一.支持向量机简介:
支持向量机是一种二分类模型。
他的基本模型是定义在特征空间上的间隔最大化的分类器,间隔最大化有别于感知机。
支持向量机还有核技巧,使他成为实质上的非线性分类器。
支持向量机的学习策略就是间隔最大化,可化为一个求解凸二次规划问题,也等价于正则化的合页 损失函数最小化 问题。
分为:
线性可分支持向量机(硬间隔支持向量机)
线性近似可分支持向量机(软间隔支持量机)
非线性支持向量机(核技巧和软间隔支持量机)
二.线性可分支持向量机:
第一部分:
给定线性可分 训练数据集,通过间隔最大化或等价的求解相应的凸二次规划问题学习得到分离超平面:

以及相应的决策函数:

下图中。表示正实例,“X”表示负实例,

插播一段函数间隔和几何间隔:
函数间隔的定义:

对于给定的训练集T和超平面(w,b),定义超平面关于样本点的函数间隔:


几何间隔:

一般形式:

第二部分:
支持向量机的基本思想:能够正确划分数据集 几何 间隔最大的超平面。
隔最大化:不仅将正负实例点分开,而且将最难分的实例点(离超平面最近)也有足够大的确信度将他们分开。
最大间隔分离超平面:下面的最优化问题:

优化:

等价优化:

3.总结间隔最大化流程:

4.支持向量和间隔边界:
对于正实例点的超平面:

对于负实例点的超平面:


间隔边界:

5.对偶算法:

定义拉格朗日函数:


求最小值(w,b):


等价于:


算法流程:


三.线性近似可分支持向量机(软间隔支持量机)
1.对于线性不可分训练数据要用软间隔最大化。
线性不可分:某些样本点不能满足函数间隔大于1的约束条件,引入一个松弛变量

目标函数变为:
线性不可分支持向量问题变为:

2.学习的对偶算法:

最优化问题:

3.合页损失函数:



4.最终流程:


四.非线性支持向量机(核技巧和软间隔支持量机):
1.核技巧思想:

2.核函数:

我们的对偶问题:


3.常用的核函数:
多项式核函数:

高斯核函数:

字符串核函数:
3.2:核函数的实质:
简要概括下,即以下三点:
- 实际中,我们会经常遇到线性不可分的样例,此时,我们的常用做法是把样例特征映射到高维空间中去(映射到高维空间后,相关特征便被分开了,也就达到了分类的目的);
- 但进一步,如果凡是遇到线性不可分的样例,一律映射到高维空间,那么这个维度大小是会高到可怕的(如10维乃至无穷维的例子)。那咋办呢?
- 此时,核函数就隆重登场了,核函数的价值在于它虽然也是将特征进行从低维到高维的转换,但核函数绝就绝在它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,也就如上文所说的避免了直接在高维空间中的复杂计算。
4.算法流程:

五.SMO算法:
1.KKT
我们已经使用拉格朗日函数对我们的目标函数进行了处理,生成了一个新的目标函数。通过一些条件,可以求出最优值的必要条件,这个条件就是接下来要说的KKT条件。一个最优化模型能够表示成下列标准形式:
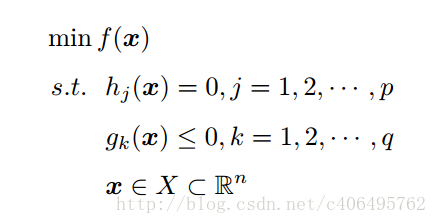
KKT条件的全称是Karush-Kuhn-Tucker条件,KKT条件是说最优值条件必须满足以下条件:
- 条件一:经过拉格朗日函数处理之后的新目标函数L(w,b,α)对α求导为零:
- 条件二:h(x) = 0;
- 条件三:α*g(x) = 0;
2.现在,让我们梳理下SMO算法的步骤:

- 步骤1:计算误差:
- 步骤2:计算上下界L和H:
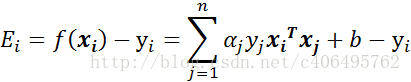
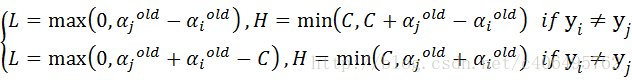
- 步骤3:计算η:
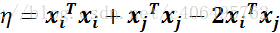
- 步骤4:更新αj:
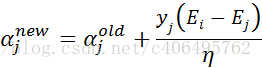
- 步骤5:根据取值范围修剪αj:

- 步骤6:更新αi:
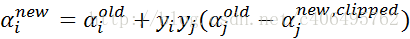
- 步骤7:更新b1和b2:
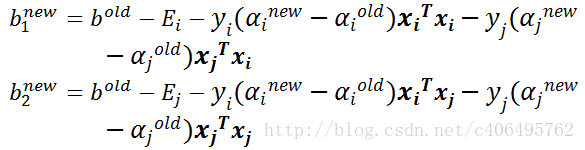
- 步骤8:根据b1和b2更新b:
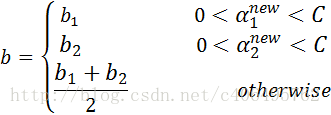
参考资料: