1.为什么要主从复制,读写分离?
通过主从复制,可以配置多节点的数据库,从而使得数据安全上有较大提升,其中有一个节点宕机后另外节点还可以备用,且能起到数据备份的作用.读写分离则可以使得数据库性能有较大提升,因为mysql的读和写的引擎效率是不一样的,读引擎处理数据要比写引擎快,所以将其分开,由master负责写,slave负责读,在一些读操作明细多于写操作的系统中,可以搭载多个读的节点,各个读节点通过负载均衡可以使mysql处理数据的效率变高.
2.实现主从复制的两种方式
2.1基于日志的复制
在Mysql5.7.6之前,均采用这种方式
原理:主库的操作记录到日志中,从库读取主库的操作日志,从而将数据添加到从库中.
实现步骤:
①:在master端创建复制用户,这里我以root为例.
在mysql5.7之前的版本中:grant replication slave on *.* to 'root'@'119.1.2.3'(填你自己主服务器的Ip) identified by '123456'(自己分配)
在mysql5.7之后,推荐使用:
create user 'root'@'119.1.2.3' identified by '123456';
grant replication slave on *.* to root@'119.1.2.3';
②:备份master端的数据,并在slave端恢复.
新建一个测试库,取名Test(随意取),然后在该库下随便建张表取名T(随意取),然后插几条数据.
然后随便找个目录 比如/tmp下 执行 mysqldump --single-transaction --master-data=2 --trigger --routines --all-databases -uroot -p >xxx.sql 命令.(其中第一个参数是为了保证数据的完整性,第二个参数为1时,不会注销change master命令,为2时会注销,第三个参数是触发器,如果有触发器的话需要加上该参数,第四个参数是包含存储过程时使用,第五个参数是备份所有数据)
执行并输入密码后在tmp目录下可以找到名为xxx.sql的文件,然后使用scp命令将其拷贝到slave服务器上:
scp xxx.sql [email protected]:/tmp
然后切换到slave服务器上,在tmp目录下找到xxx.sql文件,然后导入到slave数据库中:
mysql -uroot -p <xxx.sql
导入完后打开xxx.sql文件 找到change master对应的master_log_file和master_log_pos并记录

③:使用change master命令配置复制.
change master to master_host='119.1.2.3',master_user='root',master_password='123456',master_log_file='mysql-bin.000004',master_log_pos=1687; (file和pos为步骤②中最后一步中得到的)
然后执行:
start slave;启动slave
show slave status \G 竖状查看 当io和sql都为yes时即配置成功,如果为No时请用tail -f /var/logs/mysql.log查看提示及关闭防火墙后重新启动slave;

至此,基于事务的配置即配置成功,可以在主数据库中添加一条数据,然后在从数据库中查看,一看果然有数据进来了,皆大欢喜.
※花絮:查看主从管理系统的视图
mysql中提供了一系列用于查看视图的表,放在performance_schema库中,其中以replication开头的这些表都是用于主从管理的视图表.
具体的哪张表是干嘛的就不多解释了,感兴趣可以去进一步去上网了解.
2.2基于事务的复制
首先要确保所有节点的Mysql版本大于等于5.7.6
下面演示如何将基于日志的复制变更为基于事务的复制:
①:修改主从的强制一致性gtid为warn:set @@global.enforce_gtid_consistency=warn;执行后需要在mysql的log中确认无错误信息.
②:修改主从的强制一致性gtid为on:set @@global.enforce_gtid_consistency=on;
③:修改主从的gtid_mode状态:set @@global.gtid_mode=off_permissive;(gtid_mode有4个状态:off,off_permissive,on_permissive,on;四种状态,off->on的改变需要通过permissive过渡.) 修改完后tail -f 查看mysql log是否有错误信息,确认主从均无错误信息后方可下一步操作.
④:修改主从的gtid_mode状态: set @@global.gtid_mode=on_permissive;
⑤:查看是否存在匿名复制,也即基于日志的复制数量:show status like 'ongoing_anonymouse_transcation_count'; 如果为空或0,即认为不存在.
⑥:以上步骤确认无误后,在主从上分别执行:set @@global.gtid_mode=on; 正式启动gtid复制模式.
