Java 数据结构
Java工具包提供了强大的数据结构。在Java中的数据结构主要包括以下几种接口和类:
- 枚举(Enumeration)
- 位集合(BitSet)
- 向量(Vector)
- 栈(Stack)
- 字典(Dictionary)
- 哈希表(Hashtable)
- 属性(Properties)
以上这些类是传统遗留的,在Java2中引入了一种新的框架-集合框架(Collection)
枚举(Enumeration)
枚举(Enumeration)接口虽然它本身不属于数据结构,但它在其他数据结构的范畴里应用很广。 枚举(The Enumeration)接口定义了一种从数据结构中取回连续元素的方式。
例如,枚举定义了一个叫nextElement 的方法,该方法用来得到一个包含多元素的数据结构的下一个元素。
Java Enumeration接口
Enumeration接口中定义了一些方法,通过这些方法可以枚举(一次获得一个)对象集合中的元素。
这种传统接口已被迭代器取代,虽然Enumeration 还未被遗弃,但在现代代码中已经被很少使用了。尽管如此,它还是使用在诸如Vector和Properties这些传统类所定义的方法中,除此之外,还用在一些API类,并且在应用程序中也广泛被使用。 下表总结了一些Enumeration声明的方法:
| 序号 |
方法描述 |
| 1 |
boolean hasMoreElements( ) 测试此枚举是否包含更多的元素。 |
| 2 |
Object nextElement( ) 如果此枚举对象至少还有一个可提供的元素,则返回此枚举的下一个元素。 |
位集合(BitSet)
位集合类实现了一组可以单独设置和清除的位或标志。
该类在处理一组布尔值的时候非常有用,你只需要给每个值赋值一"位",然后对位进行适当的设置或清除,就可以对布尔值进行操作了。
向量(Vector)
向量(Vector)类和传统数组非常相似,但是Vector的大小能根据需要动态的变化。
和数组一样,Vector对象的元素也能通过索引访问。
使用Vector类最主要的好处就是在创建对象的时候不必给对象指定大小,它的大小会根据需要动态的变化。
关于该类的更多信息,请参见向量(Vector)
栈(Stack)
栈(Stack)实现了一个后进先出(LIFO)的数据结构。
你可以把栈理解为对象的垂直分布的栈,当你添加一个新元素时,就将新元素放在其他元素的顶部。
当你从栈中取元素的时候,就从栈顶取一个元素。换句话说,最后进栈的元素最先被取出。
Java Stack 类
栈是Vector的一个子类,它实现了一个标准的后进先出的栈。
堆栈只定义了默认构造函数,用来创建一个空栈。 堆栈除了包括由Vector定义的所有方法,也定义了自己的一些方法。
Stack()
除了由Vector定义的所有方法,自己也定义了一些方法:
| 序号 |
方法描述 |
| 1 |
boolean empty() 测试堆栈是否为空。 |
| 2 |
Object peek( ) 查看堆栈顶部的对象,但不从堆栈中移除它。 |
| 3 |
Object pop( ) 移除堆栈顶部的对象,并作为此函数的值返回该对象。 |
| 4 |
Object push(Object element) 把项压入堆栈顶部。 |
| 5 |
int search(Object element) 返回对象在堆栈中的位置,以 1 为基数。 |
字典(Dictionary)
字典(Dictionary) 类是一个抽象类,它定义了键映射到值的数据结构。
当你想要通过特定的键而不是整数索引来访问数据的时候,这时候应该使用Dictionary。
由于Dictionary类是抽象类,所以它只提供了键映射到值的数据结构,而没有提供特定的实现。
Java Dictionary 类
Dictionary 类是一个抽象类,用来存储键/值对,作用和Map类相似。
给出键和值,你就可以将值存储在Dictionary对象中。一旦该值被存储,就可以通过它的键来获取它。所以和Map一样, Dictionary 也可以作为一个键/值对列表。
Dictionary定义的抽象方法如下表所示:
| 序号 |
方法描述 |
| 1 |
Enumeration elements( ) 返回此 dictionary 中值的枚举。 |
| 2 |
Object get(Object key) 返回此 dictionary 中该键所映射到的值。 |
| 3 |
boolean isEmpty( ) 测试此 dictionary 是否不存在从键到值的映射。 |
| 4 |
Enumeration keys( ) 返回此 dictionary 中的键的枚举。 |
| 5 |
