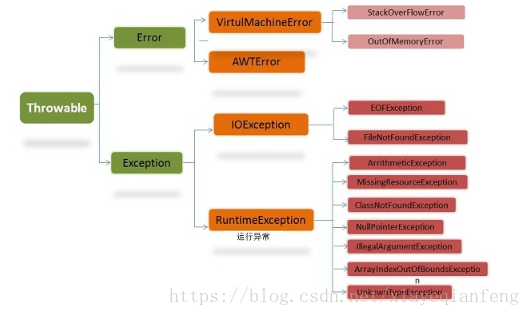
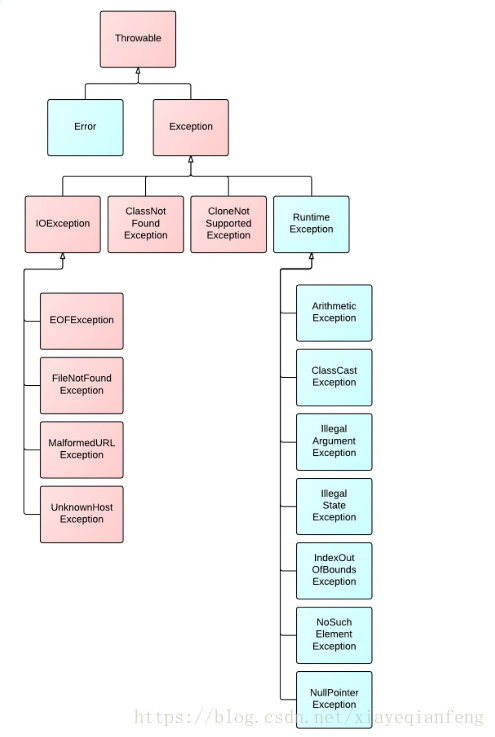
1.JAVA异常类体系
Error类体系描述了java运行体系中的内部错误以及资源耗尽的情形,Error不需要捕捉;
异常分为运行时异常,非运行时异常和error,其中error是系统异常,只能重启系统解决。非运行时异常需要我们自己补获,而运行异常是程序运行时由虚拟机帮助我们补获,运行时异常包括数组的溢出,内存的溢出空指针,分母为0等!
2.线程安全
Thread.sleep() 和 Object.wait(),都可以抛出 InterruptedException。这个异常是不能忽略的,因为它是一个检查异常(checked exception)
如果你的代码所在的进程中又多个线程再同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期是一样的,就是线程安全的。
线程安全问题都是由全局变量及静态变量引起的。

3.Servlet加载
ServletContext对象:servlet容器在启动时会加载web应用,并为每个web应用创建唯一的servletcontext对象,可以把ServletContext看成是一个Web应用的服务器端组件的共享内存,在ServletContext中可以存放共享数据。ServletContext对象是真正的一个全局对象,凡是web容器中的Servlet都可以访问。
整个web应用只有唯一的一个ServletContext对象
servletConfig对象:用于封装servlet的配置信息。从一个servlet被实例化后,对任何客户端在任何时候访问有效,但仅对servlet自身有效,一个servlet的ServletConfig对象不能被另一个servlet访问。
4.java表达式转型规则由低到高转换
java表达式转型规则由低到高转换:
1、所有的byte,short,char型的值将被提升为int型;
2、如果有一个操作数是long型,计算结果是long型;
3、如果有一个操作数是float型,计算结果是float型;
4、如果有一个操作数是double型,计算结果是double型;
5、被fianl修饰的变量不会自动改变类型,当2个final修饰相操作时,结果会根据左边变量的类型而转化。
6、整数类型byte(1个字节)short(2个字节)int(4个字节)long(8个字节)
7、字符类型char(2个字节)
8、浮点类型float(4个字节)double(8个字节,默认浮点型类型)
只要两个操作数中有一个是double类型的,另一个将会被转换成double类型,并且结果也是double类型,如果两个操作数中有一个是float类型的,另一个将会被转换为float类型,并且结果也是float类型,如果两个操作数中有一个是long类型的,另一个将会被转换成long类型,并且结果也是long类型,否则(操作数为:byte、short、int 、char),两个数都会被转换成int类型,并且结果也是int类型。
5.java内存
方法区和堆内存是线程共享的。程序计数器、虚拟机栈是线性隔离的。
6.java的各种开发模式
https://blog.csdn.net/qq_40199914/article/details/79002784
7.抽象类vs接口
(1)抽象类可以定义普通成员变量而接口不可以,但是抽象类和接口都可以定义静态成员变量,只能接口的静态成员变量要用static final public来修饰。
(2)接口没有构造方法,所以不能实例化,抽象类又构造方法,但是不是用来实例化的,是用来初始化的。
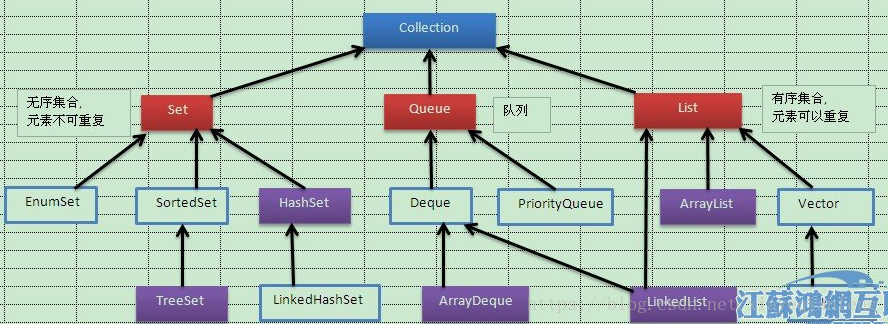
8.Collection子类
9.java基本数据类型
(1)第一类:整数类型 byte short int long
(2) 第二类:浮点型 float double
(3)第三类:逻辑型 boolean
(4)字符型 : char
10.java正则表达式
| 元字符 | 描述 |
| \ | 将下一个字符标记符、或一个向后引用、或一个八进制转义符。例如,“\\n”匹配\n。“\n”匹配换行符。序列“\\”匹配“\”而“\(”则匹配“(”。即相当于多种编程语言中都有的“转义字符”的概念。 |
| ^ |
匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 |
| $ |
匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 |
| * |
匹配前面的子表达式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等价于o{0,} |
| + |
匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
| ? |
匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。 |
| {n} |
n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
| {n,} |
n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} |
m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
| ? |
当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+”将尽可能多的匹配“o”,得到结果[“oooo”],而“o+?”将尽可能少的匹配“o”,得到结果 ['o', 'o', 'o', 'o'] |
| .点 |
匹配除“\r\n”之外的任何单个字符。要匹配包括“\r\n”在内的任何字符,请使用像“[\s\S]”的模式。 |
| (pattern) |
匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“\(”或“\)”。 |
| (?:pattern) |
非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分时很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。 |
| (?=pattern) | 非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。 |
| (?<=pattern) | 非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。 |
| (?<!pattern) | 非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。这个地方不正确,有问题 此处用或任意一项都不能超过2位,如“(?<!95|98|NT|20)Windows正确,“(?<!95|980|NT|20)Windows 报错,若是单独使用则无限制,如(?<!2000)Windows 正确匹配 |
| x|y |
匹配x或y。例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[zf]ood”则匹配“zood”或“food”。 |
| [xyz] |
字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 |
| [^xyz] |
负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”。 |
| a-z] |
字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身. |
| [^a-z] |
负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
| \b |
匹配一个单词边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。 |
| \B |
匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
| \cx |
匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。 |
| \d |
匹配一个数字字符。等价于[0-9]。grep 要加上-P,perl正则支持 |
| \D |
匹配一个非数字字符。等价于[^0-9]。grep要加上-P,perl正则支持 |
| \f |
匹配一个换页符。等价于\x0c和\cL。 |
| \n |
匹配一个换行符。等价于\x0a和\cJ。 |
| \r |
匹配一个回车符。等价于\x0d和\cM。 |
| \s |
匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
| \S |
匹配任何可见字符。等价于[^ \f\n\r\t\v]。 |
| \t |
匹配一个制表符。等价于\x09和\cI。 |
| \v |
匹配一个垂直制表符。等价于\x0b和\cK。 |
| \w |
匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集 |
| \W |
匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
11.内部类
https://www.jianshu.com/p/f0fdea957792
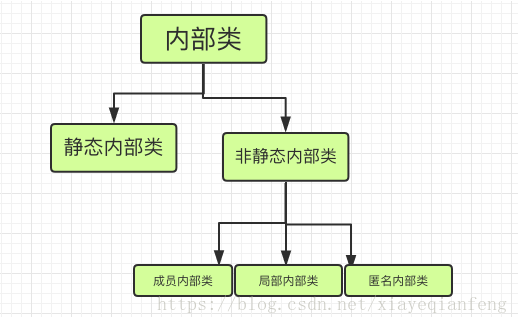
(1)静态内部类除了访问权限修饰符比外围类多以外, 和外围类没有区别, 只是代码上将静态内部类组织在了外部类里面。静态内部类不能访问外部类的非公开成员。
(2)成员内部类可以直接使用外部类的所有成员和方法,即使是private修饰的。而外部类要访问内部类的所有成员变量和方法,内需要通过内部类的对象来获取。(谁叫它是亲儿子呢?) 要注意的是,成员内部类不能含有static的变量和方法。因为成员内部类需要先创建了外部类,才能创建它自己的。成员内部类不能有static修饰的成员,但是却允许定义常量
(3)局部内部类的局部变量需要用final修饰;局部变量必须有初始值。
(4)为了免去给内部类命名,或者只想使用一次,就可以选择匿名内部类。
12.构造方法vs普通方法
(1)普通的类方法是可以和类名同名的,和构造方法唯一的区分就是,构造方法没有返回值
(2)构造函数不能被继承,只能被调用
13 java虚拟机功能
(1)通过ClassLoader寻找和装载class文件
(2)解释字节码成为指令并执行,提供class文件的运行环境
(3)进行运行期间垃圾回收
(4)提供与硬件交互的平台
14 default和protected的区别
default拒绝一切包外访问;protected接受包外的子类访问
15 关键字
(1)final用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承。
(2)finally是异常处理语句结构的一部分,表示总是执行。
(3)finalize这个方法一个对象只能执行一次,只能在第一次进入被回收的队列,而且对象所属于的类重写了finalize方法才会被执行。第二次进入回收队列的时候,不会再执行其finalize方法,而是直接被二次标记,在下一次GC的时候被GC。
(4) abstract不能与final同时修饰一个类
16 变量初始化
(1)静态变量会默认赋初始值,局部变量和final声明的变量必须手动赋初始值。
17 ClassLoader
JDK中提供了三个ClassLoader,根据层级从高到低为:
1.BootStrap ClassLoader,主要加载JVM自身工作需要的类。
2.Extension ClassLoader,主要加载%JAVA_HOME%\lib\ext目录下的库类。
3. Application ClassLoader ,主要加载ClassPath指定的库类,一般情况下这是程序中的默认类加载器,也是ClassLoader.getSystemClassLoader()的返回值。
JVM加载类的实现方式,我们称为双亲委托模式:如果一个类加载收到了类加载的请求,他首先不会自己去尝试加载这个类,而是把这个请求委托给自己的父加载器,每一层的类加载器都是如此,因此所有的类加载请求最终都应该传送到顶层的Bootstrap ClassLoader中,只有当父加载器反馈自己无法完成加载请求时,子加载器才会尝试自己加载。双亲委托模型的重要用途是为了解决类载入过程中的安全性问题
18.java中的四舍五入
floor : 意为地板,指向下取整,返回不大于它的最大整数 ceil : 意为天花板,指向上取整,返回不小于它的最小整数 round : 意为大约,表示“四舍五入”,而四舍五入是往大数方向入。Math.round(11.5)的结果为12,Math.round(-11.5)的结果为-11而不是-12。
19.java锁
(1)自旋锁,自旋,jvm默认是10次,有jvm自己控制。for去争取锁
(2)阻塞锁,被阻塞的线程,不会争夺锁。
(3)可重入锁,多次进入改锁的域
(4)读写锁
(5)互斥锁 锁本身就是互斥的
(6)悲观锁 不相信,这里会是安全的,必须全部上锁
(7)乐观锁
(8)公平锁 又优先级的锁
(9)非公平锁
(10)偏向锁 无竞争不锁,有竞争挂起,转为轻量锁
(11)对象锁 锁住对象
(12)线程锁
(13)锁粗化
(14)轻量级锁 CAS实现