⑦:在从上执行:
stop slave;
change master to master_auto_position=1;
start slave;
show slave status \G 查看io和sql是否处于yes
最后一步,在/etc/my.cnf中添加gtid-mode=on和gtid-consistency=on,使下次重启mysql也可以自动开启基于事务复制.
3.多源复制(多Master)
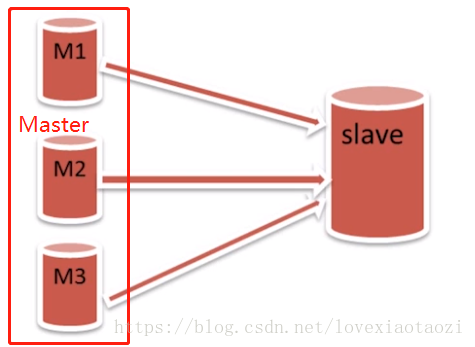
常被用于:当数据库进行分表后,需要将数据放在一起然后进行一些多表查询时,可以用这种方式.
以2中搭好的一主一从为基础,再添加一台主服务器M2,并将其gtid_mode设置为on状态.
创建M2上用于复制的用户:
create user root2@'121.1.2.3' identified by '123456'
grant replication slave on *.* to root @'121.1.2.3';
在原来的从服务器slave上执行:
change master to master_host='121.1.2.3',master_user='root2',master_password='123456',master_auto_position=1 for channel 'm2'; (这里m2可以随便取)
start slave for channel m2;
此时m2上数据已被复制到slave上.
4.多线程复制
当业务量比较大时,单线程复制效率会跟不上,这个时候需要配置多线程复制.
步骤:
show variables like 'slave_parallel%';
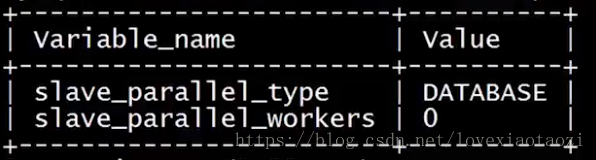
可以看到未启动多线程时的parallel_type为database
stop slave,然后设置parallel_type为logical_clock:
set global slave_parallel_type='logical_clock';
set global slave_parallel_workers=4; (设置线程数,根据cpu和业务量自由分配)
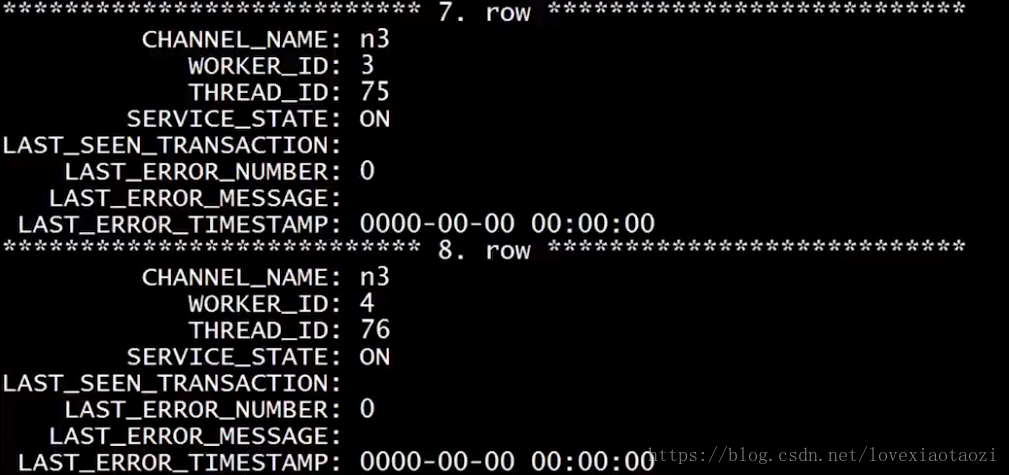
start slave;启动 然后查看 performance_schema库下的replication_applier_status_by_worker即可看到启动的所有线程.
好了,本期的课程就介绍到这里,请继续关注本博,下篇针对Mycat进行更接近企业应用级的mysql架构.