同步IO:CPU等该条命令执行完再执行下一条命令
异步IO:CPU不等待该条命令执行完就执行下一条命令。分为回调模式、轮询模
文件读写
无论能否正确打开文件,都能关闭:
with open() as file:read()
每次读取整个文件,将文件内容放到一个字符串变量中,如果文件大于可用内存,不能使用这种处理。
codecs模块在读文件时自动转换编码:
import codecs
with codecs.open("test.txt",'r','utf-8') as data:
for seq in data.read().strip().split('\n'):
print seq.split('\t')[1]readlines()
一次读取整个文件,自动将文件内容分析成一个行的列表。
for seq in data.readlines():
print seq.split('\t')[1]readline()
每次只读取一行,返回的是一个字符串对象,保存当前行的内容,通常比 .readlines() 慢得多,仅当没有足够内存可以一次读取整个文件时,才选择使用。
while True:
seq = data.readline()
if seq:
print seq.split('\t')[1]
else:
break读写标记
r只读,r+读写并覆写,不创建
w新建只写,不能读出,w+新建读写,二者都会将文件内容清零
r+:可读可写,若文件不存在,报错
w+: 可读可写,若文件不存在,创建
a:附加写方式打开,不可读
a+: 附加读写方式打开
不可读的打开方式:w和a
若不存在会创建新文件的打开方式:a,a+,w,w+
当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。
操作文件和目录
os.listdir() #返回指定路径下的文件和文件夹列表。
os.path.isdir() #判断路径是否为目录
os.path.isfile() #判断路径是否为文件
os.path.abspath(path) #返回path规范化的绝对路径
os.path.join('/gpfs/data','testfastq') #返回/gpfs/daa/testfastq
os.path.split(path) #将path分割成目录和文件名二元组返回
os.path.dirname(path) #返回文件路径,就是os.path.split(path)的第一个元素
os.path.basename(path) #返回文件名,就是os.path.split(path)的第二个元素
os.path.exists(path) #路径存在则返回True,路径损坏返回False
os.mkidr() #新建目录
os.rmdir() #删除目录
os.rename('a.txt','a.py') #重命名文件
os.remove() #删除文件
os.walk() #返回路径、子文件夹名字、文件名,再逐个显示子文件夹路径、子子文件夹名、文件名……文件夹名和文件名放在列表中。

os.path.splitext() #得到文件扩展名
序列化
把变量从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
dumps()方法返回一个str,内容就是标准的JSON。
dump()方法可以直接把JSON写入一个file-like Object。
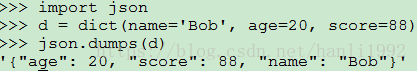

用loads()或者对应的load()方法,前者把JSON的字符串反序列化,后者从file-like Object中读取字符串并反序列化:
