首先简介一下IRIS数据集,150*5的一个数据集(4属性+1结果),很小很经典,数据内容主要是对一种花的分类,分为三类。具体内容见IRIS数据集下载
拿到数据集,先得了解了解数据,既然要建模分析数据不了解数据怎么行,数据集四中个属性花萼长度,花萼宽度,花瓣长度,花瓣宽度等(没学过生物,却是不懂物理规律),只需要关注数据分布,数据规律即可,数据具体的物理含义并不是最重要的(很多的数据分析为了安全性,都会进行初步处理,分析时拿到的数据是二手数据,没有物理含义)。
首先需要以下包,(没安装的可以安装Anaconda,很给力很方便的库)
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf读取数据,并做初步处理,设置表头,属性分别命名为,abcd,class作为类别也就是结果,
这里为什么修改class为0,0.5,1?
这是有原因的,,sigmoid函数应该很熟吧,将实数区间映射到0-1之间,现在知道为什么取这三个数了吧,,还不知道?GG 取别的试试呗。
取别的试试呗。
iris = pd.read_csv("../data/Iris.txt",names=['a','b','c','d','class'])
iris['class'][iris['class']=="Iris-setosa"] = 0
iris['class'][iris['class']=="Iris-versicolor"] = 0.5
iris['class'][iris['class']=="Iris-virginica"] = 1将数据按照类别分开,便于分析:
iris_class1 = iris[iris["class"]==0]
iris_class2 = iris[iris["class"]==0.5]
iris_class3 = iris[iris["class"]==1]先看看参数两两之间的关系:
import itertools
plt.figure(figsize=(15,10))
t = 1
for i,j in list(itertools.combinations('abcd',2)):
plt.subplot(2,3,t)
plt.scatter(iris_class1[i],iris_class1[j],7,c='r')
plt.scatter(iris_class2[i],iris_class2[j],7,c='g')
plt.scatter(iris_class3[i],iris_class3[j],7,c='b')
t+=1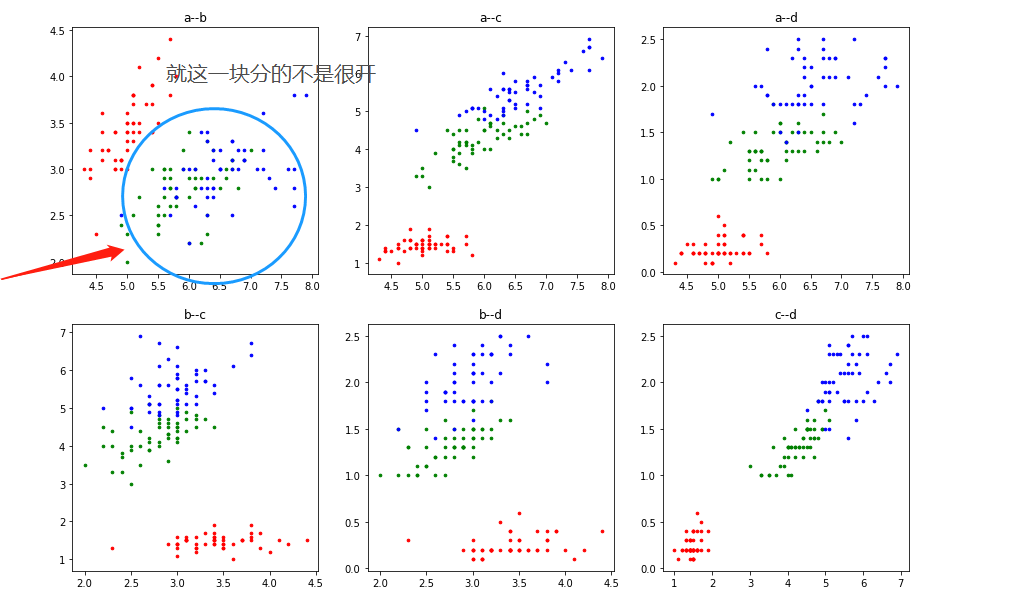

from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(7,5))
ax = Axes3D(fig)
ax.scatter(iris_class1['a'],iris_class1['b'],iris_class1['c'],c='r')
ax.scatter(iris_class2['a'],iris_class2['b'],iris_class2['c'],c='g')
ax.scatter(iris_class3['a'],iris_class3['b'],iris_class3['c'],c='b')
fig = plt.figure(figsize=(7,5))
ax = Axes3D(fig)
ax.scatter(iris_class1['a'],iris_class1['b'],iris_class1['d'],c='r')
ax.scatter(iris_class2['a'],iris_class2['b'],iris_class2['d'],c='g')
ax.scatter(iris_class3['a'],iris_class3['b'],iris_class3['d'],c='b')
fig = plt.figure(figsize=(7,5))
ax = Axes3D(fig)
ax.scatter(iris_class1['c'],iris_class1['b'],iris_class1['d'],c='r')
ax.scatter(iris_class2['c'],iris_class2['b'],iris_class2['d'],c='g')
ax.scatter(iris_class3['c'],iris_class3['b'],iris_class3['d'],c='b')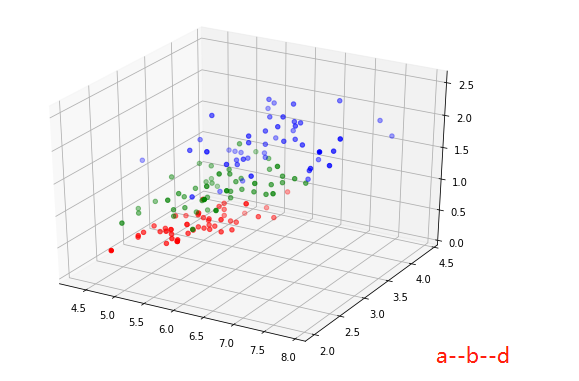
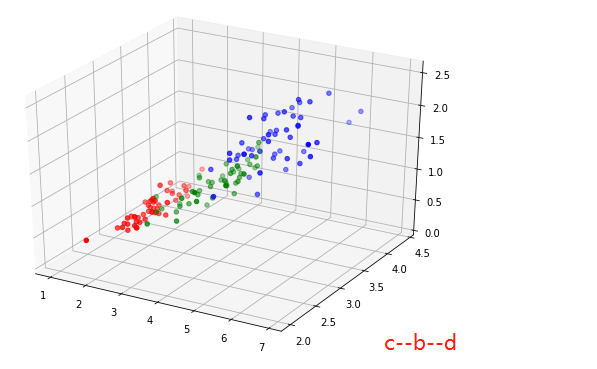
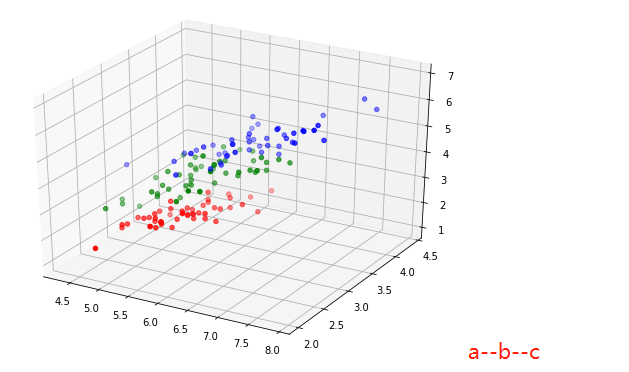
表面上看起来还是比较容易分的(所以来个简单的模型试试)先把数据分成两部分,(属性多余3个时就不能可视化的展示结果,只能通过测试集进行测试,判断模型是否可靠,神经网络模型还是个黑盒子,但训练好的情况下处理高维(复杂)问题表现的还是十分不错的)
此处以2:1的方式分割测试集和训练集,
temp = np.array(iris)
train_data = np.delete(temp,range(len(temp))[::3],axis=0)
test_data = temp[::3,:]搭建模型需要准备的函数,神经网络层还是很简单的,,就是权值*输入+b最多再加个激励函数,输出即可
"""
添加神经网络层的函数
inputs -- 输入内容
in_size -- 输入尺寸
out_size -- 输出尺寸
activation_function --- 激励函数,可以不用输入
"""
def add_layer(inputs,in_size,out_size,activation_function=None):
W = tf.Variable(tf.zeros([in_size,out_size])+0.01) #定义,in_size行,out_size列的矩阵,随机矩阵,全为0效果不佳
b = tf.Variable(tf.zeros([1,out_size])+0.01) #不建议为0
Wx_plus_b = tf.matmul(inputs,W) + b # WX + b
if activation_function is None: #如果有激励函数就激励,否则直接输出
output = Wx_plus_b
else:
output = activation_function(Wx_plus_b)
return output利用上面函数搭建模型如下:
X = tf.placeholder(tf.float32,[None,4])
Y = tf.placeholder(tf.float32,[None,1])
output1 = add_layer(X,4,8,activation_function = tf.nn.sigmoid)
output2 = add_layer(output1,8,3,activation_function = tf.nn.sigmoid)
temp_y = add_layer(output2,3,1,activation_function = tf.nn.sigmoid)
loss = tf.reduce_mean(tf.reduce_sum(tf.square(Y-temp_y),
