我们之前一直都在爬取网页数据,但有些企业并没有提供web网页服务,而是提供了app服务,还有些web网页数据的各种反爬虫措施太牛逼,这时候如果从app端爬取兴许更容易得多,本篇就来介绍app数据如何爬取
作为案例,选用简单的 王者荣耀盒子 的英雄胜率排行榜
方法:
1. 利用抓包工具(例如 Fiddler)得到包含所需数据的 url 以及数据的格式
2. 用代码模拟数据请求
操作步骤:
一、环境搭建
参看教程:https://blog.csdn.net/gld824125233/article/details/52588275
搭建完后设置Fiddler 的 url 过滤,这样就可以只看手机上的数据包,界面清爽不少
过滤操作:Tools-->Options-->HTTPS-->Decrypt-->from remote clients only

二、得到url和数据
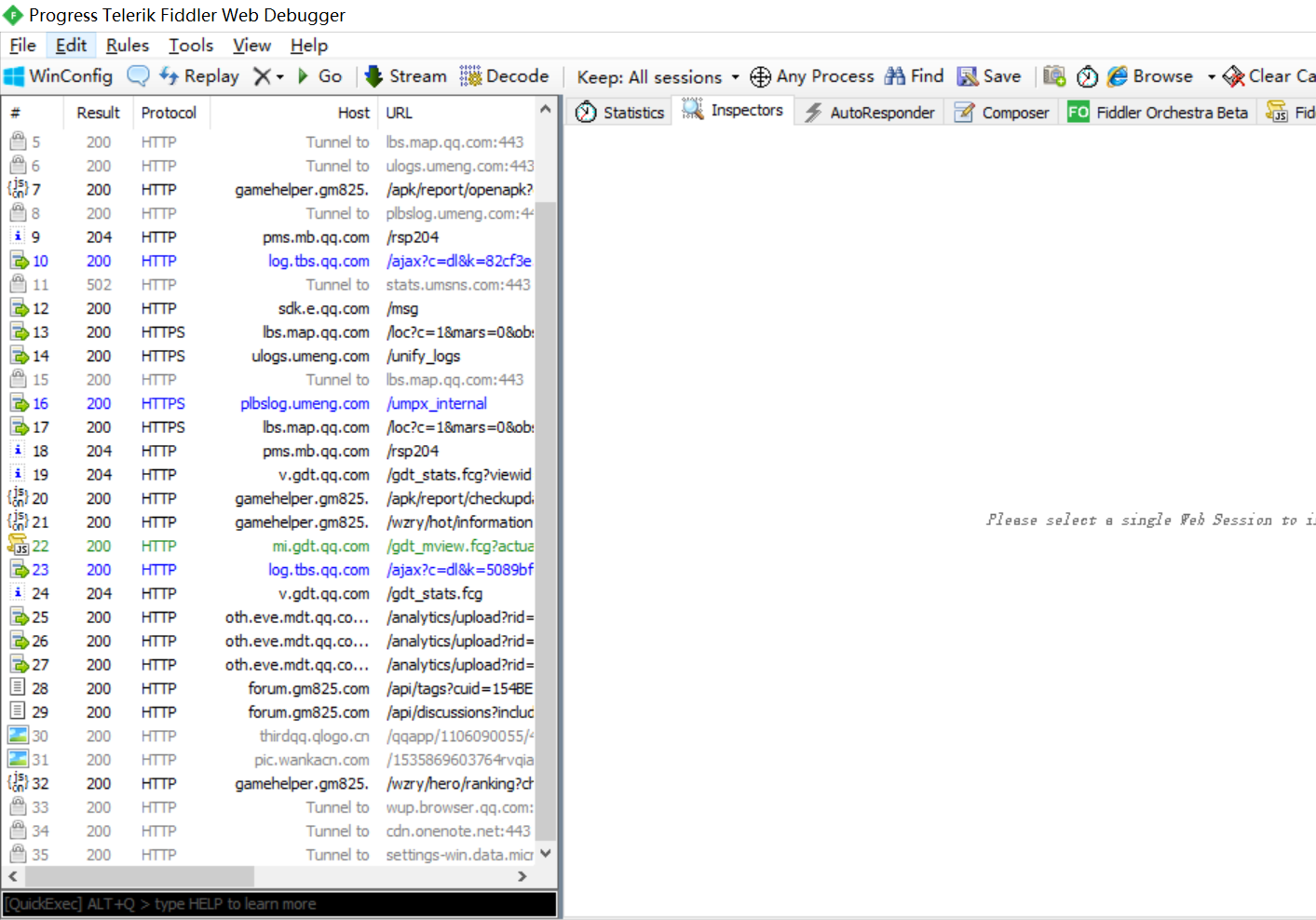
1. 打开Fiddle界面,观察左侧栏请求的变化
同时手机打开 王者荣耀盒子,点击屏幕右下角的 辅助 --> 英雄排行,观察Fiddle界面左侧栏请求的变化
2. 找到包含所需数据的请求,一般都是后几个,慢慢试,这里找到的请求如下:
点击该请求,上部分是请求部分,点击 Raw 查看一个标准请求头格式,其中就有 url
下部分是响应部分,一般app的传输数据都是json格式,点击 JSON ,查看数据,发现所需要的数据都包含在一个叫ranking_list 的列表里面

三、编写代码获取数据
既然已经得到了该请求的url和请求方法等信息,那接下来的代码就是小事一桩了
1. 根据分析数据的结构,获取 ranking_list
# 导入请求库 import requests # 所需数据的url url = 'http://gamehelper.gm825.com/wzry/hero/ranking?channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=13.0.4.0&version_code=13040&cuid=154BE40FAD86F1906AF64ECFB77B7781&ovr=5.1.1&device=Xiaomi_2014813&net_type=1&client_id=lbEmaFJKlM50o%2BaES6taUw%3D%3D&info_ms=&info_ma=FeiTA88o1ij4mk0KlrbC8spJRoB%2F35t38Dfg9cUZPqk%3D&mno=0&info_la=TZo6%2BEi6%2FED1iWhh5Ix7tQ%3D%3D&info_ci=TZo6%2BEi6%2FED1iWhh5Ix7tQ%3D%3D&mcc=0&clientversion=13.0.4.0&bssid=n67IYIRXbcwQBbrl5CiG5bmhG%2FSMFdSypVKXjBNrULU%3D&os_level=22&os_id=8bd64b36c5b20ff5&resolution=720_1280&dpi=320&client_ip=192.168.1.102&pdunid=3d1a68a37d22' # 返回的数据是dict格式,用json获取 data= requests.get(url).json() # 找到包含排名的列表,列表的每个元素都是dict类型 ranking_list = data['ranking_list']2. 原始数据里用 ‘1~6’ 来表示该英雄的对应类型,可读性很差所以编写转化的代码
# 类型的格式化 def type_format(hero_type): if hero_type[0] == '1': return '战士' if hero_type[0] == '2': return '法师' if hero_type[0] == '3': return '坦克' if hero_type[0] == '4': return '刺客' if hero_type[0] == '5': return '射手' if hero_type[0] == '6': return '辅助'3. 再格式化一下胜率和出场率
def rate(rate): return '{0}{1}'.format(rate, '%')4. 然后遍历每个排名,提取格式化后的信息
for i in ranking_list: # 设置胜率排名 hero_rank = str(ranking_list.index(i)+1) # 获取英雄的id hero_id = i['hero_id'] # 获取英雄的名字 hero_name = i['name'] # 获取英雄的头像 hero_icon = i['icon'] # 获取英雄的类型 hero_type = i['type'] # 格式化类型 hero_type = type_format(hero_type) # 获取英雄的胜率 hero_winrate = i['winrate'] # 格式化胜率 hero_winrate = rate(hero_winrate) # 获取英雄的出场率 hero_appearance_rate = i['appearance_rate'] # 格式化出场率 hero_appearance_rate = rate(hero_appearance_rate)5. 最后写入文件
# 以追加的方式写入文件 with open('rank_list.txt', 'a', encoding='utf-8') as f: f.write('排名:'+hero_rank+' 英雄:'+hero_name+' ID:'+hero_id+' 头像:'+hero_icon+' 类型:'+hero_type+' 胜率:'+hero_winrate+' 出场率:'+hero_appearance_rate+'\n')
结果展示

全部代码:
# 导入请求库 import requests # 类型的格式化 def type_format(hero_type): if hero_type[0] == '1': return '战士' if hero_type[0] == '2': return '法师' if hero_type[0] == '3': return '坦克' if hero_type[0] == '4': return '刺客' if hero_type[0] == '5': return '射手' if hero_type[0] == '6': return '辅助' def rate(rate): return '{0}{1}'.format(rate, '%') # 所需数据的url url = 'http://gamehelper.gm825.com/wzry/hero/ranking?channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=13.0.4.0&version_code=13040&cuid=154BE40FAD86F1906AF64ECFB77B7781&ovr=5.1.1&device=Xiaomi_2014813&net_type=1&client_id=lbEmaFJKlM50o%2BaES6taUw%3D%3D&info_ms=&info_ma=FeiTA88o1ij4mk0KlrbC8spJRoB%2F35t38Dfg9cUZPqk%3D&mno=0&info_la=TZo6%2BEi6%2FED1iWhh5Ix7tQ%3D%3D&info_ci=TZo6%2BEi6%2FED1iWhh5Ix7tQ%3D%3D&mcc=0&clientversion=13.0.4.0&bssid=n67IYIRXbcwQBbrl5CiG5bmhG%2FSMFdSypVKXjBNrULU%3D&os_level=22&os_id=8bd64b36c5b20ff5&resolution=720_1280&dpi=320&client_ip=192.168.1.102&pdunid=3d1a68a37d22' # 返回的数据是dict格式,用json获取 data= requests.get(url).json() # 找到包含排名的列表,列表的每个元素都是dict类型 ranking_list = data['ranking_list'] # 遍历每个英雄排名 for i in ranking_list: # 设置胜率排名 hero_rank = str(ranking_list.index(i)+1) # 获取英雄的id hero_id = i['hero_id'] # 获取英雄的名字 hero_name = i['name'] # 获取英雄的头像 hero_icon = i['icon'] # 获取英雄的类型 hero_type = i['type'] # 格式化类型 hero_type = type_format(hero_type) # 获取英雄的胜率 hero_winrate = i['winrate'] # 格式化胜率 hero_winrate = rate(hero_winrate) # 获取英雄的出场率 hero_appearance_rate = i['appearance_rate'] # 格式化出场率 hero_appearance_rate = rate(hero_appearance_rate) # 以追加的方式写入文件 with open('rank_list.txt', 'a', encoding='utf-8') as f: f.write('排名:'+hero_rank+' 英雄:'+hero_name+' ID:'+hero_id+' 头像:'+hero_icon+' 类型:'+hero_type+' 胜率:'+hero_winrate+' 出场率:'+hero_appearance_rate+'\n')
github:https://github.com/JeesonZhang/pythonspider/blob/master/app_crawl