(15)锁膨胀 jvm实现
(16)信号量 使用阻塞锁 实现的一种策略
(17)排他锁:X锁,若事物T对数据对象A加上X锁,则只允许T读取和修改A,其他任何事物都不能再对A加任何类型的锁,直到T释放A上的锁。这就保证了其他事务在T释放A上的锁之前不能再读取和修改A。
20 strut1 vs struts2
(1)struts1要求Action类继承一个抽象基类。Struts1的一个普遍问题是使用抽象类编程而不是接口。
(2)Struts2 Action类可以实现一个Action接口,也可实现其他接口,使可选和定制的服务成为可能。Struts2提供一个ActionSupport基类去实现常用的接口。Action接口不是必须的,任何又execute标识的对象都可以用作struts2的Action对象。
(3)Struts1 Action依赖于Servlet API,因为当一个Action被调用时HttpServletRequest和HttpServletResponse被传递给execute方法。
(4)struts2 Action依赖于容器,允许Action脱离容器单独被测试。如果需要,Struts2 Action仍然可以访问初始的request和response。但是,其他的元素减少或者消除了直接访问HttpServetRequest 和 HttpServletResponse的必要性。
(5)Struts1 Action是单例模式并且必须是线程安全的,因为仅有Action的一个实例来处理所有的请求。单例策略限制了Struts1 Action能作的事,并且要在开发时特别小心。Action资源必须是线程安全的或同步的。
(6) Struts2 Action对象为每一个请求产生一个实例,因此没有线程安全问题。(实际上,servlet容器给每个请求产生许多可丢弃的对象,并且不会导致性能和垃圾回收问题)
21加载驱动的方法
(1)Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver);
(2) DriverManager.registerDriver(new com.mysql.jdbc.Driver());
(3) System.setPropetry("jdbc.drivers","com.mysql.jdbc.Driver");
22 queue类比较
(1)LinkedBlockingQueue:基于链接节点的可选限定的blocking queue 。 这个队列排列元素FIFO(先进先出)。 队列的头部是队列中最长的元素。 队列的尾部是队列中最短时间的元素。 新元素插入队列的尾部,队列检索操作获取队列头部的元素。 链接队列通常具有比基于阵列的队列更高的吞吐量,但在大多数并发应用程序中的可预测性能较低。
blocking queue说明:不接受null元素;可能是容量有限的;实现被设计为主要用于生产者 - 消费者队列;不支持任何类型的“关闭”或“关闭”操作,表示不再添加项目实现是线程安全的;
(2)PriorityQueue:基于优先级堆的无限优先级queue 。 优先级队列的元素根据它们的有序natural ordering ,或由一个Comparator在队列构造的时候提供,这取决于所使用的构造方法。 优先队列不允许null元素。 依靠自然排序的优先级队列也不允许插入不可比较的对象(这样做可能导致ClassCastException )。该队列的头部是相对于指定顺序的最小元素。 如果多个元素被绑定到最小值,那么头就是这些元素之一 - 关系被任意破坏。 队列检索操作poll , remove , peek和element访问在队列的头部的元件。优先级队列是无限制的,但是具有管理用于在队列上存储元素的数组的大小的内部容量 。 它始终至少与队列大小一样大。 当元素被添加到优先级队列中时,其容量会自动增长。 没有规定增长政策的细节。该类及其迭代器实现Collection和Iterator接口的所有可选方法。 方法iterator()中提供的迭代器不能保证以任何特定顺序遍历优先级队列的元素。 如果需要有序遍历,请考虑使用Arrays.sort(pq.toArray()) 。请注意,此实现不同步。 如果任何线程修改队列,多线程不应同时访问PriorityQueue实例。 而是使用线程安全的PriorityBlockingQueue类。实现注意事项:此实现提供了O(log(n))的时间入队和出队方法( offer , poll , remove()和add ); remove(Object)和contains(Object)方法的线性时间; 和恒定时间检索方法( peek , element和size )。