Object put(Object key, Object value) 将指定 key 映射到此 dictionary 中指定 value。 |
| 6 |
Object remove(Object key) 从此 dictionary 中移除 key (及其相应的 value)。 |
| 7 |
int size( ) 返回此 dictionary 中条目(不同键)的数量。 |
Dictionary类已经过时了。在实际开发中,你可以实现Map接口来获取键/值的存储功能。
哈希表(Hashtable)
Hashtable类提供了一种在用户定义键结构的基础上来组织数据的手段。
例如,在地址列表的哈希表中,你可以根据邮政编码作为键来存储和排序数据,而不是通过人名。
哈希表键的具体含义完全取决于哈希表的使用情景和它包含的数据。
Java Hashtable 类
Hashtable是原始的java.util的一部分, 是一个Dictionary具体的实现 。
然而,Java 2 重构的Hashtable实现了Map接口,因此,Hashtable现在集成到了集合框架中。它和HashMap类很相似,但是它支持同步。
像HashMap一样,Hashtable在哈希表中存储键/值对。当使用一个哈希表,要指定用作键的对象,以及要链接到该键的值。
然后,该键经过哈希处理,所得到的散列码被用作存储在该表中值的索引。
Hashtable定义了四个构造方法。第一个是默认构造方法:
Hashtable()
第二个构造函数创建指定大小的哈希表:
Hashtable(int size)
第三个构造方法创建了一个指定大小的哈希表,并且通过fillRatio指定填充比例。
填充比例必须介于0.0和1.0之间,它决定了哈希表在重新调整大小之前的充满程度:
Hashtable(int size,float fillRatio)
第四个构造方法创建了一个以M中元素为初始化元素的哈希表。
哈希表的容量被设置为M的两倍。
Hashtable(Map m)
Hashtable中除了从Map接口中定义的方法外,还定义了以下方法:
| 序号 |
方法描述 |
| 1 |
void clear( ) 将此哈希表清空,使其不包含任何键。 |
| 2 |
Object clone( ) 创建此哈希表的浅表副本。 |
| 3 |
boolean contains(Object value) 测试此映射表中是否存在与指定值关联的键。 |
| 4 |
boolean containsKey(Object key) 测试指定对象是否为此哈希表中的键。 |
| 5 |
boolean containsValue(Object value) 如果此 Hashtable 将一个或多个键映射到此值,则返回 true。 |
| 6 |
Enumeration elements( ) 返回此哈希表中的值的枚举。 |
| 7 |
Object get(Object key) 返回指定键所映射到的值,如果此映射不包含此键的映射,则返回 null. 更确切地讲,如果此映射包含满足 (key.equals(k)) 的从键 k 到值 v 的映射,则此方法返回 v;否则,返回 null。 |
| 8 |
boolean isEmpty( ) 测试此哈希表是否没有键映射到值。 |
| 9 |
Enumeration keys( ) 返回此哈希表中的键的枚举。 |
| 10 |
Object put(Object key, Object value) 将指定 key 映射到此哈希表中的指定 value。 |
| 11 |
void rehash( ) 增加此哈希表的容量并在内部对其进行重组,以便更有效地容纳和访问其元素。 |
| 12 |
Object remove(Object key) 从哈希表中移除该键及其相应的值。 |
| 13 |
int size( ) 返回此哈希表中的键的数量。 |
| 14 |
String toString( ) 返回此 Hashtable 对象的字符串表示形式,其形式为 ASCII 字符 ", " (逗号加空格)分隔开的、括在括号中的一组条目。 |
属性(Properties)
Properties 继承于 Hashtable.Properties 类表示了一个持久的属性集.属性列表中每个键及其对应值都是一个字符串。
Properties 类被许多Java类使用。例如,在获取环境变量时它就作为System.getProperties()方法的返回值。
以上仅做了解
Java 集合框架
早在 Java 2 中之前,Java 就提供了特设类。比如:Dictionary, Vector, Stack, 和 Properties 这些类用来存储和操作对象组。
