人生不易且无趣,一起找点乐子吧。欢迎评论,和文章无关也可以。
有了前两篇文章做基础,我们来实战,用爬虫来实现翻译器。
我的浏览器是360的,一般搜索“翻译”的时候,跳出来的都是360翻译。like that:

写代码前分析下,我们在输入框输入一些信息,信息被提交到服务器,服务器处理完后,将翻译结果返回,解析后显示到页面。我们就看到了翻译结果,我们要做的:
1、找到返回信息的url。
2、提取需要信息。
来看原始地址

当我们在输入框输入信息的时候,看看变化:

这时的地址也就相应的变化:

再来测试:

地址变化:
![]()
有找到规律吗?基本就是我们的输出内容,这也就是传给服务器的参数,我们看到空格的url编码编程了%20(这里我不知道说的准不准确,就是对空格进行了可以传输的格式转化。)
我们找到了url,然后提取所需信息,也就是页面上“我是一条鱼”的中文翻译。然而,当我们查看源代码的时候,在源代码里并没有我们所需信息,Why?
且听,源代码上展现出来的信息是不可变得,比如<title>主页</title>。它就只能显示出来“主页”,那如果我有许多网页,且网页大致的布局都差不多,只是title不一样,怎么办?多写几个网页不就完了。是,的确可以。如果我有一万个,即使可以ctrl c,ctrl v,不累吗。
所以,一般布局一样,只是个别东西不同,我门就把那个位置设置成一个变量,让后根据服务器返回的参数值对变量赋值,从而在网页上显示文本。
所以现在我们的任务是找到那个传递参数的url,而不是源代码的,记住,爬取动态数据,一般情况下源代码中是找不到的。
Do it.
大部分的浏览器都提供了控制台,一般情况下按F12键就会弹出,这里可以查看浏览器后台的一些操作。

切换到network模块,按下F5刷新,页面重新刷新,再输入文本,就能看到一些请求。

So many.你需要做的就是从众多返回中找到你想要的。
我们看到有个search?......的返回,而且后面的query显然是我们的输入结果。Get it. 鼠标右键。“Open in new tab”,就可以看到返回内容。

返回内容是个json,python理解成dict,当然理解成一个字符串也没什么问题,还是没有我们要的东西怎么办?其实不然,fanyi的关键词的value是"\u6211\u662f\u4e00\u6761\u9c7c\u3002",这么个东西,敏感的小朋友就知道了,这是Unicode编码,让我们用python直接把他输入来看看吧。
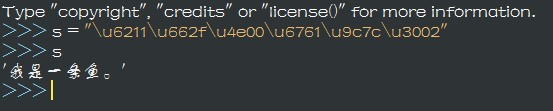
Suprise,这不就是我们想要的东西吗,看url是什么,再次进行分析。

没太大区别,空格用“+”代替,末尾多了个参数eng=1。也就是说当我们请求这个地址的时候,我们就能得到那个json,然后将fanyi的内容拿出来,任务就完成了。
怎么拿?是个问题,要知道,bs4是针对标记语言的,现在是json。没办法用,那就用字符串,问题又来了,你输入的信息不一样fanyi位置也不一样,怎么办?
python标准库json,直接导入就好,load完生成的对象,可以当成字典来用,很方便吧。
动手吧:
import requests
import json
def english_to_chinese(search):
base = 'https://fanyi.so.com/index/search?query='
url = base + search.replace(' ','+') + '&eng=1'
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(json.loads(r.text)['data']['fanyi'])
except:
print('Fail')
if __name__ == '__main__':
english_to_chinese(input('Please:'))前面讲的很详细,现在看代码就很好懂了吧。
这是英译汉的爬虫,汉译英的呢。

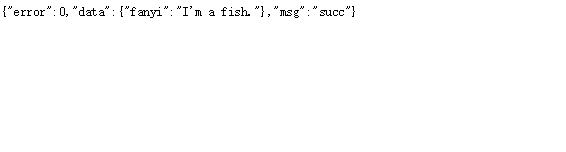
这个好,返回结果都不需要我们处理直接把fanyi内容拿出来就好。url呢?
![]()
哇塞!更简单直接写就好了。
问题来了,这是伪地址,鼠标左键点击地址看看:

显然,下面的才是我们能请求的,问题来了,文字转换成了一堆不知道是什么的东西,不用慌,为了数据的传输,要将汉子编写成url编码。
我们有库可用,urllib。
在安装requests的时候应该就已经同时安装上了,可以通过在命令行输入 pip list来查看是否有urllib库。urllib.parse.quote()方法可以将汉字转为url编码。还有一点注意,url中eng的参数值不是1了,而是0.
import urllib.parse
def english_to_chinese(search):
base = 'https://fanyi.so.com/index/search?query='
url = base + search.replace(' ','+') + '&eng=1'
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(json.loads(r.text)['data']['fanyi'])
except:
print('Fail')
def chinese_to_english(seatch):
base = 'https://fanyi.so.com/index/search?query='
url = base + urllib.parse.quote(seatch) + '&eng=0'
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(json.loads(r.text)['data']['fanyi'])
except:
print('Fail')
if __name__ == '__main__':
chose = input('1.English to chinese\n2.Chinese to english\n')
if chose == '1':
while 1:
english_to_chinese(input('Please:'))
elif chose == '2':
while 1:
chinese_to_english(input('请讲:'))
这里我把它们包装了一下更好看些吧。
试试效果:


还不赖吧。虽然翻译的有点糟。
基本已完,大家可以定向的去爬小说,图片。图片的保存方式在上篇中的链接中有。最后在说一下歌曲的保存,和图片是一样的。
你需要在代码中找到类似这样的东西:

我们看得到末尾是.mp3。就是他了,请求他返回的就是歌曲数据,记得保存的时候要以二进制文件去写。
import requests
url = 'http://fs.w.kugou.com/201811151711/88bca4fa27262892e1e66b38725bc683/G117/M05/14/09/VZQEAFpfZSqAPP3BAEHun0d8rZw177.mp3'
r = requests.get(url)
with open('等你下课.mp3', 'wb') as f:
f.write(r.content)原理就这样,代码超简单。视频是同样的道理,只要你能找到url。

ok,结束了,Thanks for watching.