一、前言
本文是《Python开发实战案例之网络爬虫》的第三部分:7000本电子书下载网络爬虫开发实战详解。配套视频课程详见51CTO学院请添加链接描述。
二、章节目录
3.1 业务流程
3.2 页面结构分析:目录页
3.3 页面结构分析:详情页
3.4 页面请求和响应:目录页
4.5 页面请求和响应:详情页
3.4
三、正文
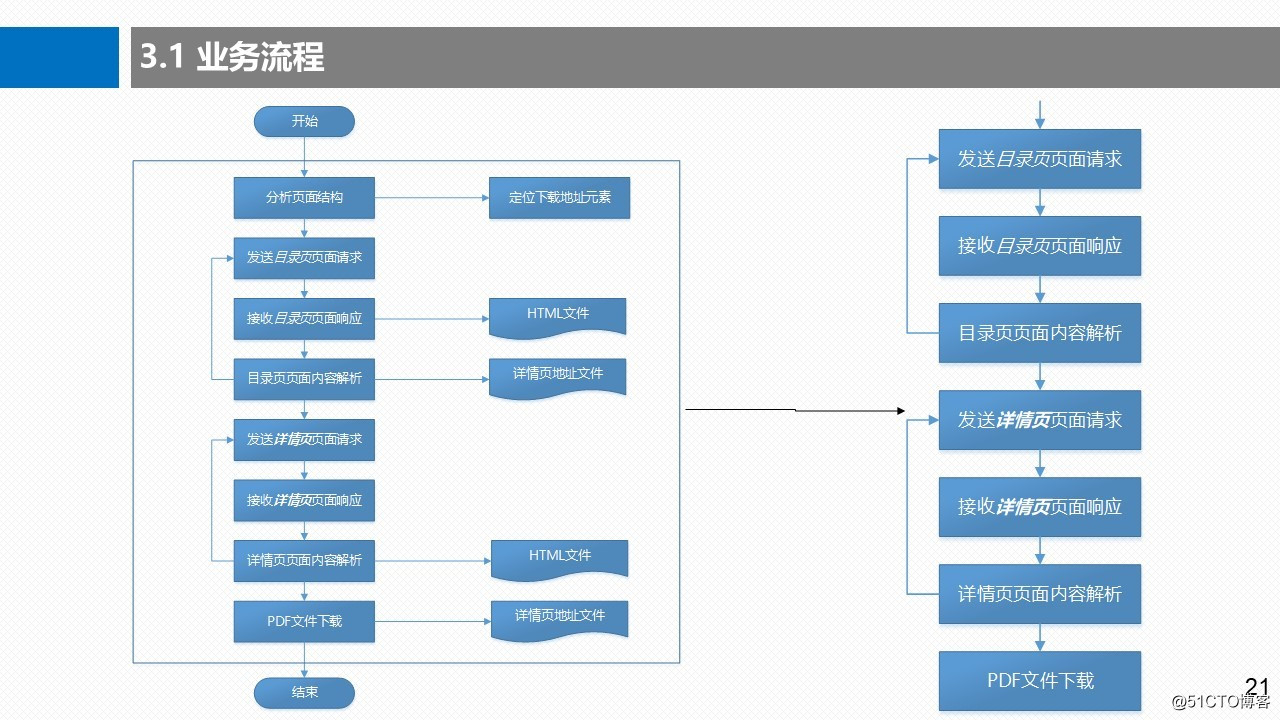
3.1 业务流程
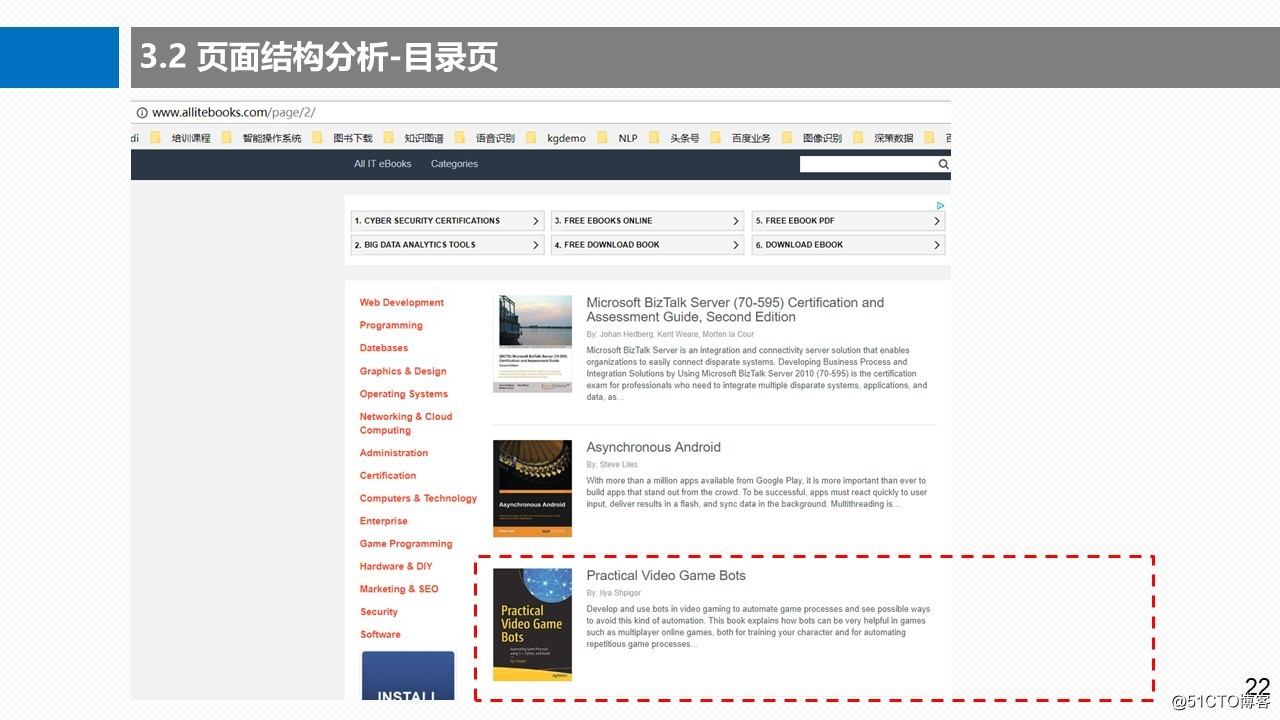
3.2.1 页面结构分析-目录页
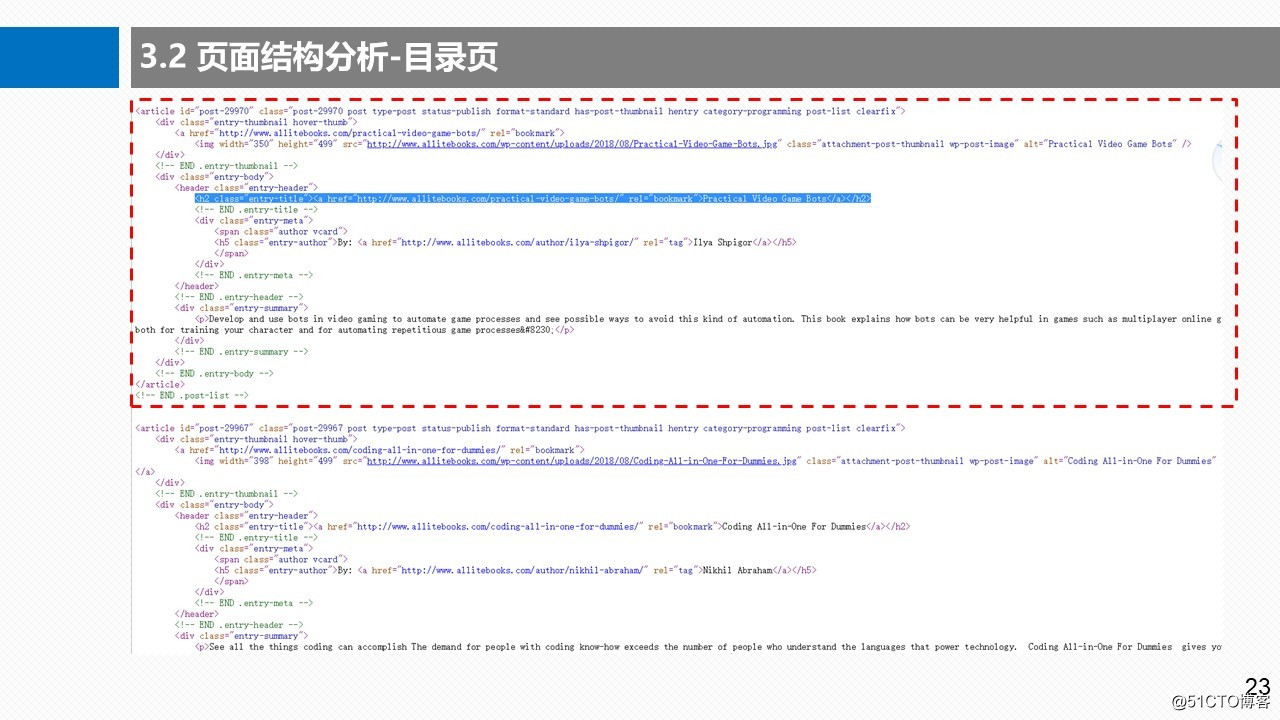