(3)ConcurrentLinkedQueue:基于链接节点的无界并发deque(deque是双端队列) 。 并发插入,删除和访问操作可以跨多个线程安全执行。 A ConcurrentLinkedDeque是许多线程将共享对公共集合的访问的适当选择。像大多数其他并发集合实现一样,此类不允许使用null元素。
23 中间件
中间件是一种独立的系统软件或服务程序,分布式应用软件借助这种软件在不同的技术之间共享资源。中间件位于客户机/ 服务器的操作系统之上,管理计算机资源和网络通讯。是连接两个独立应用程序或独立系统的软件。相连接的系统,即使它们具有不同的接口,但通过中间件相互之间仍能交换信息。执行中间件的一个关键途径是信息传递。通过中间件,应用程序可以工作于多平台或OS环境。(简单来说,中间件并不能提高内核的效率,一般只是负责网络信息的分发处理)。
24hashMap知识点
在这里帮大家总结一下hashMap和hashtable方面的知识点吧: 1. 关于HashMap的一些说法: a) HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。HashMap的底层结构是一个数组,数组中的每一项是一条链表。 b) HashMap的实例有俩个参数影响其性能: “初始容量” 和 装填因子。 c) HashMap实现不同步,线程不安全。 HashTable线程安全 d) HashMap中的key-value都是存储在Entry中的。 e) HashMap可以存null键和null值,不保证元素的顺序恒久不变,它的底层使用的是数组和链表,通过hashCode()方法和equals方法保证键的唯一性 f) 解决冲突主要有三种方法:定址法,拉链法,再散列法。HashMap是采用拉链法解决哈希冲突的。 注: 链表法是将相同hash值的对象组成一个链表放在hash值对应的槽位; 用开放定址法解决冲突的做法是:当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。 沿此序列逐个单元地查找,直到找到给定 的关键字,或者碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。 拉链法解决冲突的做法是: 将所有关键字为同义词的结点链接在同一个单链表中 。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数 组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。在拉链法中,装填因子α可以大于1,但一般均取α≤1。拉链法适合未规定元素的大小。 2. Hashtable和HashMap的区别: a) 继承不同。 public class Hashtable extends Dictionary implements Map public class HashMap extends AbstractMap implements Map b) Hashtable中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。 c) Hashtable 中, key 和 value 都不允许出现 null 值。 在 HashMap 中, null 可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为 null 。当 get() 方法返回 null 值时,即可以表示 HashMap 中没有该键,也可以表示该键所对应的值为 null 。因此,在 HashMap 中不能由 get() 方法来判断 HashMap 中是否存在某个键, 而应该用 containsKey() 方法来判断。 d) 两个遍历方式的内部实现上不同。Hashtable、HashMap都使用了Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。 e) 哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。 f) Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。 注: HashSet子类依靠hashCode()和equal()方法来区分重复元素。 HashSet内部使用Map保存数据,即将HashSet的数据作为Map的key值保存,这也是HashSet中元素不能重复的原因。而Map中保存key值的,会去判断当前Map中是否含有该Key对象,内部是先通过key的hashCode,确定有相同的hashCode之后,再通过equals方法判断是否相同。
25. 同步器
(1)Java 并发库 的Semaphore 可以很轻松完成信号量控制,Semaphore可以控制某个资源可被同时访问的个数,通过 acquire() 获取一个许可,如果没有就等待,而 release() 释放一个许可。
(2)CyclicBarrier 主要的方法就是一个:await()。await() 方法没被调用一次,计数便会减少1,并阻塞住当前线程。当计数减至0时,阻塞解除,所有在此 CyclicBarrier 上面阻塞的线程开始运行。
(3)直译过来就是倒计数(CountDown)门闩(Latch)。倒计数不用说,门闩的意思顾名思义就是阻止前进。在这里就是指 CountDownLatch.await() 方法在倒计数为0之前会阻塞当前线程。
26.静态内部类
(1)静态内部类不能直接访问外部类的非静态成员,但可以通过new 外部类成员的方式访问
(2)如果外部类的静态成员与内部类的成员名称相同,可以通过“类名。静态成员”访问外部类的静态成员“
(3)创建静态内部类的对象时,不需要外部类的对象,可以直接创建内部类 对象名=new 内部类();
27子类和父类
(1)子类的权限不能比父类更低
28 JAVA五个基本原则
(1)单一职责原则(Single-Resposibility Principle):一个类,最好只做一件事,只有一个引起它的变化。单一职责原则可以看做是低耦合、高内聚在面向对象原则上的引申,将职责定义为引起变化的原因,以提高内聚性来引起变化的原因。
(2)开放封闭原则(Open-Closed principle):软件实体应该是可扩展的,而不可修改的。也就是对扩展开放,对修改封闭。
(3)Liskov替换原则(Liskov-Substitution Principle):子类必须能够替换其基类。这一思想体现为对继承机制约束规范,只有子类能够替换基类时,才能保证系统在运行期内识别子类,这是保证复用的基础。
(4)依赖倒置原则(Dependecy-Inversion Principle):依赖于抽象。具体而言就是高层模块不依赖于底层模块,二者都同依赖于抽象;抽象不依赖具体,具体依赖于抽象。
(5)接口隔离原则(Interface-Segregation Principle):使用多个晓的专门的接口,而不要使用一个大的总接口。
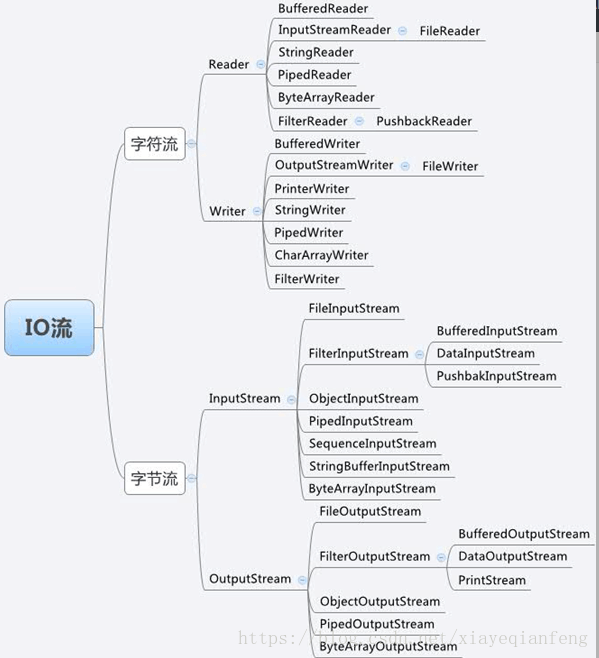
29.IO流
30、前台线程和后台线程的区别和联系
(1)后台线程不会阻止进程的终止。属于某个进程的所有前台线程都终止后,该进程就会被终止。所有剩余的后台线程都会停止且不会完成。
(2)可以在任何时候将前台线程修改为后台线程,方式是设置Thread.IsBackground属性。
(3)不管是前台线程还是后台线程,如果线程出现了异常,都会导致进程的终止。
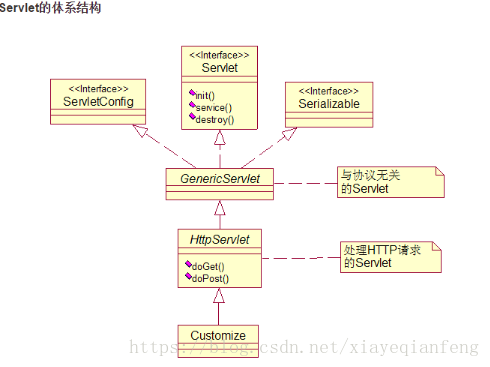
31、Servlet体系结构
32 网页
(1)request.getAttrribute()方法返回request范围内存在的对象,而request.getParameter()方法是获取http提交过来的数据。 getAttribute是返回对象,getParameter返回字符串。
(2) HttpServletResponse完成:设置http头标志,设置cookie,设置返回数据类型,输出返回数据。
(3)HttpServletRequest:读取路径
(4)ServletContext:getParameter()是获取POST/GET传递的参数值;getInitParameter获取Tomcat的server.xml中设置Context的初始化参数;getAttibute()是获取对象容器的数据值;getRequestDispatcher是请求转发。
33 子类重写父类方法
(1)子类重写父类方法是,方法的访问权限不能小于原访问权限,在接口中,方法的默认权限就是public,所以子类重写后只能是public。
34 并发带来的问题
(1)丢失修改
下面我们先来看一个例子,说明并发操作带来的数据的不一致性问题。
考虑飞机订票系统中的一个活动序列:
甲售票点(甲事务)读出某航班的机票余额A,设A=16.
乙售票点(乙事务)读出同一航班的机票余额A,也为16.
甲售票点卖出一张机票,修改余额A←A-1.所以A为15,把A写回数据库.
乙售票点也卖出一张机票,修改余额A←A-1.所以A为15,把A写回数据库.
