 | 0 | wzj | USER | 0 | 12 | emp | MANAGED_TABLE | NULL | NULL |
| 16 | 1577243920 | 6 | 0 | wzj | USER | 0 | 16 | partitiom_test | MANAGED_TABLE | NULL | NULL |
| 17 | 1577252656 | 6 | 0 | wzj | USER | 0 | 18 | order_partition | MANAGED_TABLE | NULL | NULL |
+--------+-------------+-------+------------------+-------+------------+-----------+-------+-----------------+----------------+--------------------+--------------------+
7 rows in set (0.00 sec)
mysql> select * from partitions;
+---------+-------------+------------------+--------------------------+-------+--------+
| PART_ID | CREATE_TIME | LAST_ACCESS_TIME | PART_NAME | SD_ID | TBL_ID |
+---------+-------------+------------------+--------------------------+-------+--------+
| 1 | 1577244373 | 0 | month=20191101/org=henan | 17 | 16 |
| 2 | 1577252735 | 0 | event_month=2014-05 | 19 | 17 |
+---------+-------------+------------------+--------------------------+-------+--------+
2 rows in set (0.00 sec)
- 默认创建的是内部表
- 内部表删除时: HDFS + META 都被删除
- 外部表删除时: HDFS不删除 仅META被删除
CREATE [EXTERNAL(外部表)] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type # 列的名称及类型 [column_constraint_specification] # 列的约束 [COMMENT col_comment], ...# 列的注释
[constraint_specification])] # 表的约束
[COMMENT table_comment]表的注释
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]# 分区
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]#创建分桶表
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format] #表中分隔符
[STORED AS file_format] #常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE#
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]#指定表在hdfs上的位置
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
2.1.1 内部表创建和删除
hive (wzj)> create table test(id int,name string);
OK
Time taken: 0.126 second
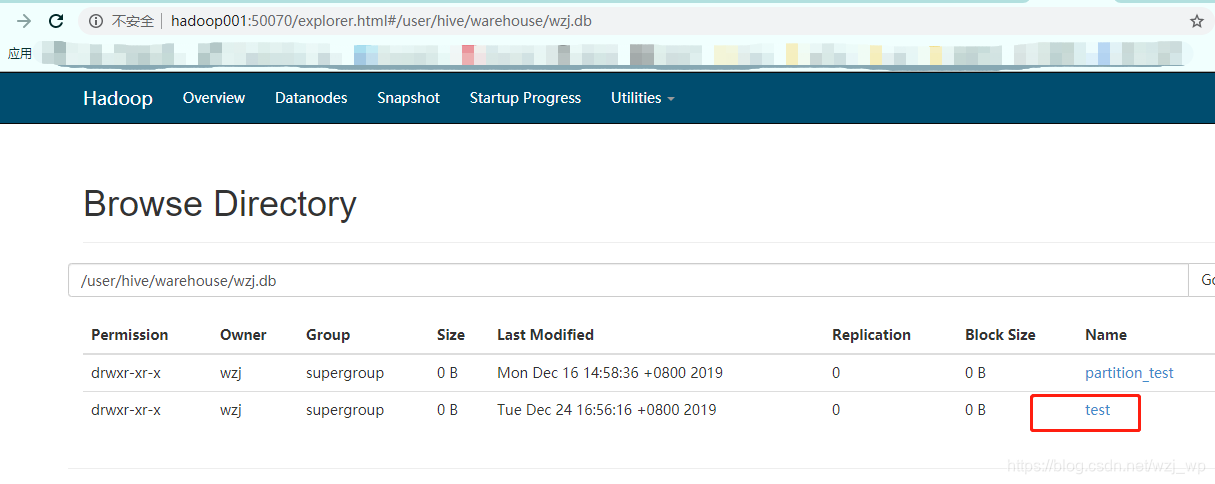
hive (wzj)> drop table test;
OK
Time taken: 0.27 seconds
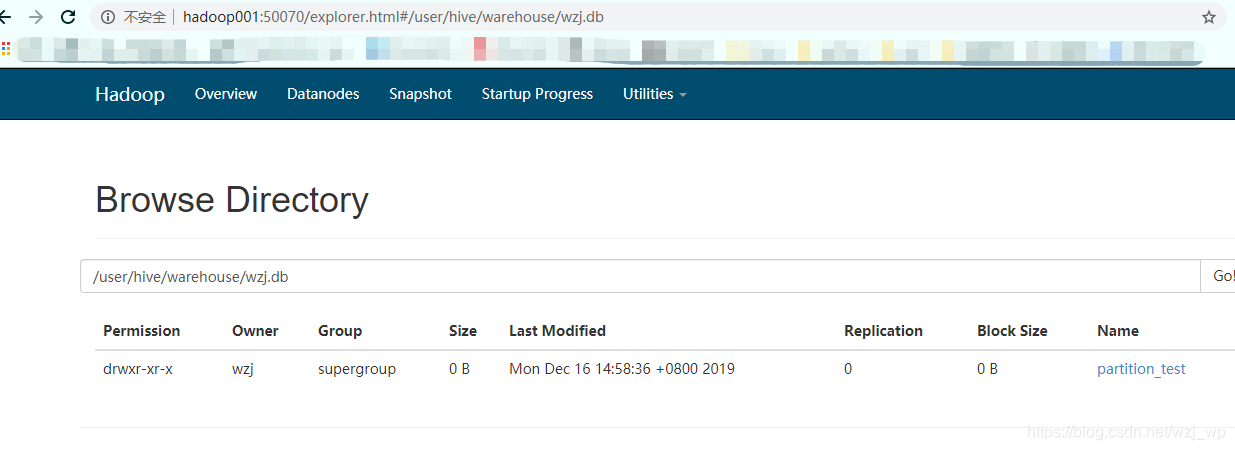
2.1.2 外部表创建和删除
hive (wzj)> create external table test(id int,name string);
OK
Time taken: 0.143 seconds
hive (wzj)> drop table test;
OK
Time taken: 0.128 seconds
hive (wzj)>
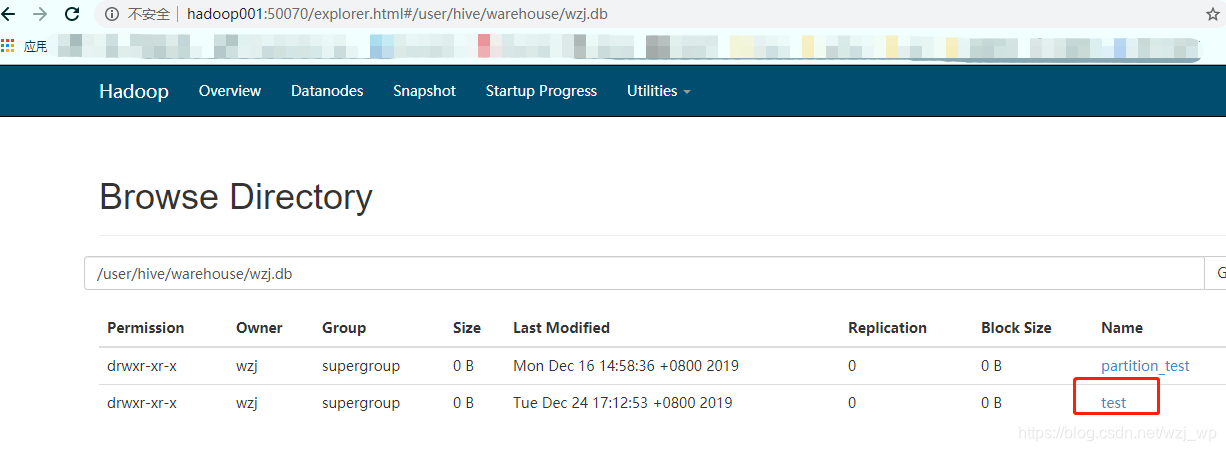
删除之后文件依然在!
2.1.3 内部表和外部表的转换
hive (wzj)> desc formatted test_n;
Table Type: MANAGED_TABLE
修改类型

hive (wzj)> alter table test_n set tblproperties(‘EXTERNAL’=‘TRUE’);
OK
Time taken: 0.142 seconds
hive (wzj)> desc formatted test_n;
Table Type: EXTERNAL_TABLE
外部表转内部表:(‘EXTERNAL’=‘TRUE’)
(‘EXTERNAL’=’TRUE’)和(‘EXTERNAL’=’FALSE’)为固定写法,区分大小写
2.1.4 快速建表之仅复制表结构&复制表结构和数据
仅复制表结构
hive (wzj)> create table test_cpy like test_n;
OK
Time taken: 0.187 seconds
复制表结构和数据
hive (wzj)> create table test_copy as select * from test_n;
Query ID = wzj_20191224172727_a68c19a0-a2ad-492a-ae66-27b95cd9fcb7
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there’s no reduce operator
Starting Job = job_1577150260007_0003, Tracking URL = http://hadoop001:38088/proxy/application_1577150260007_0003/
Kill Command = /home/wzj/app/hadoop/bin/hadoop job -kill job_1577150260007_0003
2.2 分区表
分区表 : 分区其实对应的就是HDFS上的一个文件夹/目录
分区列并不是一个“真正的”表字段,其实是HDFS上表对应的文件夹下的一个文件夹
- 3.2.1 分区表创建,加载数据
create table partitiom_test
(id int,
name string)
partitioned by (month string,org string)
row format delimited fields terminated by ‘,’

LOAD DATA LOCAL INPATH ‘/home/wzj/data/partitiontest.txt’ INTO TABLE partition_test PARTITION (month=‘20191101’,org=‘henan’)
- 3.2.2 分区表注意事项:
-
- 分区表已经建好,直接建立一个分区目录,并上传数据
此方式一定不要用,刷新的操作太重量级了
- 分区表已经建好,直接建立一个分区目录,并上传数据
hive (wzj)> create table order_partition(
> order_no string,
> event_time string
> )
> PARTITIONED BY (event_month string)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
OK
Time taken: 0.151 seconds
[wzj@hadoop001 data]$ hadoop fs -mkdir /user/hive/warehouse/wzj.db/order_partition/event_month=2014-06
19/12/25 13:54:36 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[wzj@hadoop001 data]$ hadoop fs -put order_created.txt /user/hive/warehouse/wzj.db/order_partition/event_month=2014-06/
19/12/25 13:55:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
hive (wzj)> select * from order_partition where event_month='2014-06';
OK
order_partition.order_no order_partition.event_time order_partition.event_month
Time taken: 0.088 seconds
hive (wzj)>
此时发现查询不到数据
是因为元数据库并没有我们此分区信息
mysql> select * from partitions;
+---------+-------------+------------------+--------------------------+-------+--------+
| PART_ID | CREATE_TIME | LAST_ACCESS_TIME | PART_NAME | SD_ID | TBL_ID |
+---------+-------------+------------------+--------------------------+-------+--------+
| 1 | 1577244373 | 0 | month=20191101/org=henan | 17 | 16 |
| 2 | 1577252735 | 0 | event_month=2014-05 | 19 | 17 |
+---------+-------------+------------------+--------------------------+-------+--------+
2 rows in set (0.00 sec)
此时需要刷一下元数据,注意看刷新之后的信息显示‘2014-06’分区不存在,进行一个added的操作之后,去mysql查询,分区信息已经有了:
hive (wzj)> msck repair table order_partition;
OK
Partitions not in metastore: order_partition:event_month=2014-06
Repair: Added partition to metastore order_partition:event_month=2014-06
Time taken: 0.31 seconds, Fetched: 2 row(s)
----------------------------------------------------
mysql> select * from partitions;
