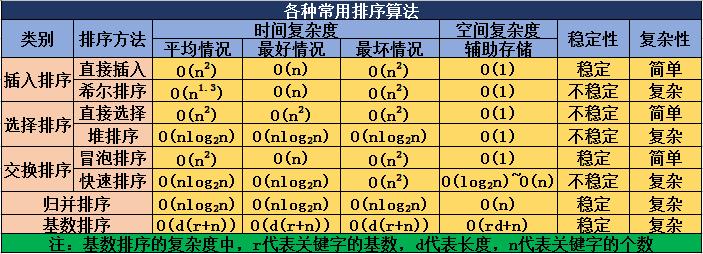
一、排序算法的分类(列举7种):
1.冒泡排序
2.选择排序
3.插入排序
4.快速排序
5.归并排序 (归并排序需要额外的内存空间来保存数据,其他的方式都是在原来数据上做交换)
6.希尔排序
7.堆排序
1、最基础的排序——冒泡排序 (时间复杂度是 O(N^2))
设无序数组a[]长度为N,以由小到大排序为例。冒泡的原理:
1.比较相邻的前两个数据,如果前面的数据a[0]大于后面的数据a[1] (为了稳定性,等于不交换),就将前面两个数据进行交换。在将计数器 i ++;
2.当遍历完N个数据一遍后,最大的数据就会沉底在数组最后a[N-1]。
3.然后N=N-1;再次进行遍历排序将第二大的数据沉到倒数第二位置上a[N-2]。再次重复,直到N=0;将所有数据排列完毕。
无序数组: 2 5 4 7 1 6 8 3
遍历1次后: 2 4 5 1 6 7 3 8
遍历2次后: 2 4 1 5 6 3 7 8
遍历3次后: 2 4 1 5 3 6 7 8
...
遍历7次后: 1 2 3 4 5 6 7 8
void BubbleSore(int *array, int n) //优化
{
int i = n;
int j = 0;
int temp = 0;
Boolean flag = TRUE;
while(flag){
flag = FALSE;
for(j = 1; j < i; ++j){
if(array[j - 1] > array[j]){
temp = array[j-1];
array[j - 1] = array[j];
array[j] = temp;
flag = TRUE;
}
}
i--;
}
}2、最易理解的排序——选择排序 (时间复杂度O(N^2))
原理:
遍历一遍找到最小的,与第一个位置的数进行交换。再遍历一遍找到第二小的,与第二个位置的数进行交换。
无序数组: 2 5 4 7 1 6 8 3
遍历1次后: 1 5 4 7 2 6 8 3
遍历2次后: 1 2 4 7 5 6 8 3
...
遍历7次后: 1 2 3 4 5 6 7 8
void Selectsort(int *array, int n)
{
int i = 0;
int j = 0;
int min = 0;
int temp = 0;
for(i; i < n; i++){
min = i;
for(j = i + 1; j < n; j++){
if(array[min] > array[j])
min = j;
}
temp = array[min];
array[min] = array[i];
array[i] = temp;
}
}3、扑克牌法排序——插入排序 (时间复杂度是O(N^2))
插入的原理:
1.初始时,第一个数据a[0]自成有序数组,后面的a[1]~a[N-1]为无序数组。令 i = 1;
2.将第二个数据a[1]加入有序序列a[0]中,使a[0]~a[1]变为有序序列。i++;
3.重复循环第二步,直到将后面的所有无序数插入到前面的有序数列内,排序完成。
无序数组: 2 | 5 4 7 1 6 8 3
遍历1次后: 2 5 | 4 7 1 6 8 3
遍历2次后: 2 4 5 | 7 1 6 8 3
遍历3次后: 2 4 5 7 | 1 6 8 3
...
插入排序是一种比较快的排序,因为它每次都是和有序的数列进行比较插入,所以每次的比较很有”意义”,导致交换次数较少,所以插入排序在O(N^2)级别的排序中是比较快的排序算法。
{
int i = 0;
int j = 0;
int temp = 0;
for(i = 1; i < n; i++){
if(array[i] < array[i-1]){
temp = array[i];
for(j = i - 1; j >= 0 && array[j] > temp; j--){
array[j+1] = array[j];
}
array[j+1] = temp;
}
}
}4、最快的排序——快速排序(时间复杂度O(N * log N))
原理:
1、先从数列中取出一个数作为基准数
2、分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边
3、再对左右区间重复第二步,直到各区间只有一个数
参考博客:https://blog.csdn.net/vayne_xiao/article/details/53508973
5、分而治之——归并排序 (时间复杂度O(N * log N))
原理:
归并就是采用这种操作,首先将有序数列一分二,二分四……直到每个区都只有一个数据,可以看做有序序列。然后进行合并,每次合并都是有序序列在合并,所以效率比较高。
无序数组: 2 5 4 7 1 6 8 3
第一步拆分:2 5 4 7 | 1 6 8 3
第二步拆分:2 5 | 4 7 | 1 6 | 8 3
第三步拆分:2 | 5 | 4 | 7 | 1 | 6 | 8 | 3
第一步合并:2 5 | 4 7 | 1 6 | 3 8
第二步合并:2 4 5 7 | 1 3 6 8
第三步合并:1 2 3 4 5 6 7 8
6、缩小增量——希尔排序 (时间复杂度O(N * log N))
希尔排序的实质就是分组插入排序,该方法又称为缩小增量排序,原理是:
希尔排序:将无序数组分割为若干个子序列,子序列不是逐段分割的,而是相隔特定的增量的子序列,对各个子序列进行插入排序;然后再选择一个更小的增量,再将数组分割为多个子序列进行排序......最后选择增量为1,即使用直接插入排序,使最终数组成为有序。
增量的选择:在每趟的排序过程都有一个增量,至少满足一个规则 增量关系 d[1] > d[2] > d[3] >..> d[t] = 1 (t趟排序);根据增量序列的选取其时间复杂度也会有变化,这个不少论文进行了研究,在此处就不再深究;本文采用首选增量为n/2,以此递推,每次增量为原先的1/2,直到增量为1;
参考博客:https://blog.csdn.net/jianfpeng241241/article/details/51707618
7、堆排序(时间复杂度为 O(N*logN))
完全二叉树的特点是:
1)只允许最后一层有空缺结点且空缺在右边,即叶子结点只能在层次最大的两层上出现;
2)对任一结点,如果其右子树的深度为j,则其左子树的深度必为j或j+1。 即度为1的点只有1个或0个
完全二叉树第i层至多有2^(i-1)个节点,共i层的完全二叉树最多有2^i-1个节点。
堆是具有以下性质的完全二叉树:
- 每个结点的值都大于或等于其左右孩子结点的值,称为大根堆;
- 或者每个结点的值都小于或等于其左右孩子结点的值,称为小根堆。