结果明明卖出两张机票,数据库中机票余额只减少1。
归纳起来就是:两个事务T1和T2读入同一数据并修改,T2提交的结果破坏了T1提交的结果,导致T1的修改被丢失。前文(2.1.4数据删除与更新)中提到的问题及解决办法往往是针对此类并发问题的。但仍然有几类问题通过上面的方法解决不了,那就是:
(2)不可重复读
不可重复读是指事务T1读取数据后,事务T2执行更新操作,使T1无法再现前一次读取结果。具体地讲,不可重复读包括三种情况:
事务T1读取某一数据后,事务T2对其做了修改,当事务1再次读该数据时,得到与前一次不同的值。例如,T1读取B=100进行运算,T2读取同一数据B,对其进行修改后将B=200写回数据库。T1为了对读取值校对重读B,B已为200,与第一次读取值不一致。
事务T1按一定条件从数据库中读取了某些数据记录后,事务T2删除了其中部分记录,当T1再次按相同条件读取数据时,发现某些记录神密地消失了。
事务T1按一定条件从数据库中读取某些数据记录后,事务T2插入了一些记录,当T1再次按相同条件读取数据时,发现多了一些记录。(这也叫做幻影读)
(3) 读"脏"数据
读"脏"数据是指事务T1修改某一数据,并将其写回磁盘,事务T2读取同一数据后,T1由于某种原因被撤消,这时T1已修改过的数据恢复原值,T2读到的数据就与数据库中的数据不一致,则T2读到的数据就为"脏"数据,即不正确的数据。
产生上述三类数据不一致性的主要原因是并发操作破坏了事务的隔离性。并发控制就是要用正确的方式调度并发操作,使一个用户事务的执行不受其它事务的干扰,从而避免造成数据的不一致性。
35 创建线程的方法
1、继承Thread类创建线程
2、实现Runnable接口创建线程
3、实现Callable接口通过FutureTask包装器来创建Thread线程
4、使用ExecutorService、Callable、Future实现有返回结果的线程
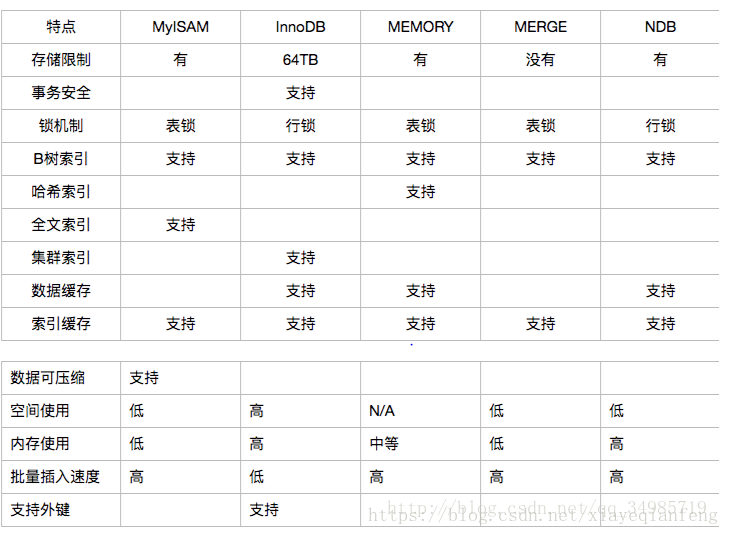
36 mysql常用数据引擎
37数据池连接
在Java中使用得比较流行的数据库连接池主要有:DBCP,c3p0,druid。
另外,不论使用什么连接池,低层都是使用JDBC连接,即:在应用程序中都需要加载JDBC驱动程序。
DBCP
https://commons.apache.org/proper/commons-dbcp/index.html
DBCP是Apache下独立的数据库连接池组件,在Tomcat中使用的连接池组件就是DBCP,支持JDBC3,JDBC4。关于更多JDBC版本信息,详见:https://en.wikipedia.org/wiki/Java_Database_Connectivity。
c3p0
http://www.mchange.com/projects/c3p0/
使用c3p0有多种方式,如:既可以直接使用API方式配置c3p0,也可以通过文件的方式进行配置,配置文件有2种形式:properties或xml文件。
druid
https://github.com/alibaba/druid
阿里开源的druid不单纯是一个连接池,还添加了监控功能,目前已经是非常受推崇的连接池组件,详细配置参数请参考官网。
当然,还存在一些其他的数据库连接池实现,例如:Tomcat自己就实现了一个连接池组件,根据官方的说法,这个连接池正是为了在Tomcat中替换DBCP,详见:https://tomcat.apache.org/tomcat-7.0-doc/jdbc-pool.html。
38 实现对象克隆有两种方式:
1). 实现Cloneable接口并重写Object类中的clone()方法;
2). 实现Serializable接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆。