+---------+-------------+------------------+--------------------------+-------+--------+
| PART_ID | CREATE_TIME | LAST_ACCESS_TIME | PART_NAME | SD_ID | TBL_ID |
+---------+-------------+------------------+--------------------------+-------+--------+
| 1 | 1577244373 | 0 | month=20191101/org=henan | 17 | 16 |
| 2 | 1577252735 | 0 | event_month=2014-05 | 19 | 17 |
| 3 | 1577254372 | 0 | event_month=2014-06 | 20 | 17 |
+---------+-------------+------------------+--------------------------+-------+--------+
3 rows in set (0.00 sec)
mysql>
再查一下hive中的数据已经有了:
hive (wzj)> select * from order_partition where event_month=‘2014-06’;
OK
order_partition.order_no order_partition.event_time order_partition.event_month
10703007267488 2014-05-01 06:01:12.334+01 2014-06
10101043505096 2014-05-01 07:28:12.342+01 2014-06
10103043509747 2014-05-01 07:50:12.33+01 2014-06
10103043501575 2014-05-01 09:27:12.33+01 2014-06
10104043514061 2014-05-01 09:03:12.324+01 2014-06
Time taken: 0.144 seconds, Fetched: 5 row(s)
hive (wzj)>
-
- 数据上传之后,增加分区
[wzj@hadoop001 data]$ hadoop fs -mkdir -p /user/hive/warehouse/wzj.db/order_partition/event_month=2014-07
19/12/25 14:19:37 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[wzj@hadoop001 data]$ hadoop fs -put order_created.txt /user/hive/warehouse/wzj.db/order_partition/event_month=2014-07/
19/12/25 14:19:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[wzj@hadoop001 data]$
hive (wzj)> ALTER TABLE order_partition ADD IF NOT EXISTS PARTITION(event_month='2014-07');
OK
Time taken: 0.148 seconds
hive (wzj)> select * from order_partition where event_month='2014-07';
OK
order_partition.order_no order_partition.event_time order_partition.event_month
10703007267488 2014-05-01 06:01:12.334+01 2014-07
10101043505096 2014-05-01 07:28:12.342+01 2014-07
10103043509747 2014-05-01 07:50:12.33+01 2014-07
10103043501575 2014-05-01 09:27:12.33+01 2014-07
10104043514061 2014-05-01 09:03:12.324+01 2014-07
Time taken: 0.104 seconds, Fetched: 5 row(s)
单个分区,一层目录,多个分区,多层目录
使用分区表时,加载数据一定要指定我们的所有分区字段
2.3 修改 删除 查看常用命令
显示所有数据库:show databases;
切换数据库:use dbname;
展示当前数据库下所有表:show tables;
创建数据库:create databases XXX;
数据库默认路径:hdfs://hadoop001:9000/user/hive/warehouse/wzj.db
删除数据库:drop database XXX;
创建表:create table table_name(id int,name string,)
查看表结构:desc table;
查看表结构和详细信息:desc formatted table;
表名重命名:ALTER TABLE table_name RENAME TO new_table_name
删除表数据:truncate table XXX;
删除表:drop table XXX;
3. DML
3.1 数据导入
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
load data: 表示加载数据
local: 表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
inpath: 表示加载数据的路径
overwrite: 表示覆盖表中已有数据,否则表示追加
into table: 表示加载到哪张表
student: 表示具体的表
partition: 表示上传到指定分区
- 从本地加载数据
hive (wzj)> load data local inpath '/home/wzj/data/emp.txt' overwrite into table emp;
Loading data to table wzj.emp
Table wzj.emp stats: [numFiles=1, numRows=0, totalSize=699, rawDataSize=0]
OK
Time taken: 0.338 seconds
- 从HDFS加载数据
需要注意的是,这种加载方式会把hdfs上原路径的文件加载到我们hive表的路径下,原数据就不存在了
先上传一份数据:
[wzj@hadoop001 data]$ hadoop fs -mkdir -p /user/hive/warehouse/
19/12/25 15:42:00 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[wzj@hadoop001 data]$ hadoop fs -put emp.txt /user/hive/warehouse/
19/12/25 15:42:23 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[wzj@hadoop001 data]$
hive (wzj)> truncate table emp;
OK
Time taken: 0.196 seconds
hive (wzj)> select * from emp;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
Time taken: 0.074 seconds
hive (wzj)> load data inpath '/user/hive/warehouse/emp.txt' into table emp;
Loading data to table wzj.emp
Table wzj.emp stats: [numFiles=1, numRows=0, totalSize=699, rawDataSize=0]
OK
Time taken: 0.359 seconds
hive (wzj)> select * from emp;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
- 通过复制表创建数据
create table xxx as select …
表不能事先存在
hive (wzj)> create table emp2 as select empno,enname from emp;
FAILED: SemanticException [Error 10004]: Line 1:34 Invalid table alias or column reference 'enname': (possible column names are: empno, ename, job, mgr, hiredate, sal, comm, deptno)
hive (wzj)> create table emp2 as select empno,ename from emp;
Query ID = wzj_20191225155656_8e6d321d-720c-4b9e-b0ea-34542775d580
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1577150260007_0007, Tracking URL = http://hadoop001:38088/proxy/application_1577150260007_0007/
Kill Command = /home/wzj/app/hadoop/bin/hadoop job -kill job_1577150260007_0007
hive (wzj)> select * from emp2;
OK
emp2.empno emp2.ename
7369 SMITH
7499 ALLEN
7521 WARD
7566 JONES
7654 MARTIN
- insert 插入数据
跟create不同的是这个必须表是事先存在的!
hive (wzj)> create table emp3 like emp;
OK
Time taken: 0.18 seconds
hive (wzj)> insert overwrite table emp3 select * from emp;
Query ID = wzj_20191225160101_f204f01b-697a-4d02-9afd-0dc03d650f61
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1577150260007_0008, Tracking URL = http://hadoop001:38088/proxy/application_1577150260007_0008/
Kill Command = /home/wzj/app/hadoop/bin/hadoop job -kill job_1577150260007_0008
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2019-12-25 16:01:29,965 Stage-1 map = 0%, reduce = 0%
2019-12-25 16:01:38,886 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.56 sec
MapReduce Total cumulative CPU time: 1 seconds 560 msec
Ended Job = job_1577150260007_0008
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://hadoop001:9000/user/hive/warehouse/wzj.db/emp3/.hive-staging_hive_2019-12-25_16-01-18_839_6498955607377706277-1/-ext-10000
Loading data to table wzj.emp3
Table wzj.emp3 stats: [numFiles=1, numRows=15, totalSize=708, rawDataSize=693]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.56 sec HDFS Read: 5093 HDFS Write: 773 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 560 msec
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
Time taken: 21.454 seconds
hive (wzj)> select * from emp3;
OK
emp3.empno emp3.ename emp3.job emp3.mgr emp3.hiredate emp3.sal emp3.comm emp3.deptno
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
3.1 数据导出
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format] (Note: Only available starting with Hive 0.11.0)
SELECT ... FROM ...
