Python,大家应该都不陌生了。如果你要设计机器学习领域,python应该是首选吧。我认为python的核心灵魂之处就是简洁。不知道大家知不知道,在交互环境下,IDLE下输入import this,就会打印出《Python之禅》:

蛮有趣的是不?其实当你编程的时候,可以先想想这几句话,有时候真的可以极大提高你的代码质量。如果说java c之类的语言就像“火影”,那我觉得python更像“海贼王”,不用背负那么多的责任,但仍旧是个大魔王。
话不多说,前几天写了一个简单爬虫,虽然代码没几行,但是遇到的问题不少。在这里简单示例的总结一下。也希望能对其 有兴趣的朋友一些帮助。
python第三方模块很多,你可以选择你喜欢的,我这里只是单一的介绍一种。
(一)
先来看一下怎样获取到一个网页的信息(html,js之类的)
这里我用到的第三方库是urllib,你可以在cmd中执行pip install 去安装它。你可以直接 pip install requests,requests之后会用到,而且同时也会把urllib安装好。(建议大家用python3.6,3.7可能存在导包错误的问题)
首先你先要获得你想的得到的网页的url,也就是网址,我们这里以百度为例。https://www.baidu.com/
代码如下:
import urllib.request
url = 'https://www.baidu.com/'
request = urllib.request.urlopen(url)
html = request.read().decode('uft-8')
print(html)urllib.request.urlopen函数的参数要传递一个网址,返回给变量request,然后调用read()函数,读出数据,decode是编码方式。如果不写默认是utf-8。你会得到这么条信息,为什么那么少呢。这里涉及到动态数据的知识,不做介绍,有兴趣的同学可以去查询。

(二)
现在我们得到了网页信息(大家至少要对标记语言有些了解,但不会太影响到下面的内容,如果看不太懂了就去查下),接下来要做的就是获得其中我们需要的信息了。这是我们把网址换成我们csdn的主页https://www.csdn.net/。
执行完毕后是不是震惊了,好多数据啊。大约在这里,有个img

我们点进去后,发现是

也就是我们网页的这里

好,接下来让我们看看怎样把它用程序下下来吧。
上个程序中的html变量,其实是str类型,也就是说,你获得这些东西,完全可以当成字符串处理,去获得那个img。我们单线网页中有太多的标记。<img><head><p><body>等等,这些字符串处理是很难得。
我们用到了另一个模块,beautifulsoup,专门用来处理网页信息。cmd下安装:pip install bs4。
代码如下:
import urllib.request
from bs4 import BeautifulSoup
#获得信息
url = 'https://www.csdn.net/'
request = urllib.request.urlopen(url)
html = request.read().decode()
#处理信息
bs = BeautifulSoup(html,'html.parser')
img = bs.find('img')
print(img)
调用beautifulsoup函数,第一个参数就是你刚刚获得的一堆东西(str)。让beautifulsoup全部吞掉,后一个参数是处理的方式。应该有四种,我选择了其中一种。(大家感兴趣可以去查其他的,并看看区别所在。)
我们要获取<img **************>这个东西,我们可以看到我们要的img是网页中的第一个img,这里调用bs对象的find方法,参数就是你要获取的标记。他就会返回第一个,如果你想获取网页上所有的img呢?那就调用find_all( )函数,他就会返回所有的img。输出:

得到了还不是我们想要的,我们只要src的内容。ok,print(img['src'])
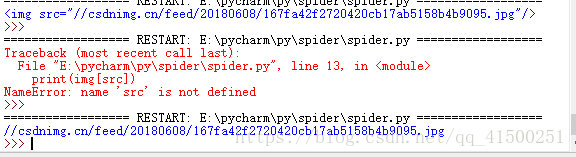
成功。
(三)
接下来就来下载图片吧。
我们现在得到了新的url,但他不是标准的url,在使用前,将其补全https://**********
当然视情况而定,获得的url不一定全是残缺的。
这里涉及到文件的内容。简单提下:例 f = open('','') 。open函数会返回一个指针,两个参数,第一个,文件地址,或者说路径,第二个参数是 打开方式。w(写) r(读) b(二进制数据) a(追加)等等
代码如下:
import urllib.request
from bs4 import BeautifulSoup
#获得信息
url = 'https://www.csdn.net/'
request = urllib.request.urlopen(url)
html = request.read().decode()
#处理信息
bs = BeautifulSoup(html,'html.parser')
img = bs.find('img')
#下载图片
url = 'https:'+img['src']
picture = urllib.request.urlopen(url).read()
f = open('F:1.jpg','wb')
f.write(picture)
f.close()
'''
可以替换前面三句
with open('F:1.jpg','wb') as f:
f.wirte(picture)
'''
前面相同,我们获得网页的内容,然后打开文件,F盘下的1.jpg文件。如果没有怎么办呢?不用担心,因为我们打开的方式是‘wb’,是以二进制的方式写入,写入的时候,如果找不到文件,就会自动创建。
然后,f.write( )将picture写入1.jpg,记得一定要close()。我们可以把它理解为我们在写完东西后随手点的“保存”。如果不写,那就相当于直接点×了。
下面的是一种简单的方式,和上面的三句功能完全相同。但明显简单不少。(python的魅力啊~)
去我们选择的路径下,看到了
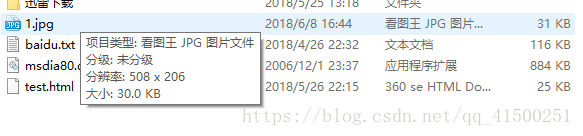
打开查看一下

恭喜你成功了。用这种方法你就可以去得到你想要的东西啦。,mp3的音乐文件,也是可以的,其余都相同,记得写入的文件一定要是.mp3拓展名,才能执行。这张图片是.jpg的,通过url你可以看到他的拓展名是什么,写入的文件最好和其相同。
(如果爬的数据较多,记得巧妙运用循环哦)
—————————————————————————————————————————————————————
ok,这些一般就够用了,之后的是一些比价高级的。我纯粹是为了笔迹。不会再说的那么详细。感兴趣的同学可以看看。
import urllib.parse
key = urllib.parse.quote(name) 可以将汉字转化成十六进制码(应该是吧),可以用于一些搜索。
import json
jd = json.loads(html)
print(jd['data']['song']) 处理json文件,loads函数的参数是str类型,对象jd数据就可以理解成字典来使用。
伪装爬虫:
url = ""
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
data = res.read()感谢观看