39 线程池使用注意事项
- 死锁
任何多线程程序都有死锁的风险,最简单的情形是两个线程AB,A持有锁1,请求锁2,B持有锁2,请求锁1。(这种情况在mysql的排他锁也会出现,不会数据库会直接报错提示)。线程池中还有另一种死锁:假设线程池中的所有工作线程都在执行各自任务时被阻塞,它们在等待某个任务A的执行结果。而任务A却处于队列中,由于没有空闲线程,一直无法得以执行。这样线程池的所有资源将一直阻塞下去,死锁也就产生了。
- 系统资源不足
如果线程池中的线程数目非常多,这些线程会消耗包括内存和其他系统资源在内的大量资源,从而严重影响系统性能。
- 并发错误
线程池的工作队列依靠wait()和notify()方法来使工作线程及时取得任务,但这两个方法难以使用。如果代码错误,可能会丢失通知,导致工作线程一直保持空闲的状态,无视工作队列中需要处理的任务。因为最好使用一些比较成熟的线程池。
- 线程泄漏
使用线程池的一个严重风险是线程泄漏。对于工作线程数目固定的线程池,如果工作线程在执行任务时抛出RuntimeException或Error,并且这些异常或错误没有被捕获,那么这个工作线程就异常终止,使线程池永久丢失了一个线程。(这一点太有意思)
另一种情况是,工作线程在执行一个任务时被阻塞,如果等待用户的输入数据,但是用户一直不输入数据,导致这个线程一直被阻塞。这样的工作线程名存实亡,它实际上不执行任何任务了。如果线程池中的所有线程都处于这样的状态,那么线程池就无法加入新的任务了。
- 任务过载
当工作线程队列中有大量排队等待执行的任务时,这些任务本身可能会消耗太多的系统资源和引起资源缺乏。
综上所述,使用线程池时,要遵循以下原则:
- 如果任务A在执行过程中需要同步等待任务B的执行结果,那么任务A不适合加入到线程池的工作队列中。如果把像任务A一样的需要等待其他任务执行结果的加入到队列中,可能造成死锁
-
如果执行某个任务时可能会阻塞,并且是长时间的阻塞,则应该设定超时时间,避免工作线程永久的阻塞下去而导致线程泄漏。在服务器才程序中,当线程等待客户连接,或者等待客户发送的数据时,都可能造成阻塞,可以通过以下方式设置时间:
调用ServerSocket的setSotimeout方法,设定等待客户连接的超时时间。
对于每个与客户连接的socket,调用该socket的setSoTImeout方法,设定等待客户发送数据的超时时间。
- 了解任务的特点,分析任务是执行经常会阻塞io操作,还是执行一直不会阻塞的运算操作。前者时断时续的占用cpu,而后者具有更高的利用率。预计完成任务大概需要多长时间,是短时间任务还是长时间任务,然后根据任务的特点,对任务进行分类,然后把不同类型的任务加入到不同的线程池的工作队列中,这样就可以根据任务的特点,分配调整每个线程池
- 调整线程池的大小。线程池的最佳大小主要取决于系统的可用cpu的数目,以及工作队列中任务的特点。假如一个具有N个cpu的系统上只有一个工作队列,并且其中全部是运算性质(不会阻塞)的任务,那么当线程池拥有N或N+1个工作线程时,一般会获得最大的cpu使用率。
如果工作队列中包含会执行IO操作并经常阻塞的任务,则要让线程池的大小超过可用 cpu的数量,因为并不是所有的工作线程都一直在工作。选择一个典型的任务,然后估计在执行这个任务的工程中,等待时间与实际占用cpu进行运算的时间的比例WT/ST。对于一个具有N个cpu的系统,需要设置大约N*(1+WT/ST)个线程来保证cpu得到充分利用。
当然,cpu利用率不是调整线程池过程中唯一要考虑的事项,随着线程池工作数目的增长,还会碰到内存或者其他资源的限制,如套接字,打开的文件句柄或数据库连接数目等。要保证多线程消耗的系统资源在系统承受的范围之内。
- 避免任务过载。服务器应根据系统的承载能力,限制客户并发连接的数目。当客户的连接超过了限制值,服务器可以拒绝连接,并进行友好提示,或者限制队列长度.