第18章 检测点模型
在第13章我们讨论了在训练结束后如何保存和序列化模型到磁盘上。在上一章,我们学习了在过拟合和欠拟合发生的时候如何画出它们,使您能够在训练时,在保持显示出希望的模型的同时,杀死性能不佳的实验。
但是,你可能想我们是否能够将上述策略结合到一起。在损失/正确率提高时能序列化模型吗?或者在训练过程中仅序列化最佳模型是可能的吗?答案是肯定的,幸运的是,这些操作不需要我们写回调函数,这些都内置在keras库中了。
1 检查神经网络模型的改进
检查点的一个好的应用是每次在训练中有好的改进时,就序列化到磁盘上。我们定义“改进”要么是损失下降要么是正确率提高,我们将在实际的keras回调函数中设置这些参数。
具体代码见GitHub的chapter18/。
在导入类中注意ModelCheckpoint,这个类让我们在模型性能提高的时候检查和序列化网络到磁盘上。构建回调函数如下:
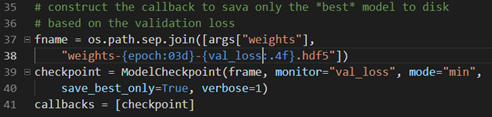
我们在第37-38行定义了保存的检查点文件名,固定值weights-epoch数目-损失值。然后39-40定义检查点模型,参数保存的名字、要监视的变量(这里我们监视验证损失)、mode指明如何监视(由于损失越小越好,因此设为min;如果监视的是正确率,由于越大越好,则要设置为max)、save_best_only参数则表示最新的最佳模型不会被覆盖、最后的verbose参数仅是显示执行过程中的log信息。
然后在训练模型时,加入callback就可以了:
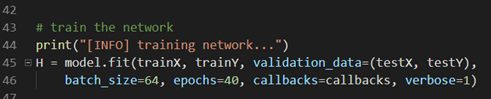
之后运行模型,等待完成,就可以看到每次验证损失降低时就记录一次模型文件了。
2 仅检查最佳神经网络
可能在上面运行中最不好的是每次模型改进就会保存一个模型,最后会有很多改进模型,但是我们可能只想保留最佳模型文件。幸好,可以通过ModelCheckpoint接受一个参数,然后无论什么时候性能改进了,仅仅是覆盖这个文件。我们创建一个cifar10_checkpoint_best.py文件,具体见GitHub的chapter18/下。
这里仅仅是通过添加一个覆盖文件即可:
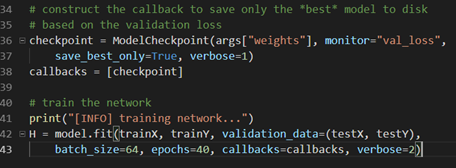
其它代码则与训练一个网络的步骤相同,导入模块,加载数据、划分数据、数据float化、向量化标签、初始化模型与优化器。
这里执行完后,可看到只有一个文件保留,即只保留一个最佳的模型文件。
作者倾向于后者,这可以保留较少文件,且保留了最佳模型文件。