大数据指数据与大数据技术这二者的综合,而大数据技术,是指伴随着大数据的采集、传输、处理和应用的相关技术,通过一系列非传统的工具来对大量的结构化、半结构化和非结构化数据进行处理,从而获得分析和预测结果的一系列数据处理和分析技术。
大数据关键技术的不同层面及其功能
数据采集
利用ETL工具将分布的、异构数据源中的数据抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础;也可以把实时采集的数据作为流计算系统的输入,进行实时处理分析。
数据存储和管理
利用分布式文件系统、数据仓库、关系数据库、NoSQL数据库、云数据库等实现对结构化、半结构化和非结构化海量数据的存储和管理。
数据处理与分析
利用分布式并行编程模型和计算框架,结合机器学习和数据挖掘算法,实现对海量数据的处理和分析;对分析结果进行可视化呈现,帮助人们更好地理解、分析数据。
数据安全和隐私保护
构建隐私保护体系和数据安全体系,保护个人隐私和数据安全。
大数据计算模式
批处理计算
针对大规模数据的批量处理。
MapReduce可以并行执行大规模数据处理任务,用于大规模数据集的并行运算(单输入、两阶段、粗粒度数据并行的分布式框架)。它将复杂的、运行于大规模集群上的并行计算过程高度抽象到了两个函数——Map和Reduce,并把一个大数据集切分成多个小数据集,分布到不同的机器上进行并行处理,极大地方便了分布式编程工作。在MapReduce中,数据流从一个稳定的来源,进行一系列加工处理后,流出到一个稳定的文件系统(如HDFS)。
Spark是一个针对超大数据集合的低延迟的集群分布式计算系统。它启用了内存分布数据集,可以提供交互式查询、优化迭代工作负载。在MapReduce中,数据流从一个稳定的来源,进行一系列加工处理后,流出到一个稳定的文件系统(如HDFS)。而Spark则用内存替代HDFS或本地磁盘来存储中间结果,因此要快很多。
流计算
流数据(或数据流)是指在时间分布和数量上无限的一系列动态数据集合体,数据的价值随着时间的流逝而降低,因此必须实时计算给出秒级响应。业内有许多流计算框架与平台:第一类,商业级流计算平台(IBM InfoSphere Streams、IBM StreamBase等);第二类,开源流计算框架(Twitter Storm、S4等);第三类,公司为支持自身业务开发的流计算框架。
图计算
如Pregel、Giraph、GraphX、PowerGraph等。

查询分析计算
针对超大规模数据的存储管理和查询分析,需要提供实时或准实时响应。如Dremel、Impala等。
大数据与云计算、物联网
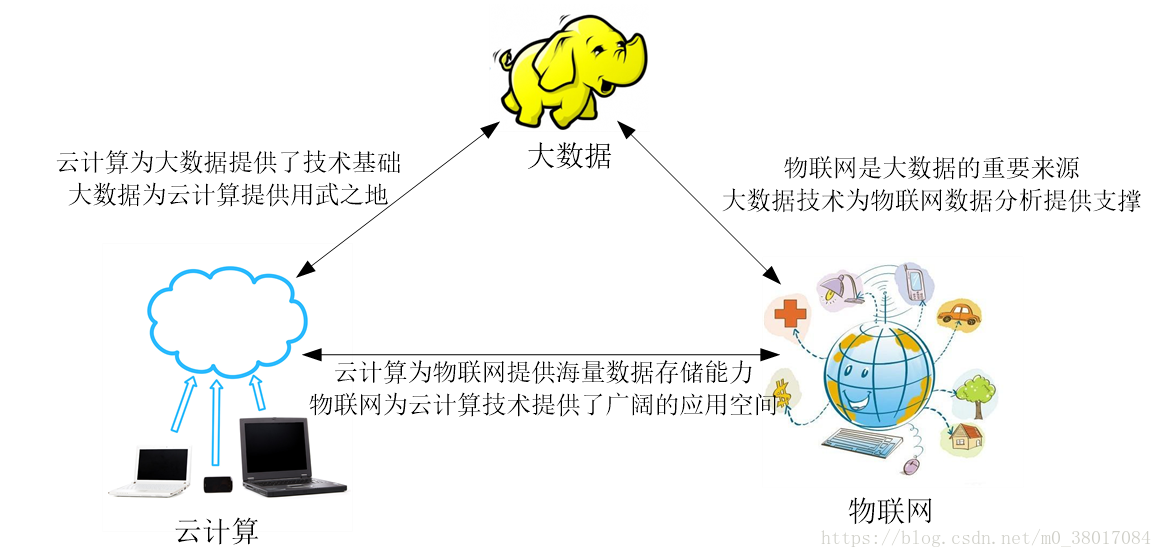
云计算
云计算的关键技术:虚拟化、分布式存储、分布式计算、多租户(数据隔离、客户化配置、架构扩展、性能定制)等。
物联网
物联网的技术架构:感知层、网络层、处理层、应用层。
物联网的关键技术:识别和感知技术、网络和通信技术、数据挖掘和融合技术。
三者之间的关系
1、区别。大数据侧重对海量数据的存储、处理、分析,发现价值,服务生活;云计算本质旨在整合和优化各种IT资源并通过网络以服务的方式,廉价地提供给用户;物联网的发展目标是实现物物相连,应用创新是物联网发展的核心。
2、联系。如上图所示,三者彼此渗透、相互融合。