reduction_indices=[1]))#先求平方,再求和,在求平均
train_step = tf.train.AdamOptimizer(0.005).minimize(loss)#通过优化器,以0.1的学习率,减小误差loss前两行代码是定义输入通道的类型,最后两行代码意思是定义损失函数,和学习方法(或者叫训练方法,优化器主要目的就是调参数,保证loss最小)。中间三行代码是建立模型的主要代码,此处模型为input:4-》(input:4,output:8)-》(input:8,output:3)-》(input:3,output:1),放在图里如下:
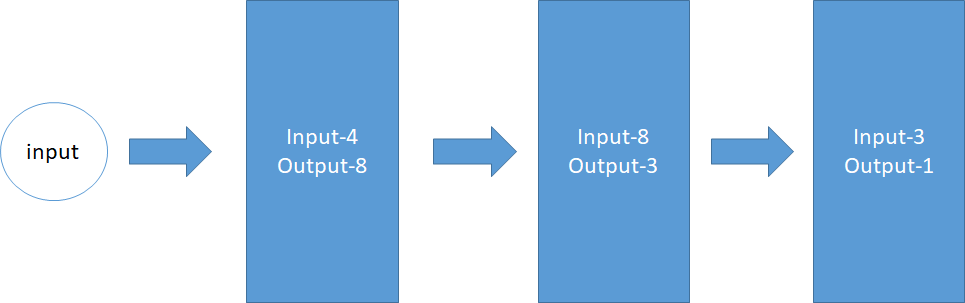
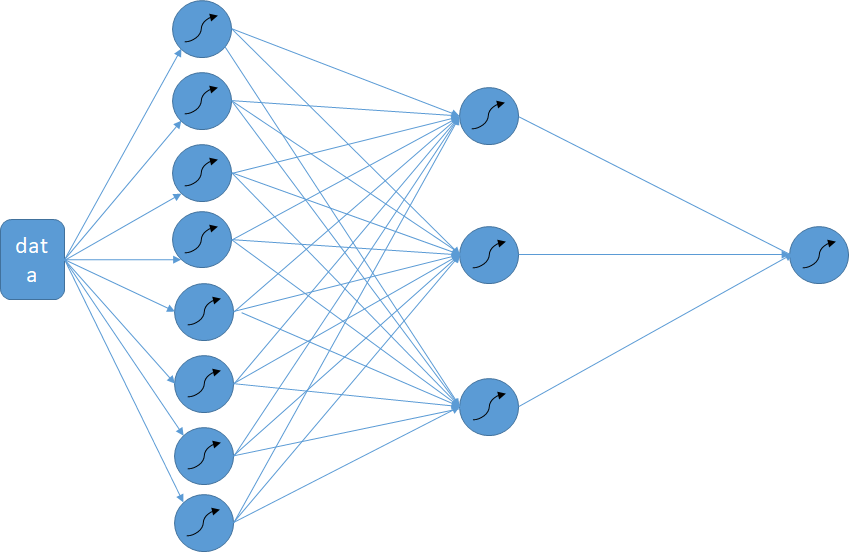
搭建好模型,开始训练,
# train_x = iris[['a','b','c']]
# train_y = iris[['class']]
#拆分训练集数据集,分为输入和输出
train_x = train_data[:,:4]
train_y = train_data[:,-1:]
sess = tf.Session()
sess.run(tf.global_variables_initializer())
save_process = []
for i in range(90000):#训练90000次
sess.run(train_step,feed_dict={X:train_x,Y:train_y})
if i%300 == 0:#每300次记录损失值(偏差值)
save_process.append(sess.run(loss,feed_dict={X:train_x,Y:train_y}))sace_process中记录这loss的变化情况,可视化如下:
#第前两个数据比较大,踢掉
save_process = np.delete(save_process,[0,1])
plt.plot(range(len(save_process)),save_process)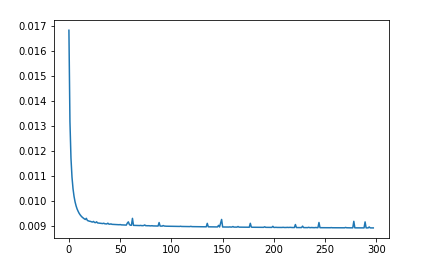
看到loss的变化情况,拟合的还算是很不错的,下面用之前分出来的测试机进行测试,看看模型泛化能力和准度额度。
def compare_numpy(a,b,is_num=False):
"""比较两个维度相同的数组,返回相同数字个数/相似度"""
num = 0
for i in range(len(a)):
if a[i]==b[i]:
num+=1
return num if is_num else num/len(a)
test_x = test_data[:,:4]
test_y = test_data[:,-1:]
result = sess.run(temp_y,feed_dict={X:test_x})
result[result > 0.8] = 1
result[result < 0.2] = 0
result[(result < 0.8) & ( result > 0.2)] = 0.5
print("总数:",len(test_data)," 准确个数:",compare_numpy(result,test_y,True)," 精确度:",compare_numpy(result,test_y))总数: 50 准确个数: 49 精确度: 0.98
输出结果很理想,,不错,至此模型搭建训练测试完毕,
客官:“你这模型能用么?”
 :“当然不能,,一个简单的案例而已over”
:“当然不能,,一个简单的案例而已over”
完整参考代码(好用的话客官给个小星星 )
)