虽然这些类都非常有用,但是它们缺少一个核心的,统一的主题。由于这个原因,使用 Vector 类的方式和使用 Properties 类的方式有着很大不同。
集合框架被设计成要满足以下几个目标。
- 该框架必须是高性能的。基本集合(动态数组,链表,树,哈希表)的实现也必须是高效的。
- 该框架允许不同类型的集合,以类似的方式工作,具有高度的互操作性。
- 对一个集合的扩展和适应必须是简单的。
为此,整个集合框架就围绕一组标准接口而设计。你可以直接使用这些接口的标准实现,诸如: LinkedList, HashSet, 和 TreeSet 等,除此之外你也可以通过这些接口实现自己的集合。
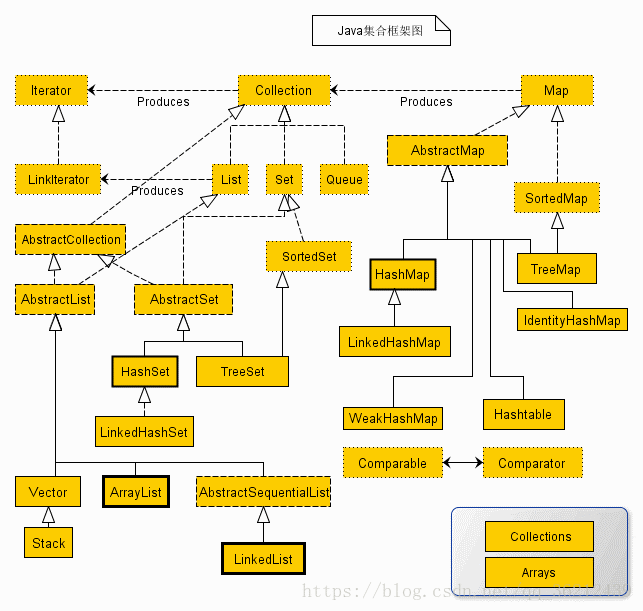
说明:对于以上的框架图有如下几点说明
1. 集合接口:6个接口(短虚线表示),表示不同集合类型,是集合框架的基础。
2. 抽象类:5个抽象类(长虚线表示),对集合接口的部分实现。可扩展为自定义集合类。
3. 实现类:8个实现类(实线表示),对接口的具体实现。
4. Collection 接口是一组允许重复的对象。
5. Set 接口继承 Collection,集合元素不重复。
6. List 接口继承 Collection,允许重复,维护元素插入顺序。
7. Map接口是键-值对象,与Collection接口没有什么关系。
集合框架是一个用来代表和操纵集合的统一架构。所有的集合框架都包含如下内容:
- 接口:是代表集合的抽象数据类型。例如 Collection、List、Set、Map 等。之所以定义多个接口,是为了以不同的方式操作集合对象
- 实现(类):是集合接口的具体实现。从本质上讲,它们是可重复使用的数据结构,例如:ArrayList、LinkedList、HashSet、HashMap。
- 算法:是实现集合接口的对象里的方法执行的一些有用的计算,例如:搜索和排序。这些算法被称为多态,那是因为相同的方法可以在相似的接口上有着不同的实现。
除了集合,该框架也定义了几个 Map 接口和类。Map 里存储的是键/值对。
集合接口
集合框架定义了一些接口。本节提供了每个接口的概述:
| 序号 |
接口描述 |
| 1 |
Collection 接口 Collection 是最基本的集合接口,一个 Collection 代表一组 Object,即 Collection 的元素, Java不提供直接继承自Collection的类,只提供继承于的子接口(如List和set)。 Collection 接口存储一组不唯一,无序的对象。 |
| 2 |
List 接口 List接口是一个有序的 Collection,使用此接口能够精确的控制每个元素插入的位置,能够通过索引(元素在List中位置,类似于数组的下标)来访问List中的元素,第一个元素的索引为 0,而且允许有相同的元素。 List 接口存储一组不唯一,有序(插入顺序)的对象。 |
| 3 |
Set Set 具有与 Collection 完全一样的接口,只是行为上不同,Set 不保存重复的元素。 Set 接口存储一组唯一,无序的对象。 |
| 4 |
SortedSet 继承于Set保存有序的集合。 |
| 5 |
Map Map 接口存储一组键值对象,提供key(键)到value(值)的映射。 |
| 6 |
Map.Entry 描述在一个Map中的一个元素(键/值对)。是一个Map的内部类。 |
| 7 |
SortedMap 继承于 Map,使 Key 保持在升序排列。 |
| 8 |
Enumeration 这是一个传统的接口和定义的方法,通过它可以枚举(一次获得一个)对象集合中的元素。这个传统接口已被迭代器取代。 |
Set和List的区别
- 1. Set 接口实例存储的是无序的,不重复的数据。List 接口实例存储的是有序的,可以重复的元素。
- 2. Set检索效率低下,删除和插入效率高,插入和删除不会引起元素位置改变 <实现类有HashSet,TreeSet>。
- 3. List和数组类似,可以动态增长,根据实际存储的数据的长度自动增长List的长度。查找元素效率高,插入删除效率低,因为会引起其他元素位置改变 <实现类有ArrayList,LinkedList,Vector> 。
集合实现类(集合类)
Java提供了一套实现了Collection接口的标准集合类。其中一些是具体类,这些类可以直接拿来使用,而另外一些是抽象类,提供了接口的部分实现。
标准集合类汇总于下表:
| 序号 |
类描述 |
| 1 |
AbstractCollection 实现了大部分的集合接口。 |
| 2 |
AbstractList 继承于AbstractCollection 并且实现了大部分List接口。 |
