Java中的接口主要由Collection接口和Map接口组成,Collection下主要有List、Queue、Set这三个子接口,而其中主要的实现类主要有ArrayList、LinkedList、Vector、Stack、HashSet、TreeSet。Map的实现类主要有HashMap、Hashtable、ConcurrentHashMap、TreeMap。Conllection提供了迭代器Iterator,可以使用迭代器来直接遍历,而Map没有提供,就不能直接遍历,需要通过其它方式来遍历。
ArrayList底层由一维数组组成,不是线程安全的,允许null,其中的元素是有序的,可以重复的,它的容量是可以动态增长的,初始容量为10,当容量满的时候,新的容量=原始容量*3/2。当容量不够的时候,每次增加元素,都要将原来的元素拷贝到一个新的数组当中。其有三种遍历方式,第一种就是普通for循环,第二种就是增强for循环,第三种就是使用Iterator。随机读取采用的是get(index)的方法,插入时要先判容,删除时要将数组移位。实现了Serializable接口,支持序列化。
LinkedList底层是由双向链表组成(模拟栈和队列的模式),不是线程安全的,允许null,其中的元素是有序的,可以重复的,它的容量也是动态增长的,但是没有扩容方法,加入元素是尾部自动扩容。其有三种遍历方式,第一种就是普通for循环,第二种就是增强for循环,第三种就是使用Iterator。实现了Serializable接口,支持序列化。因为是基于链表实现的,所以其的插入删除效率高,查找效率低,查找会遍历整个链表。
Vector底层是由一维数组组成的(是一个矢量队列),是线程安全的,允许null,其中的元素是有序的,可以重复的,它的容量可以根据需要增大或缩小。其有三种遍历方式,第一种就是普通for循环,第二种就是增强for循环,第三种就是使用Iterator。实现了Serializable接口,支持序列化。Vector是从Java1.0版本开始的,从1.2开始实现了List接口,与ArrayList大同小异,主要差别就是线程安全上的差别。
Stack底层是由一维数组组成的(模拟栈的模式),继承了Vector,因此是线程安全的,拥有着Vector的属性和功能,其中的元素是有序的,可以重复的。特性是FILO(先进后出)
HashSet是Set子接口的实现类,底层数据结构是Hash表(Hash数组),不是线程安全的,允许null,是无序的,无序指的是存入顺序与取出顺序不一致,不是指随机,不允许重复,因为不允许重复,因此只能有一个null值。添加元素的时候,会先调用元素的hashCode方法得到元素的哈希值,然后通过哈希值经过移位的算法,来算出元素的存储位置,这时候有两种情况,1:如果该位置没有元素,则直接将其存上;2:如果该位置有元素,则调用equals方法进行比较,如果返回true,则不允许添加,如果返回false,则可以添加,而这个可以添加,待会讲了HashMap就能知道是怎么添加的了。HashSet底层实际上有一个由HashMap创建的map变量,HashSet的操作函数,实际上是通过HashMap来实现的,将元素存放到HashSet中,实际上是将元素作为key值存放到HashMap中。如果添加一个已经存在的值,底层会直接不允许添加,因此新值是不会覆盖旧值的。其的遍历方式有两种,第一种是增强for循环(foreach),第二种是使用迭代器(Iterator)。实现了Serializable接口,支持序列化。应用的场景一般就是单个元素的去重。
ArrayList vs LinkedList:插入时LinkedList快,添加到最后一个元素,差不多一样快;删除中间元素,LinkedList快,删除最后一个元素,差不多一样快;查询是ArrayList快。实际工作中,查询的次数其实很多,因此使用ArrayList更频繁。如果使用到栈和队列模式,就使用LinkedList。