- 写入本地
不指定分隔符:
INSERT OVERWRITE LOCAL DIRECTORY ‘xxx’ select * from table;
hive (wzj)> INSERT OVERWRITE LOCAL DIRECTORY '/home/wzj/data/hivetmp' select * from emp;
Query ID = wzj_20191225161919_6ae40b9d-e77a-4b91-b62b-366f31f2d828
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1577150260007_0009, Tracking URL = http://hadoop001:38088/proxy/application_1577150260007_0009/
Kill Command = /home/wzj/app/hadoop/bin/hadoop job -kill job_1577150260007_0009
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2019-12-25 16:19:46,889 Stage-1 map = 0%, reduce = 0%
2019-12-25 16:19:54,803 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.23 sec
MapReduce Total cumulative CPU time: 1 seconds 230 msec
Ended Job = job_1577150260007_0009
Copying data to local directory /home/wzj/data/hivetmp
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.23 sec HDFS Read: 4851 HDFS Write: 708 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 230 msec
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
Time taken: 19.162 seconds
hive (wzj)>
[wzj@hadoop001 data]$ ll
total 16
-rw-r--r--. 1 wzj wzj 699 Dec 20 14:43 emp.txt
drwxrwxr-x. 2 wzj wzj 43 Dec 25 16:19 hivetmp
-rw-rw-r--. 1 wzj wzj 93 Dec 2 18:03 name.log
-rw-r--r--. 1 wzj wzj 213 Dec 20 14:43 order_created.txt
-rw-r--r--. 1 wzj wzj 94 Dec 25 11:22 partitiontest.txt
[wzj@hadoop001 data]$ cd hivetmp
[wzj@hadoop001 hivetmp]$ ll
total 4
-rw-r--r--. 1 wzj wzj 708 Dec 25 16:19 000000_0
[wzj@hadoop001 hivetmp]$
如果不指定分隔符,则为默认:
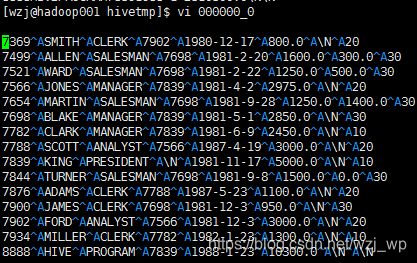
指定分隔符:
INSERT OVERWRITE LOCAL DIRECTORY ‘xxx’ ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ SELECT * FROM emp;
hive (wzj)> INSERT OVERWRITE DIRECTORY '/home/wzj/data/hivetmp' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' SELECT * FROM emp;
Query ID = wzj_20191225162323_6075017c-4351-49a9-95b9-e1931ed2ff93
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1577150260007_0010, Tracking URL = http://hadoop001:38088/proxy/application_1577150260007_0010/
Kill Command = /home/wzj/app/hadoop/bin/hadoop job -kill job_1577150260007_0010
- 写入HDFS
就是去掉local就可以
hive (wzj)> INSERT OVERWRITE DIRECTORY '/home/wzj/data' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' SELECT * FROM emp;
[wzj@hadoop001 data]$ hadoop fs -ls /home/wzj/data
19/12/25 16:30:40 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rwxr-xr-x 1 wzj supergroup 708 2019-12-25 16:28 /home/wzj/data/000000_0
[wzj@hadoop001 data]$ hadoop fs -text /home/wzj/data/000000_0
19/12/25 16:31:26 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
7369 SMITH CLERK 7902 1980-12-17 800.0 \N 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 \N 20
get 到本地看一眼
[wzj@hadoop001 hivetmp]$ hadoop fs -get /home/wzj/data/000000_0 hivetmp
19/12/25 16:37:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[wzj@hadoop001 hivetmp]$ ll
total 8
-rw-r--r--. 1 wzj wzj 708 Dec 25 16:32 000000_0
-rw-r--r--. 1 wzj wzj 708 Dec 25 16:37 hivetmp
[wzj@hadoop001 hivetmp]$ cat hivetmp
7369 SMITH CLERK 7902 1980-12-17 800.0 \N 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
- hive命令导出
hive -e ‘select * from dbname;’ > filepath
[wzj@hadoop001 hivetmp]$ hive -e 'select * from wzj.emp;' > /home/wzj/data/hivetmp/ce.txt
which: no hbase in (/home/wzj/app/sqoop/bin:/home/wzj/app/hive/bin:/home/wzj/app/hadoop/bin:/home/wzj/app/hadoop/sbin:/usr/java/jdk1.8.0_45/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/wzj/.local/bin:/home/wzj/bin)
19/12/25 16:42:17 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Logging initialized using configuration in jar:file:/home/wzj/app/hive-1.1.0-cdh5.16.2/lib/hive-common-1.1.0-cdh5.16.2.jar!/hive-log4j.properties
OK
Time taken: 9.734 seconds, Fetched: 15 row(s)
[wzj@hadoop001 hivetmp]$ ll
total 12
-rw-r--r--. 1 wzj wzj 708 Dec 25 16:32 000000_0
-rw-rw-r--. 1 wzj wzj 811 Dec 25 16:42 ce.txt
-rw-r--r--. 1 wzj wzj 708 Dec 25 16:37 hivetmp