| 3 |
AbstractSequentialList 继承于 AbstractList ,提供了对数据元素的链式访问而不是随机访问。 |
| 4 |
LinkedList 该类实现了List接口,允许有null(空)元素。主要用于创建链表数据结构,该类没有同步方法,如果多个线程同时访问一个List,则必须自己实现访问同步,解决方法就是在创建List时候构造一个同步的List。例如: Listlist=Collections.synchronizedList(newLinkedList(...)); LinkedList 查找效率低。 |
| 5 |
ArrayList 该类也是实现了List的接口,实现了可变大小的数组,随机访问和遍历元素时,提供更好的性能。该类也是非同步的,在多线程的情况下不要使用。ArrayList 增长当前长度的50%,插入删除效率低。 |
| 6 |
AbstractSet 继承于AbstractCollection 并且实现了大部分Set接口。 |
| 7 |
HashSet 该类实现了Set接口,不允许出现重复元素,不保证集合中元素的顺序,允许包含值为null的元素,但最多只能一个。 |
| 8 |
LinkedHashSet 具有可预知迭代顺序的 Set 接口的哈希表和链接列表实现。 |
| 9 |
TreeSet 该类实现了Set接口,可以实现排序等功能。 |
| 10 |
AbstractMap 实现了大部分的Map接口。 |
| 11 |
HashMap HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。 该类实现了Map接口,根据键的HashCode值存储数据,具有很快的访问速度,最多允许一条记录的键为null,不支持线程同步。 |
| 12 |
TreeMap 继承了AbstractMap,并且使用一颗树。 |
| 13 |
WeakHashMap 继承AbstractMap类,使用弱密钥的哈希表。 |
| 14 |
LinkedHashMap 继承于HashMap,使用元素的自然顺序对元素进行排序. |
| 15 |
IdentityHashMap 继承AbstractMap类,比较文档时使用引用相等。 |
在前面的教程中已经讨论通过java.util包中定义的类,如下所示:
| 序号 |
类描述 |
| 1 |
Vector 该类和ArrayList非常相似,但是该类是同步的,可以用在多线程的情况,该类允许设置默认的增长长度,默认扩容方式为原来的2倍。 |
| 2 |
Stack 栈是Vector的一个子类,它实现了一个标准的后进先出的栈。 |
| 3 |
Dictionary Dictionary 类是一个抽象类,用来存储键/值对,作用和Map类相似。 |
| 4 |
Hashtable Hashtable 是 Dictionary(字典) 类的子类,位于 java.util 包中。 |
| 5 |
Properties Properties 继承于 Hashtable,表示一个持久的属性集,属性列表中每个键及其对应值都是一个字符串。 |
| 6 |
BitSet 一个Bitset类创建一种特殊类型的数组来保存位值。BitSet中数组大小会随需要增加。 |
集合算法
集合框架定义了几种算法,可用于集合和映射。这些算法被定义为集合类的静态方法。
在尝试比较不兼容的类型时,一些方法能够抛出 ClassCastException异常。当试图修改一个不可修改的集合时,抛出UnsupportedOperationException异常。
集合定义三个静态的变量:EMPTY_SET,EMPTY_LIST,EMPTY_MAP的。这些变量都不可改变。
| 序号 |
算法描述 |
| 1 |
Collection Algorithms 这里是一个列表中的所有算法实现。 |
如何使用迭代器
通常情况下,你会希望遍历一个集合中的元素。例如,显示集合中的每个元素。
一般遍历数组都是采用for循环或者增强for,这两个方法也可以用在集合框架,但是还有一种方法是采用迭代器遍历集合框架,它是一个对象,实现了Iterator 接口或ListIterator接口。
迭代器,使你能够通过循环来得到或删除集合的元素。ListIterator 继承了Iterator,以允许双向遍历列表和修改元素。
| 序号 |
迭代器方法描述 |
| 1 |
使用 Java Iterator 这里通过实例列出Iterator和listIterator接口提供的所有方法。 |
public class Test{
public static void main(String[] args) {
List<String> list=new ArrayList<String>();
list.add("Hello");
list.add("World");
list.add("HAHAHAHA");
//第一种遍历方法使用foreach遍历List
for (String str : list) { //也可以改写for(int i=0;i<list.size();i++)这种形式
System.out.println(str);
}
//第二种遍历,把链表变为数组相关的内容进行遍历
String[] strArray=new String[list.size()];
list.toArray(strArray);
for(int i=0;i<strArray.length;i++) //这里也可以改写为 foreach(String str:strArray)这种形式
{
System.out.println(strArray[i]);
}
//第三种遍历 使用迭代器进行相关遍历
Iterator<String> ite=list.iterator();
while(ite.hasNext())//判断下一个元素之后有值
{
System.out.println(ite.next());
}
}
}
public class Test{
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();
map.put("1", "value1");
map.put("2", "value2");
map.put("3", "value3");
//第一种:普遍使用,二次取值
System.out.println("通过Map.keySet遍历key和value:");
for (String key : map.keySet()) {
System.out.println("key= "+ key + " and value= " + map.get(key));
}
//第二种
System.out.println("通过Map.entrySet使用iterator遍历key和value:");
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第三种:推荐,尤其是容量大时
System.out.println("通过Map.entrySet遍历key和value");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
//第四种
System.out.println("通过Map.values()遍历所有的value,但不能遍历key");
for (String v : map.values()) {
System.out.println("value= " + v);
}
}
}
如何使用比较器
TreeSet和TreeMap的按照排序顺序来存储元素. 然而,这是通过比较器来精确定义按照什么样的排序顺序。
这个接口可以让我们以不同的方式来排序一个集合。
| 序号 |
比较器方法描述 |
| 1 |
使用 Java Comparator 这里通过实例列出Comparator接口提供的所有方法 |
总结
Java集合框架为程序员提供了预先包装的数据结构和算法来操纵他们。
集合是一个对象,可容纳其他对象的引用。集合接口声明对每一种类型的集合可以执行的操作。
集合框架的类和接口均在java.util包中。
任何对象加入集合类后,自动转变为Object类型,所以在取出的时候,需要进行强制类型转换。
源码实现
Collection接口
除了Map接口,其他集合都是Collection的子类,并且在我们的实际编程中,由于多态的原因,我们一般都会使用这个的编码方式,如:Inter i1 = new ImplementInter();(其中,Inter表示一个接口,ImplementInter表示对此接口的实现),此时i1调用的方法只能是Inter接口中的方法,无法调用ImplementInter中新增的方法(除非进行向下类型转化)。所以,很有必要了解一下Collection根接口中都有哪些方法
public interface Collection<E> extends Iterable<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
// jdk1.8添加的方法
default boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
boolean removed = false;
final Iterator<E> each = iterator();
while (each.hasNext()) {
if (filter.test(each.next())) {
each.remove();
removed = true;
}
}
return removed;
}
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
}说明:
1. 其中在jdk1.8后添加的方法对我们的分析不会产生影响,添加的方法有关键字default修饰,为缺省方法,是一个新特性。
2. 对集合而言,都会包含添加、删除、判断、清空、大小等基本操作。
Map接口
对于Map接口而言,是键值对集合,特别适用于那种情形,一个主属性,另外一个副属性(如:姓名,性别;leesf,男),添加元素时,若存在相同的键,则会用新值代替旧值。
public interface Map<K,V> {
int size();
boolean isEmpty();
boolean containsKey(Object key);
boolean containsValue(Object value);
V get(Object key);
V put(K key, V value);
V remove(Object key);
void putAll(Map<? extends K, ? extends V> m);
void clear();
Set<K> keySet();
Collection<V> values();
Set<Map.Entry<K, V>> entrySet();
interface Entry<K,V> {
K getKey();
V getValue();
V setValue(V value);
boolean equals(Object o);
int hashCode();
// jdk1.8 后添加的方法
public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K,V>> comparingByKey() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getKey().compareTo(c2.getKey());
}
public static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K,V>> comparingByValue() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getValue().compareTo(c2.getValue());
}
public static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());
}
public static <K, V> Comparator<Map.Entry<K, V>> comparingByValue(Comparator<? super V> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getValue(), c2.getValue());
}
}
boolean equals(Object o);
int hashCode();
default V getOrDefault(Object key, V defaultValue) {
V v;
return (((v = get(key)) != null) || containsKey(key))? v: defaultValue;
}
default void forEach(BiConsumer<? super K, ? super V> action) {
Objects.requireNonNull(action);
for (Map.Entry<K, V> entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
action.accept(k, v);
}
}
default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {
Objects.requireNonNull(function);
for (Map.Entry<K, V> entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
// ise thrown from function is not a cme.
v = function.apply(k, v);
try {
entry.setValue(v);
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
}
}
default V putIfAbsent(K key, V value) {
V v = get(key);
if (v == null) {
v = put(key, value);
}
return v;
}
default boolean remove(Object key, Object value) {
Object curValue = get(key);
if (!Objects.equals(curValue, value) ||
(curValue == null && !containsKey(key))) {
return false;
}
remove(key);
return true;
}
default boolean replace(K key, V oldValue, V newValue) {
Object curValue = get(key);
if (!Objects.equals(curValue, oldValue) ||
(curValue == null && !containsKey(key))) {
return false;
}
put(key, newValue);
return true;
}
default V replace(K key, V value) {
V curValue;
if (((curValue = get(key)) != null) || containsKey(key)) {
curValue = put(key, value);
}
return curValue;
}
default V computeIfAbsent(K key,
Function<? super K, ? extends V> mappingFunction) {
Objects.requireNonNull(mappingFunction);
V v;
if ((v = get(key)) == null) {
V newValue;
if ((newValue = mappingFunction.apply(key)) != null) {
put(key, newValue);
return newValue;
}
}
return v;
}
default V computeIfPresent(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
V oldValue;
if ((oldValue = get(key)) != null) {
V newValue = remappingFunction.apply(key, oldValue);
if (newValue != null) {
put(key, newValue);
return newValue;
} else {
remove(key);
return null;
}
} else {
return null;
}
}
default V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
V oldValue = get(key);
V newValue = remappingFunction.apply(key, oldValue);
if (newValue == null) {
// delete mapping
if (oldValue != null || containsKey(key)) {
// something to remove
remove(key);
return null;
} else {
// nothing to do. Leave things as they were.
return null;
}
} else {
// add or replace old mapping
put(key, newValue);
return newValue;
}
}
default V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
Objects.requireNonNull(value);
V oldValue = get(key);
V newValue = (oldValue == null) ? value :
remappingFunction.apply(oldValue, value);
if(newValue == null) {
remove(key);
} else {
put(key, newValue);
}
return newValue;
}
}说明:
1. Map接口有一个内部接口Entry,对集合中的元素定义了一组通用的操作,维护这键值对,可以对键值对进行相应的操作,通过Map接口的entrySet可以返回集合对象的视图集,方便对集合对象进行遍历等操作。
2. 对Map而言,也会包含添加、删除、判断、清空、大小等基本操作。
Comparable接口 && Comparator接口
此接口的作用是对集合中的元素进行排序,如Integer类型默认实现了Comparable<Integer>,String类型默认实现了Comprable<String>接口,Integer与String实现了这个接口有什么作用呢?就是当集合中的元素类型为Integer或者是String类型时,我们可以直接进行排序,就可以返回自然排序后的集合。
对于Comparable接口而言,只有一个方法。
public interface Comparable<T> {
public int compareTo(T o);
}我们在compareTo方法中实现我们的逻辑,就可以实现各种各样的排序。
对于Comparator接口而言,比Comparable接口类似,用作排序元素,主要的方法如下
public interface Comparator<T> {
int compare(T o1, T o2);
boolean equals(Object obj);
// jdk1.8 后的方法
default Comparator<T> reversed() {
return Collections.reverseOrder(this);
}
default Comparator<T> thenComparing(Comparator<? super T> other) {
Objects.requireNonNull(other);
return (Comparator<T> & Serializable) (c1, c2) -> {
int res = compare(c1, c2);
return (res != 0) ? res : other.compare(c1, c2);
};
}
default <U> Comparator<T> thenComparing(
Function<? super T, ? extends U> keyExtractor,
Comparator<? super U> keyComparator)
{
return thenComparing(comparing(keyExtractor, keyComparator));
}
default <U extends Comparable<? super U>> Comparator<T> thenComparing(
Function<? super T, ? extends U> keyExtractor)
{
return thenComparing(comparing(keyExtractor));
}
default Comparator<T> thenComparingInt(ToIntFunction<? super T> keyExtractor) {
return thenComparing(comparingInt(keyExtractor));
}
default Comparator<T> thenComparingLong(ToLongFunction<? super T> keyExtractor) {
return thenComparing(comparingLong(keyExtractor));
}
default Comparator<T> thenComparingDouble(ToDoubleFunction<? super T> keyExtractor) {
return thenComparing(comparingDouble(keyExtractor));
}
public static <T extends Comparable<? super T>> Comparator<T> reverseOrder() {
return Collections.reverseOrder();
}
@SuppressWarnings("unchecked")
public static <T extends Comparable<? super T>> Comparator<T> naturalOrder() {
return (Comparator<T>) Comparators.NaturalOrderComparator.INSTANCE;
}
public static <T> Comparator<T> nullsFirst(Comparator<? super T> comparator) {
return new Comparators.NullComparator<>(true, comparator);
}
public static <T> Comparator<T> nullsLast(Comparator<? super T> comparator) {
return new Comparators.NullComparator<>(false, comparator);
}
public static <T, U> Comparator<T> comparing(
Function<? super T, ? extends U> keyExtractor,
Comparator<? super U> keyComparator)
{
Objects.requireNonNull(keyExtractor);
Objects.requireNonNull(keyComparator);
return (Comparator<T> & Serializable)
(c1, c2) -> keyComparator.compare(keyExtractor.apply(c1),
keyExtractor.apply(c2));
}
public static <T, U extends Comparable<? super U>> Comparator<T> comparing(
Function<? super T, ? extends U> keyExtractor)
{
Objects.requireNonNull(keyExtractor);
return (Comparator<T> & Serializable)
(c1, c2) -> keyExtractor.apply(c1).compareTo(keyExtractor.apply(c2));
}
public static <T> Comparator<T> comparingInt(ToIntFunction<? super T> keyExtractor) {
Objects.requireNonNull(keyExtractor);
return (Comparator<T> & Serializable)
(c1, c2) -> Integer.compare(keyExtractor.applyAsInt(c1), keyExtractor.applyAsInt(c2));
}
public static <T> Comparator<T> comparingLong(ToLongFunction<? super T> keyExtractor) {
Objects.requireNonNull(keyExtractor);
return (Comparator<T> & Serializable)
(c1, c2) -> Long.compare(keyExtractor.applyAsLong(c1), keyExtractor.applyAsLong(c2));
}
public static<T> Comparator<T> comparingDouble(ToDoubleFunction<? super T> keyExtractor) {
Objects.requireNonNull(keyExtractor);
return (Comparator<T> & Serializable)
(c1, c2) -> Double.compare(keyExtractor.applyAsDouble(c1), keyExtractor.applyAsDouble(c2));
}
}工具类Collections && Arrays
Collections与Arrays工具类提供了很多操作集合的方法,具体的我们可以去查看API,总有一款你想要的。
equals && hashCode
equals方法与hashCode方法在集合中显得尤为重要,所以,在这里我们也好好的理解一下,为后边的分析打下好的基础。 在每一个覆盖了equals方法的类中,也必须覆盖hashCode方法,因为这样会才能使得基于散列的集合正常运作。
Object规范规定:
1. 在应用程序的执行期间,只要对象的equals方法的比较操作所用到的信息没有被修改,那么对这同一个对象调用多次hashCode方法都必须始终如一的返回同一个整数。在同一个应用程序的多次执行过程中,每次执行所返回的整数可以不一致。
2. 如果两个对象根据equals方法比较是相等的,那么调用者两个对象中的任意一个对象的hashCode方法都必须产生同样的整数结果。
3. 如果两个对象根据equals方法比较是不相等的,那么调用这两个对象中任意一个对象的hashCode方法,则不一定产生不同的整数结果。
相等的对象必须拥有相等的散列码。即equals相等,则hashcode相等,equals不相等,则hashcode不一定相等。一个好的hashCode函数倾向于为不相等的对象产生不相等的散列码,从而提升性能,不好的hashCode函数会让散列表退化成链表,性能急剧下降。
本文是在总结别人的文章的基础上编写的,如需原文请访问https://www.runoob.com/java/java-tutorial.html