ArrayList vs Vector:主要区别就是线程安全的区别。
HashMap是Map的实现类,底层是Hash表,不是线程安全的,允许null,是无序的,指的是存入顺序与取出顺序不一致,不是随机的。存放的数据以键值对的方式,即key,value,一个key值对应一个value值,key值不能重复,但是value值可以重复。其的遍历方式有两种,一种(keySet())是将映射里面的key值取出来,存放在set集合里面,然后通过遍历set集合取出key值,再在遍历set里面通过取出的key值来获得value值。第二种(entrySet())是把集合中所有的映射关系(entry)抽取出来,存放在set集合里面,然后通过遍历Entry,来取得Entry里面的key和value值来达到遍历的作用。
//遍历一:把map里所有的key抽取出,存放在set集合里
Set<String> keySet = map.keySet();
for (String key : keySet) {
Integer value = map.get(key);
System.out.println(key + " -- " + value);
}
//遍历二:把map集合中所有的映射关系(entry)抽取出,存放在set集合里
Set<Entry<String, Integer>> entrySet = map.entrySet();
for (Entry<String, Integer> entry : entrySet) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key + " -- " + value);
}现在来说说HashMap中添加元素,当添加一个元素的时候,首先会将key值取出来,然后调用hashCode计算key的哈希值。再经过移位的算法,然后根据哈希值来确认value存放的位置,这里有两种情况,1:如果该位置没有存放,那就直接存放上去;2:如果该位置已经存放了value,那就用equals进行比较,如果equals返回的是true,那么新的value值就会覆盖掉旧的value值,如果equals返回的是false,那么就会在这个位置上建立一个单链表,新的value值放在头部,即数组内,旧的value就会被挤出数组,然后通过单链表进行连接。下面通过图片来讲解一下:
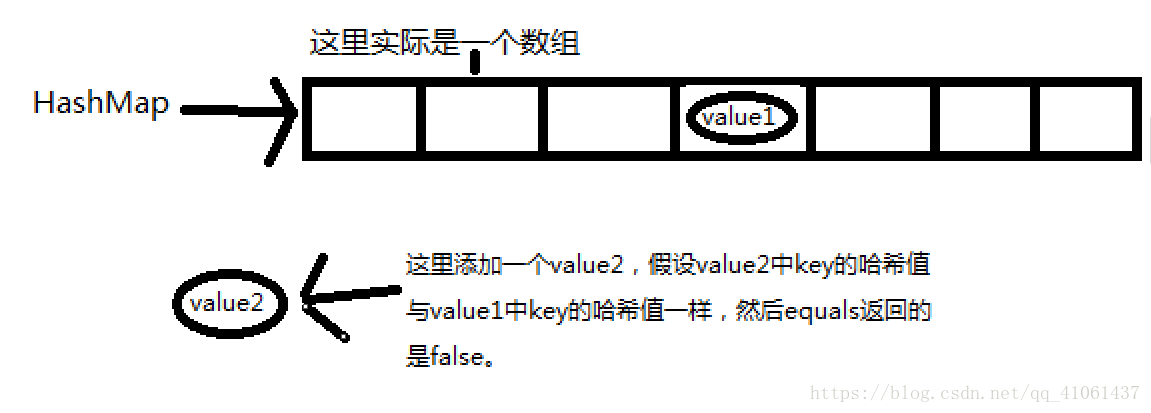
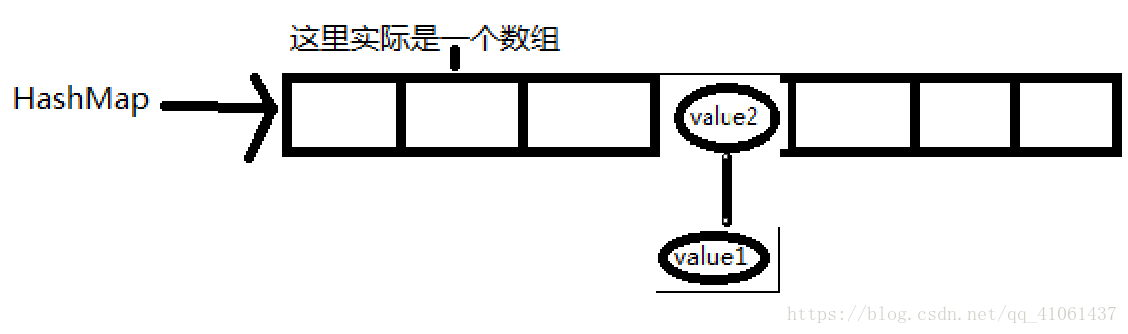
这两张图就能说明其的添加方式了,当然,只是说明的哈希值一样,equals返回false的情况,但通过这样,其余情况就很好理解了。有些人可能会有疑问,如果要获取value1的时候怎么办?岂不是通过key获取到的是value2?不是的,如果是传入value1的key,也是首先计算哈希值,然后我们就定位到了此哈希值在数组的下标的位置,也就是图中链表那个位置。那怎么区分是要获取value1还是value2呢?当然是通过equals,此链表中,只有value1的equals与传入的key是一样的,所以能取到value1的。我在学习的时候就遇到这样的困惑,就是搞不懂HashMap的底层结构,后来看了源码才明白,实际就是数组跟单链表的组合,你可以想象一个数组每个存储单元下方还拖着单链表,这样应该很容易就能理解了。这下我们也能理解HashSet怎么添加的了,如果哈希值相同,调用equals方法比较,equals返回false,添加的话,就是通过单链表连接添加的。
Hashtable和ConcurrentHashMap用法原理跟HashMap一样,我们只来讲一下三者的区别:
①null:
HashMap能存放null值,但是Hashtable和ConcurrentHashMap不能存放null值。
②线程安全:
HashMap线程不安全,Hashtable和ConcurrentHashMap是线程安全的,但是Hashtable是直接在方法上加锁,效率低;ConcurrentHashMap是在存储过程中加锁,分段式加锁,效率高。
TreeSet是Set的实现类,底层是二叉树,其实是由TreeMap来实现其的功能,只是将TreeSet的值作为TreeMap的key值,value值是一个指定的占位符,不是线程安全的,TreeSet是不支持null值的,不允许有重复值,一般来说是不支持null值,和重复值的,为什么一般来说,待会讲解TreeMap时再仔细说一说。其实TreeSet和TreeMap主要就是用来实现自然排序和自定义排序的,所谓自然排序指的就是没有一些附加条件进行排序,添加到TreeSet中排序的是可以排序的元素,实现步骤为:①:定义一个类,实现Comparable接口;②:重写Comparable接口中的compareTo()方法;③:在conpareTo()中按指定属性进行排序。而自定义排序(有些成为定制排序,比较器排序),就是按照自己定义的一些要求来进行排序,实现步骤为:①:实现Comparator接口;②:复写compare方法,判断对象是否是特定类的一个实例;③:在创建TreeSet集合对象时,提供一个Comparator对象。针对于自定义排序,很多都是将二三步合在一起,直接创建一个匿名内部类来达到同样的效果。对于遍历的话,有两种方式,一种是通过增强for循环(foreacn),另外一种是通过迭代器(Iterator)。其实底层就是一个二叉树,当对其遍历的时候,可以理解为二叉树的中序遍历。而对于添加值这一块的操作,其实也可以按照二叉树的插入值来理解,先有一个根节点,在插入其它值时,与这个根节点进行比较,小的作为左子树,大的作为右子树。实现了Serializable接口,支持序列化。
TreeMap是Map的实现类,底层是红黑树,其实我觉得可以直接理解为一种特殊的二叉排序树,而关于红黑树自己的定义,这里不做分析。不是线程安全的,在将TreeSet的时候,我们说了一般情况不允许重复和不允许null值,现在我们来讲一下不一般的情况。我们知道,其实TreeSet和TreeMap需要使用比较器来进行排序,而比较器在进行比较的时候,会返回值,当新值等于、小于、大于的时候,分别会返回0、负整数、正整数,如果我们重写比较器,让其在返回0的那里强制让其返回非0整数,那么,就可以实现添加重复值了,但是这里要注意一个问题,如果我们将传入的比较器强行修改了后,我们在取值的时候,是会get到null值的,这是为什么呢?就要从我们传入的比较器入手了,因为我们强行让相等的返回非0的值,当我们在拿着key去get的时候,底层会拿着key使用我们传入的比较器去比较,只有当等于0的时候,才会返回给我们该key对应的值,而由于我们强制返回了,所以,是找不到0的,因此,这样一来,我们就会get到null值。如果在TreeMap中的value放入null值是没有问题的,我们可以通过get去获取到null值,但是如果放入null键呢?放入null键的话,会报空指针异常。首先应该明白String类是实现了Comparable接口的,所以我们如果不传入比较器的话,put方法会调用String的compareTo()方法,所以会报空指针异常,我们可以通过传入比价器的方法去实现传入null键,但是这个时候没法使用get去获得null键对应的值,原因跟上面传入重复值一样。但是有一点要明白,如果我们允许传入重复值和null值的话,这样做的意义不大,这里讨论传入重复值和null值只是为了对其进一步的理解而已。遍历的话,同Map的遍历,只有两种遍历方式。实现了Serializable接口,支持序列化。