一、编码概念
编码:使用一个或多个字节表示特点的符号。
1、最早使用的是ASCII编码,也即1个字节表示常用的英文字母和符号;
2、然后为了表示中文,出现了gbk等中文编码方式,gbk兼容ASCII,使用2个字节表示待编码符号;
3、然后出现了其他的国家的编码方式;
4、为了表示各个国家的文字符号,国际统一标准组织提出了Unicode编码方式,使用4个字节来表示待编码符号;
5、UTF-8(Unicode TransformationFormat)作为Unicode的一种实现方式,广泛应用于互联网,它是一种变长的字符编码,可以根据具体情况用1-4个字节来表示一个字符。
二、系统默认字符编码
1、Linux系统默认字符编码方式为utf-8,而Windows中文发行版的系统默认字符编码方式为gbk(国内比较典型的应用场景)。
在Windows终端中输入:a=’好’,如下图:

在Linux终端中输入:a=’好’,如下图:

分析:终端会把中文输入根据系统平台的系统默认字符编码方式把中文字符编码为对应的字节表示,在Windows,‘好’字的gbk对应字节表示为bac3;而在Linux,‘好’字的utf-8对应字节表示为e5a5bd。
2、同样,对于Python的py文件,当文件中包含中文字符时,首先要把文件保存为utf-8格式,这样生成的文件中,中文字符才会被编码为utf-8字节表示,而在文件的头部,还要加上:
# coding : utf-8
或者是:
# -*- coding:utf-8-*-
这样Python解释器在加载该py文件时,才会使用utf-8对文件进行解码,否则会使用ASCII进行解码,这样ASCII对中文字符对应的utf-8的字节表示将无法正确解码,从而报错。
三、Python 2.x字符串(主要是str和unicode类型字符串)
str类型字符串相当于字节流,当我们得到一个str类型字符串时,相当于收到了一堆符号的字节表示,但至于是把它当做是gbk(每两个字节解读)还是utf-8(不等长的解读)还是其它的编码方式解读呢?也就是我们应该怎么去解码这一个字节流呢?
str类型字符串(字节流)的解码需要调用其decode(‘decode_method’)方法,当该字节流能够按照decode_method类型进行解码时,返回对应的Unicode字符串,否则抛出解码错误异常。
注意:如果调用decode方法时不指出decode_method,则decode会使用默认的Python默认的编码方法,也即ASCII方法,如下图:
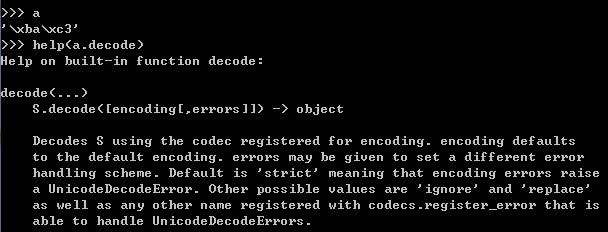

例如对于第二节中的例子:
在Windows终端:

在Linux终端:

Unicode类型字符串其实也相当于字节流,但是这个字节流必须4个字节4个字节地读。
Unicode类型字符串可以使用encode(encode_method)方便地将Unicode字符串转化为指定编码格式的str类型字符串,当然encode_method要能正确地表示相应的符号,例如Unicode字符串中如果包含ASCII编码以外的符号(如中文),则encode_method不能为ASCII。
例如:
在Windows和Linux终端:

str类型字符串和Unicode类型字符串的关系:

也即:
str ---------------> unicode:s.decode(decode_method)
unicode -----------------> str:u.encode(encode_method)
对于Unicode形式的str类型字符串,例如:s = ‘\u597d’,要转换成Unicode类型字符串,需要使用:s.decode(‘unicode-escape’),例如:
