知识引入
这一小节我们将分享数据的准备。在所有机器学习的项目中,数据准备是至关重要的一步,也是第一步。数据的准备将包含以下几个部分,数据的获取,数据的清洗与整理以及数据的标注,数据的获取,一般我们有以下的渠道,开源数据集的获取,爬虫获取,以及我们自己去进行一些采集。但是由于自己采集的效率比较低,所以我们可以优先采用前面两种渠道,然后是数据的整理,数据的整理工作,这一步尤其重要,它包含统一图片的格式,统一图片的命名标准,以及对图片进行一些去重。对我们需要的图片进行相应的裁剪。最后是图像的标注,图像的标注就是获取图像对应的label。
数据获取
我们使用开源数据集或者使用爬虫来进行扒取。开源数据集的话,我们现在这里给大家介绍一个比较常用的数据集:
链接地址:http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html

如上图,celeba这个数据集是香港中文大学汤晓鸥他们实验室整理的一个图像领域里非常有名的数据集,它包含20万左右的人脸,每一个人脸包含40多个属性。总体来说它包含不同的姿态,不同的表情,非常适合我们这样的一个任务,因为它的多样性非常好。
然后我们介绍一个比较好用的一个爬虫:
链接地址:https://github.com/sczhengyabin/Image-Downloader
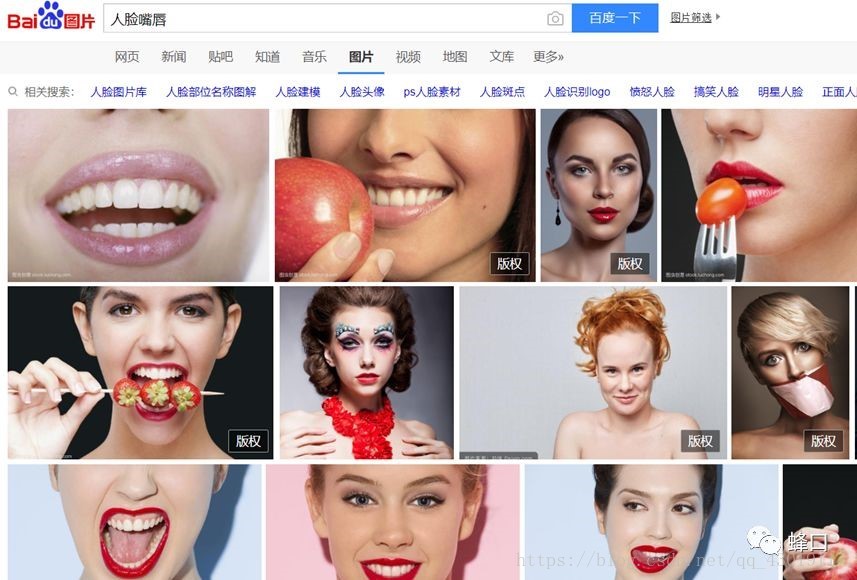
上图这个爬虫可以爬取google,bing以及百度这三大通用搜索引擎的图片,每一个搜索引擎大概可以爬到2000张左右的图片,上面是我们使用人脸嘴唇这样一个关键词,获取到一些结果。
数据整理
在我们准备好了数据之后,我们接下来要对这些数据进行一些有效的整理,它包含要统一图片的格式,重命名以及图片的去重等一系列的操作,如下图:
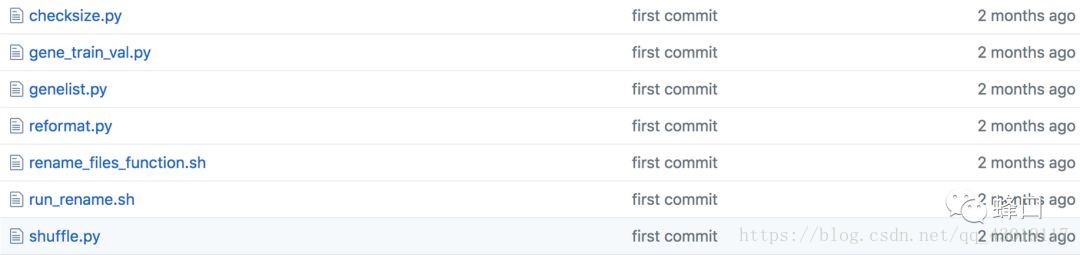
在这里我不再对上面的这几个步骤逐一的说明,我给大家提供一个github链接,这是我开源的一个github项目。
链接地址:https://github.com/longpeng2008/LongPeng_ML_Course
它上面已经包含了统一格式重命名以及去重的一些脚本,大家可以自行的去follow去使用。
图像裁剪
最后一步,我们要对图像进行适当的裁剪。本项目的这个任务是一个对嘴唇进行分割任务,在图像项目中我们一般会简化问题,我们没有必要使用整张的人脸,没有必要使用带有非人脸的区域来进行训练。所以我们需要首先对这个嘴唇区域进行裁剪,裁剪完嘴唇区域之后,我们针对嘴唇区域去训练一个分割的模型。在使用过程中,我们可以利用其它的方法,先检测到嘴唇这个区域,然后对这个区域进行分割,这样可以提高模型的鲁棒性,提高模型抗干扰的能力。

具体的方法我们可以先使用opencv的一个人脸关键点检测的开源框架。首先我们可以提取到嘴唇的关键点,提取到嘴唇的关键点之后,我们可以适当的扩大一下嘴唇的二维区域,这也方便我们后面做一些数据增强的操作。下面就是我们裁剪出来的嘴唇的结果:

我是对嘴唇的区域裁剪了一个正方形.
数据标注
得到了我们训练数据之后,我们需要对它进行数据的标注。数据的标注,可以使用一些开源工具。labelme是一个非常常用的开源工具,它可以对图像分割任务、检测任务等一系列任务进行标注。我们现在是一个图像分割的任务,如下图:

所以我们需要的是标注出图像主体的轮廓,也就是嘴唇的轮廓。如上最终标注的结果就是一张与原图大小相同的图片,如下图:

左图是我们的原图,右图是我们的标注结果。从我们的标注结果可以看出,上嘴唇和下嘴唇我们进行了区分。图像分割任务本质上是一个逐像素的图像分类任务,在caffe这个开源框架之中,图像分类任务的标签是从0,1,2依次往上叠加。所以我们这个彩色图肯定是不能直接用的。我们最终要使用的话,必须将这个彩色图转化为0,1,2,3这样的标签,由于我们的这个图像任务包含背景上嘴唇下嘴唇,所以我们的标签会包含0,1,2。至于这个转化脚本的话,大家可以自己去尝试编写。
完整内容及视频解读,请关注蜂口小程序~
参与内测,免费获取蜂口所有内容,请扫描右下方二维码申请内测资格,更有其他优惠福利多多,欢迎大家多多参与,尽情挑刺,凡是好的建议,我们都会虚心采纳哒~
蜂口小程序将持续为你带来最新技术的落地方法,欢迎随时关注了解~
数据准备的完整过程:一站式caffe工程实践连载(2)
猜你喜欢
转载自blog.csdn.net/qq_43019117/article/details/82465641
今日推荐
周排行