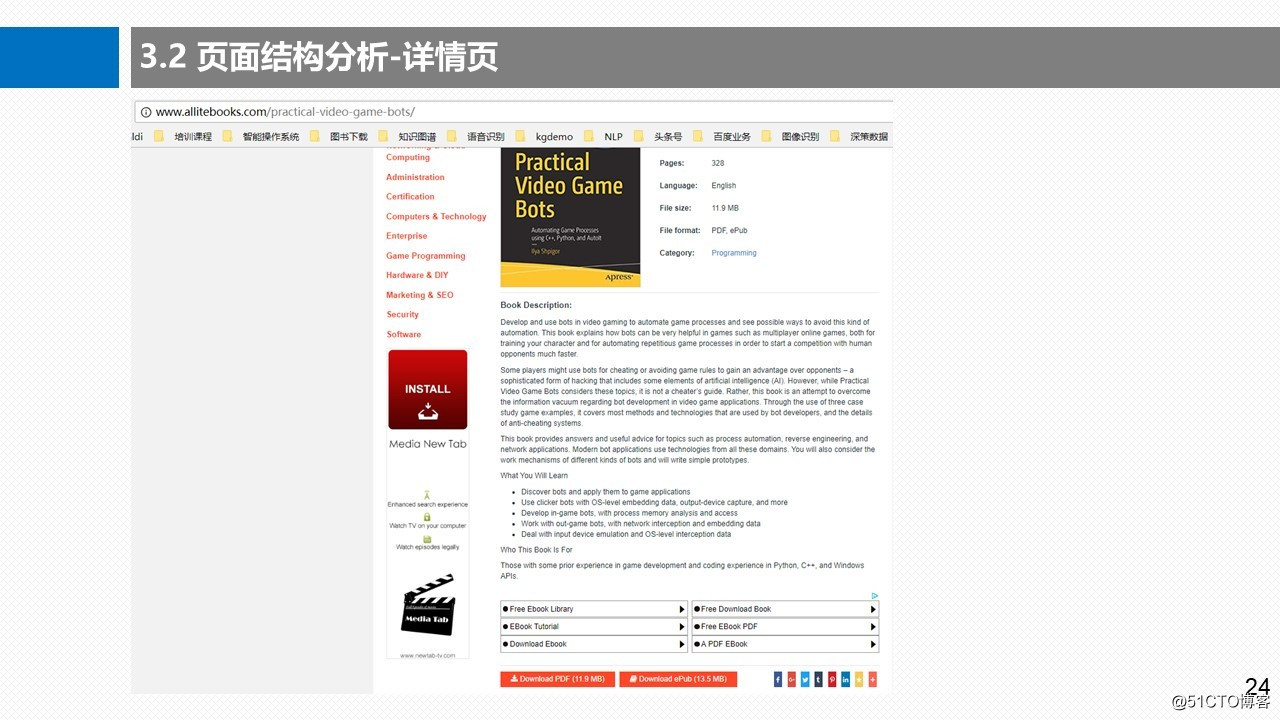
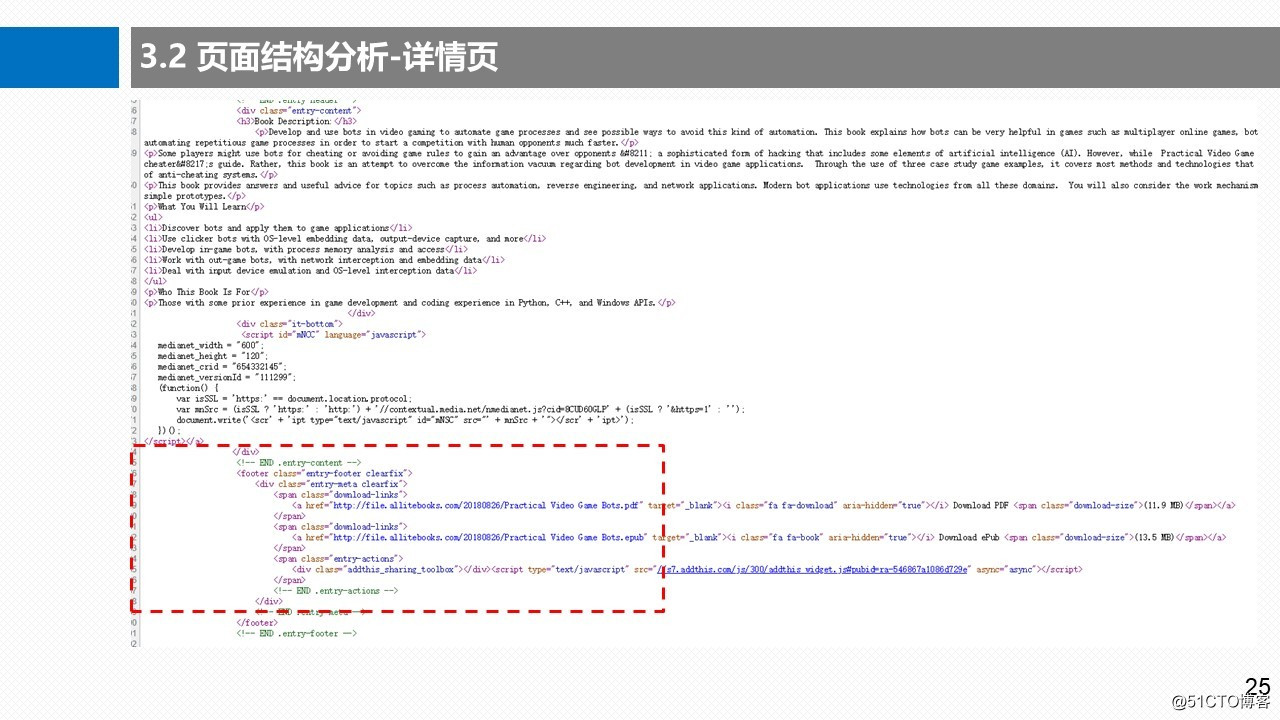
3.2.2 页面结构分析-详情页
3.3 页面请求与解析-目录页

3.4 页面请求与解析-详情页

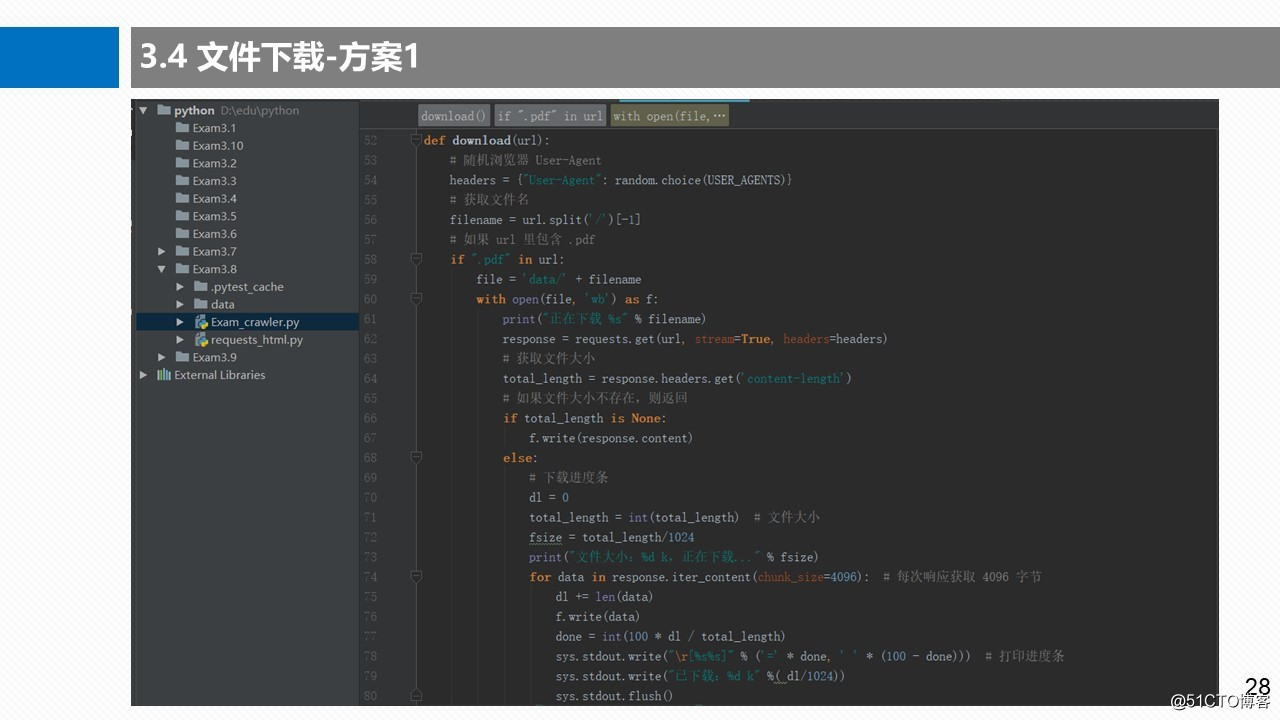
3.5 文件下载

四、未完待续
下期预告:《Python网络爬虫源码框架剖析》
上一篇:
《Python网络爬虫实战案例之:7000本电子书下载(1)》
《Python网络爬虫实战案例之:7000本电子书下载(2)》
《Python网络爬虫实战案例之:7000本电子书下载(3)》
《Python网络爬虫实战案例之:7000本电子书下载(4)》