对于正则表达式的中\B和\b 有些地方会出现弄不懂的情况
或许你看了下面这篇博客 你就能够对\B和\b认识加深了
根据查看API可以知道 \B和\b都是边界匹配符
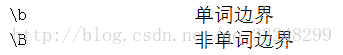
先说说\b这个单词边界吧!竟然想了解 首先必须清楚什么叫单词边界!我们可以以\b为分割来探究一下
单词边界
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class matcher1 {
public static void main(String[] args) {
String str="(中文问号?123???英文)问号?我是华丽[的制表符\t]我是华丽{的空格符 我是华丽}的换行符\n";
String rex="\\b";
Pattern pattern=Pattern.compile(rex);
Matcher matcher=pattern.matcher(str);
String [] result=pattern.split(str);
for(String string:result){
System.out.println("分割的字符串:"+"["+string+"]");
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
运行结果
分割的字符串:[(]
分割的字符串:[中文问号]
分割的字符串:[?]
分割的字符串:[123]
分割的字符串:[???]
分割的字符串:[英文]
分割的字符串:[)]
分割的字符串:[问号]
分割的字符串:[?]
分割的字符串:[我是华丽]
分割的字符串:[[]
分割的字符串:[的制表符]
分割的字符串:[ ]]
分割的字符串:[我是华丽]
分割的字符串:[{]
分割的字符串:[的空格符]
分割的字符串:[ ]
分割的字符串:[我是华丽]
分割的字符串:[}]
分割的字符串:[的换行符]
分割的字符串:[
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
从这些分割的字符串中我们可以知道单词边界就是单词和符号之间的边界
这里的单词可以是中文字符,英文字符,数字;符号可以是中文符号,英文符号,空格,制表符,换行
下面我们看一个例子
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class matcher1 {
public static void main(String[] args) {
String str=" 2 ";
String rex="\\b2\\b";
Pattern pattern=Pattern.compile(rex);
Matcher matcher=pattern.matcher(str);
if(matcher.matches()){
System.out.println("匹配成功");
}else{
System.out.println("匹配不成功");
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
在没有看上面分割的例子前估计很多人包括我都会认为这运行的结果是匹配成功
经过分割的例子后就知道了 空格并不是边界 空格与数字2之间的那个才叫边界 所以运行结果不言而喻 肯定是匹配不成功
当如果你这样写就运行出来就是匹配成功
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class matcher1 {
public static void main(String[] args) {
String str="2";
String rex="\\b2\\b";
Pattern pattern=Pattern.compile(rex);
Matcher matcher=pattern.matcher(str);
if(matcher.matches()){
System.out.println("匹配成功");
}else{
System.out.println("匹配不成功");
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
\b的用法
一般来说\b不用来判断当前字符串是否符合某种规则
一般我们都用\b来进行获取
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class matcher1 {
public static void main(String[] args) {
String str=",,,,呵呵,,,,";
String rex="\\b呵呵\\b";
Pattern pattern=Pattern.compile(rex);
Matcher matcher=pattern.matcher(str);
if(matcher.find()){
System.out.println(matcher.group());
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
运行结果
呵呵- 1
\B的用法
了解了\b的用法 我们再来说说\B \B是非单词边界
也就说\B=[^\b]//符号^是非的意思- 1
\b是单词与符号的边界 那非单词与符号的边界的其它都是\B
所以我们的猜想\B是符号与符号,单词与单词的边界
当然猜想需要认证!下面我们写一个例子来证明一个!
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class matcher1 {
public static void main(String[] args) {
String str="123456我是JAVA{,、;‘asd";
String rex="\\B";
Pattern pattern=Pattern.compile(rex);
Matcher matcher=pattern.matcher(str);
String [] result=pattern.split(str);
for(String string:result){
System.out.println("分割的字符串:"+string);
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
运行结果
分割的字符串:1
分割的字符串:2
分割的字符串:3
分割的字符串:4
分割的字符串:5
分割的字符串:6
分割的字符串:我
分割的字符串:是
分割的字符串:J
分割的字符串:A
分割的字符串:V
分割的字符串:A{ //单词与符号之间的边界不算\B的边界
分割的字符串:,
分割的字符串:、
分割的字符串:;
分割的字符串:‘a
分割的字符串:s
分割的字符串:d- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
事实证明\B作为非单词边界 确实是单词与单词,符号与符号之间的边界
\B一般也是用来获取字符串的
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class matcher1 {
public static void main(String[] args) {
String str=",,,,,和呵呵,,,,,";
String rex="\\B呵\\B";
Pattern pattern=Pattern.compile(rex);
Matcher matcher=pattern.matcher(str);
if(matcher.find()){
System.out.println(matcher.group());
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
因为字符与字符之间的边界
所以运行的结果是
呵- 1
END!!!!!!!!!!!!!!!