1、概述
相信大家对正则表达式都不陌生,从linux下的命令到Java等编程语言,正则表达式无处不在,虽然我们实际使用的时候也并不一定太多,但是当我们要处理字符串时,它确实是一个强大的工具。
上一篇文章(Oracle中的字符串类型及相关函数详解)中,已经介绍了一些串相关的函数,也列出了用于正则表达式的函数,本文就正式介绍他们。
本文基于Oracle 12c ,可能部分内容在较老的版本中不适用。
运算符
在介绍函数前,这里先说明一下Oracle中正则表达式运算符及其描述。
如果不知道他们有什么用,或者也不知道描述说的是什么,没关系,可以先看后面的介绍,就知道他们的含义了。
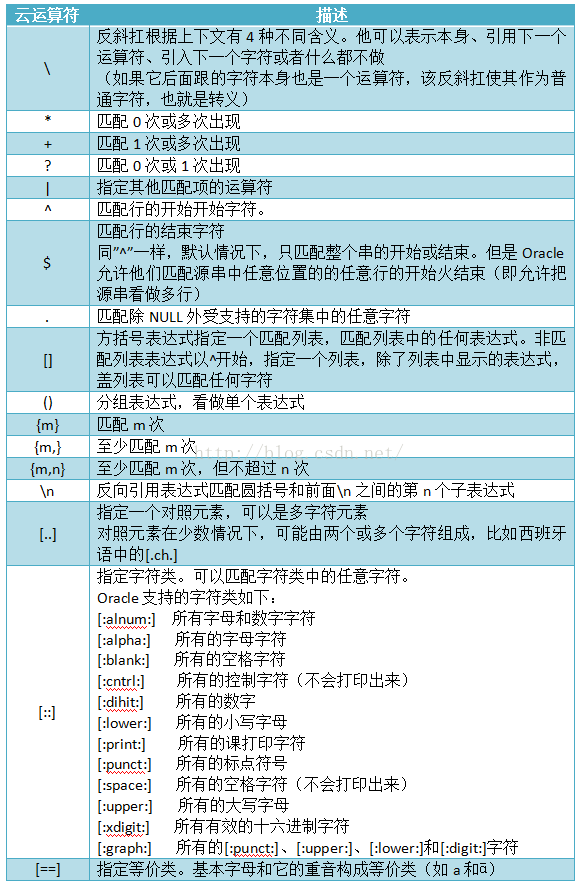
合理的使用这些运算符,配合正则表达式相关的函数,不但可以让字符串处理变得更加高效,还能大大的减少代码量。
2、相关函数
统一说明:
函数中pattern为正则表达式,最多可以包含512个字节。
下面的介绍中,是不同的函数,如若参数描述字符串相同,即他们的意思也是相同的(如regexp_substr函数和regexp_instr函数中的position意思都是表示开始搜索的位置),为了内容紧凑,只在那个参数第一次出现的地方作介绍。
参数带char的表示简单的串类型,带string的可以包含大对象串类型(如clob)。
惯例,“[]”表示可选参数。
2.1、REGEXP_SUBSTR
REGEXP_SUBSTR函数使用正则表达式来指定返回串的起点和终点。
语法:
regexp_substr(source_string,pattern[,position[,occurrence[,match_parameter]]])source_string:源串,可以是常量,也可以是某个值类型为串的列。
position:从源串开始搜索的位置。默认为1。
occurrence:指定源串中的第几次出现。默认值1.
match_parameter:文本量,进一步订制搜索,取值如下:
- ‘i’ 用于不区分大小写的匹配。
- ‘c’ 用于区分大小写的匹配。
- ‘n’ 允许将句点“.”作为通配符来匹配换行符。如果省略改参数,句点将不匹配换行符。
- ‘m’ 将源串视为多行。即将“^”和“$”分别看做源串中任意位置任意行的开始和结束,而不是看作整个源串的开始或结束。如果省略该参数,源串将被看作一行来处理。
- 如果取值不属于上述中的某个,将会报错。如果指定了多个互相矛盾的值,将使用最后一个值。如’ic’会被当做’c’处理。
- 省略该参数时:默认区分大小写、句点不匹配换行符、源串被看作一行。
例1:
select regexp_substr('MY INFO: Anxpp,22,and boy','my',1,1,'i') from users; 将返回MY,如果将match_parameter改为’c’将不返回任何内容(null)。
例2:
select regexp_substr('MY INFO: Anxpp,23,and boy','[[:digit:]]',1,2) from users;此处会返回3。
注意这里同时用到了“[]”和“[:digit:]”。
2.2、REGEXP_INSTR
REGEXP_INSTR函数使用正则表达式返回搜索模式的起点和终点(整数)。如果没有发现匹配的值,将返回0。
语法:
regexp_instr(source_string,pattern[,position[,occurrence[,return_option[,match_parameter]]]])return_option:为0时,返回第一个字符出现的位置,与instr作用相同。为1时,返回所搜索字符出现以后下一个字符的位置。默认为0。
例1:
select regexp_instr('MY INFO: Anxpp,23,and boy','[[:digit:]]') from users;该例会返回16。
REGEXP_INSTR函数常常会被用到where子句中。
2.3、REGEXP_LIKE
通常使用REGEXP_LIKE进行模糊匹配。
语法:
regexp_like(source_string,pattern[match_parameter])比如,查找电话好吗以666开头的:
select name from users where regexp_like(phone,'666');例1:
select * from users where regexp_like('MY INFO: Anxpp,23,and boy','[[:digit:]]');此例判断串中是否包含数字。
该函数可以使用前面介绍的所有搜索功能作为REGEXP_LIKE搜索的一部分,可以是非常复杂的搜索变得简单。
2.4、REPLACE和REGEXP_REPLACE
REPLACE函数用于替换串中的某个值。
语法:
replace(char,search_string[,replace_string])如果不指定replace_string,会将搜索到的值删除。
输入可以是任何字符数据类型:char,varchar2,nchar,nchar,nvarchar2,clob或nclob。
例1:
select replace('MY INFO: Anxpp,23,and boy','an') from users;返回:MY INFO: Anxpp,23,d boy
下面演示使用该函数计算某字串在源串中出现的次数:
select (length('MY INFO: Anxpp,23,and boy')-length(replace('MY INFO: Anxpp,23,and boy','an')))/length('an') from users;REGEXP_REPLACE是REPLACE的增强版,支持正则表达式,扩展了一些功能。
语法:
regexp_replace(source_string,pattern[,replace_string[,position[,occurrence[,match_parameter]]]])replace_string表示用什么来替换source_string中与pattern匹配的部分。
occurrence为非负整数,0表示所有匹配项都被替换,为正数时替换第n次匹配。
其他参数在前面都已经介绍过了。
例1:
想象这样一个场景:有一个分布式的爬虫,负责抓取网页的程序已经将数据存入数据库,而当前负责处理的程序需要从其中读取其中的一些数据,包括电话号码。号码一般是11为,前3位区号,中间4位表示交换机,再加上后面4位,格式也不能确定,我们可以试着用下面的SQL来读取,生成我们想要的格式:
select regexp_replace('电话:023 5868-8888 邮箱:[email protected]',
'.*([[:digit:]]{3})([^[:digit:]]{0,2})([[:digit:]]{4})([^[:digit:]]{0,2})([[:digit:]]{4}).*',
'(\1)\3\5'
) phone from users;该例返回:(023)58688888
“\1”、“\3”、“\5”分别表示第1、3、5个数据集。其他的,大家慢慢看就能看懂了。
配合where子句,可以限制要返回的行。
2.5、REGEXP_COUNT
REGEXP_COUNT函数返回在源串中出现的模式的次数,作为对REGEXP_INSTR函数的补充。
虽然COUNT是一个集合函数,操作的是行组,但是REGEXP_COUNT是单行函数,分别计算每一行。
语法:
regexp_count(source_char,pattern[,position[,match_param]])REGEXP_COUNT返回pattern在source_char串中出现的次数。如果未找到匹配,函数返回0。
- metch_param参数,相对于前面介绍的match_parameter参数多一个取值“x”。
- ‘x’:忽略空格字符。默认情况下,空格与自身想匹配。
- metch_param如果指定了多个互相矛盾的值,将使用最后一个值。
前面介绍了使用replace函数统计字串在源串中出现的次数,这里可以使用REGEXP_COUNT实现,而且看起来更简单:
select regexp_count('MY INFO: Anxpp,23,and boy','an') from users;返回:1
此处还是使用match_param参数进行不区分大小写搜索:
select regexp_count('MY INFO: Anxpp,23,and boy','an',1,'i') from users;返回:2
3、总结
以上正则表达式相关函数的使用,主要体现在对正则表达式的掌握程度上,如果精通了正则表达式,一些非常复杂的串处理,也能用比较简洁的代码完成。