Hyperparameter Sweep面临的问题
在进行Hyperparameter Sweep的时候,我们需要根据许多不同的超参数组合进行不同的训练,为同一模型进行多次训练需要消耗大量计算资源或者耗费大量时间。
- 如果根据不同的超参数并行进行训练,这需要大量计算资源。
- 如果在固定计算资源上顺序进行所有不同超参数组合对应的训练,这需要花费大量时间完成所有组合对应的训练。
因此在落地时中,大多数人通过非常有限的几次手动微调他们的超参数就挑选一个相对最优的组合。
Kubernetes+Helm是利器
通过Kubernetes与Helm,您可以非常轻松地探索非常大的超参数空间,同时最大化集群的利用率,从而优化成本。
Helm使我们能够将应用程序打包到chart中并轻松地对其进行参数化。在Hyperparameter Sweep时,我们可以利用Helm chart values的配置,在template中生成对应的TFJobs进行训练部署,同时chart中还可以部署一个TensorBoard实例来监控所有这些TFJobs,这样我们就可以快速比较我们所有的超参数组合训练的结果,对那些训练效果不好的超参数组合,我们可以尽早删除对应的训练任务,这无疑会大幅的节省集群的计算资源,从而降低成本。
利用Kubernetes+Helm进行Hyperparameter Sweep Demo
Helm Chart
我们将通过Azure/kubeflow-labs/hyperparam-sweep中的例子进行Demo。
首先通过以下Dockerfile制作训练的镜像:
FROM tensorflow/tensorflow:1.7.0-gpu
COPY requirements.txt /app/requirements.txt
WORKDIR /app
RUN mkdir ./output
RUN mkdir ./logs
RUN mkdir ./checkpoints RUN pip install -r requirements.txt COPY ./* /app/ ENTRYPOINT [ "python", "/app/main.py" ] 其中main.py训练脚本内容如下:
import click
import tensorflow as tf
import numpy as np from skimage.data import astronaut from scipy.misc import imresize, imsave, imread img = imread('./starry.jpg') img = imresize(img, (100, 100)) save_dir = 'output' epochs = 2000 def linear_layer(X, layer_size, layer_name): with tf.variable_scope(layer_name): W = tf.Variable(tf.random_uniform([X.get_shape().as_list()[1], layer_size], dtype=tf.float32), name='W') b = tf.Variable(tf.zeros([layer_size]), name='b') return tf.nn.relu(tf.matmul(X, W) + b) @click.command() @click.option("--learning-rate", default=0.01) @click.option("--hidden-layers", default=7) @click.option("--logdir") def main(learning_rate, hidden_layers, logdir='./logs/1'): X = tf.placeholder(dtype=tf.float32, shape=(None, 2), name='X') y = tf.placeholder(dtype=tf.float32, shape=(None, 3), name='y') current_input = X for layer_id in range(hidden_layers): h = linear_layer(current_input, 20, 'layer{}'.format(layer_id)) current_input = h y_pred = linear_layer(current_input, 3, 'output') #loss will be distance between predicted and true RGB loss = tf.reduce_mean(tf.reduce_sum(tf.squared_difference(y, y_pred), 1)) tf.summary.scalar('loss', loss) train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss) merged_summary_op = tf.summary.merge_all() res_img = tf.cast(tf.clip_by_value(tf.reshape(y_pred, (1,) + img.shape), 0, 255), tf.uint8) img_summary = tf.summary.image('out', res_img, max_outputs=1) xs, ys = get_data(img) with tf.Session() as sess: tf.global_variables_initializer().run() train_writer = tf.summary.FileWriter(logdir + '/train', sess.graph) test_writer = tf.summary.FileWriter(logdir + '/test') batch_size = 50 for i in range(epochs): # Get a random sampling of the dataset idxs = np.random.permutation(range(len(xs))) # The number of batches we have to iterate over n_batches = len(idxs) // batch_size # Now iterate over our stochastic minibatches: for batch_i in range(n_batches): batch_idxs = idxs[batch_i * batch_size: (batch_i + 1) * batch_size] sess.run([train_op, loss, merged_summary_op], feed_dict={X: xs[batch_idxs], y: ys[batch_idxs]}) if batch_i % 100 == 0: c, summary = sess.run([loss, merged_summary_op], feed_dict={X: xs[batch_idxs], y: ys[batch_idxs]}) train_writer.add_summary(summary, (i * n_batches * batch_size) + batch_i) print("epoch {}, (l2) loss {}".format(i, c)) if i % 10 == 0: img_summary_res = sess.run(img_summary, feed_dict={X: xs, y: ys}) test_writer.add_summary(img_summary_res, i * n_batches * batch_size) def get_data(img): xs = [] ys = [] for row_i in range(img.shape[0]): for col_i in range(img.shape[1]): xs.append([row_i, col_i]) ys.append(img[row_i, col_i]) xs = (xs - np.mean(xs)) / np.std(xs) return xs, np.array(ys) if __name__ == "__main__": main() - docker build制作镜像时,会将根目录下的starry.jpg图片打包进去供main.py读取。
- main.py使用基于Andrej Karpathy's Image painting demo的模型,这个模型的目标是绘制一个尽可能接近原作的新图片,文森特梵高的“星夜”。
在Helm chart values.yaml中配置如下:
image:ritazh / tf-paint:gpu
useGPU:true
hyperParamValues:
learningRate:
- 0.001
- 0.01
- 0.1
hiddenLayers:
- 5
- 6
- 7
- image: 配置训练任务对应的docker image,就是前面您制作的镜像。
- useGPU: bool值,默认true表示将使用gpu进行训练,如果是false,则需要您制作镜像时使用
tensorflow/tensorflow:1.7.0base image。 - hyperParamValues: 超参数们的配置,在这里我们只配置了
learningRate,hiddenLayers两个超参数。
Helm chart中主要是TFJob对应的定义、Tensorboard的Deployment及其Service的定义:
# First we copy the values of values.yaml in variable to make it easier to access them
{{- $lrlist := .Values.hyperParamValues.learningRate -}}
{{- $nblayerslist := .Values.hyperParamValues.hiddenLayers -}}
{{- $image := .Values.image -}}
{{- $useGPU := .Values.useGPU -}} {{- $chartname := .Chart.Name -}} {{- $chartversion := .Chart.Version -}} # Then we loop over every value of $lrlist (learning rate) and $nblayerslist (hidden layer depth) # This will result in create 1 TFJob for every pair of learning rate and hidden layer depth {{- range $i, $lr := $lrlist }} {{- range $j, $nblayers := $nblayerslist }} apiVersion: kubeflow.org/v1alpha1 kind: TFJob # Each one of our trainings will be a separate TFJob metadata: name: module8-tf-paint-{{ $i }}-{{ $j }} # We give a unique name to each training labels: chart: "{{ $chartname }}-{{ $chartversion | replace "+" "_" }}" spec: replicaSpecs: - template: spec: restartPolicy: OnFailure containers: - name: tensorflow image: {{ $image }} env: - name: LC_ALL value: C.UTF-8 args: # Here we pass a unique learning rate and hidden layer count to each instance. # We also put the values between quotes to avoid potential formatting issues - --learning-rate - {{ $lr | quote }} - --hidden-layers - {{ $nblayers | quote }} - --logdir - /tmp/tensorflow/tf-paint-lr{{ $lr }}-d-{{ $nblayers }} # We save the summaries in a different directory {{ if $useGPU }} # We only want to request GPUs if we asked for it in values.yaml with useGPU resources: limits: nvidia.com/gpu: 1 {{ end }} volumeMounts: - mountPath: /tmp/tensorflow subPath: module8-tf-paint # As usual we want to save everything in a separate subdirectory name: azurefile volumes: - name: azurefile persistentVolumeClaim: claimName: azurefile --- {{- end }} {{- end }} # We only want one instance running for all our jobs, and not 1 per job. apiVersion: v1 kind: Service metadata: labels: app: tensorboard name: module8-tensorboard spec: ports: - port: 80 targetPort: 6006 selector: app: tensorboard type: LoadBalancer --- apiVersion: extensions/v1beta1 kind: Deployment metadata: labels: app: tensorboard name: module8-tensorboard spec: template: metadata: labels: app: tensorboard spec: volumes: - name: azurefile persistentVolumeClaim: claimName: azurefile containers: - name: tensorboard command: - /usr/local/bin/tensorboard - --logdir=/tmp/tensorflow - --host=0.0.0.0 image: tensorflow/tensorflow ports: - containerPort: 6006 volumeMounts: - mountPath: /tmp/tensorflow subPath: module8-tf-paint name: azurefile 按照上面的超参数配置,在helm install时,9个超参数组合会产生9个TFJob,对应我们指定的3个learningRate和3个hiddenLayers所有组合。
main.py训练脚本有3个参数:

| argument | description | default value |
|---|---|---|
| --learning-rate | Learning rate value | 0.001 |
| --hidden-layers | Number of hidden layers in our network. | 4 |
| --log-dir | Path to save TensorFlow's summaries | None |
Helm Install
执行helm install命令即可轻松完成所有不同超参数组合对应的训练部署,这里我们只使用了单机训练,您也可以使用分布式训练。
helm install .
NAME: telling-buffalo
LAST DEPLOYED:
NAMESPACE: tfworkflow
STATUS: DEPLOYED
RESOURCES:
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE module8-tensorboard LoadBalancer 10.0.142.217 <pending> 80:30896/TCP 1s ==> v1beta1/Deployment NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE module8-tensorboard 1 1 1 0 1s ==> v1alpha1/TFJob NAME AGE module8-tf-paint-0-0 1s module8-tf-paint-1-0 1s module8-tf-paint-1-1 1s module8-tf-paint-2-1 1s module8-tf-paint-2-2 1s module8-tf-paint-0-1 1s module8-tf-paint-0-2 1s module8-tf-paint-1-2 1s module8-tf-paint-2-0 0s ==> v1/Pod(related) NAME READY STATUS RESTARTS AGE module8-tensorboard-7ccb598cdd-6vg7h 0/1 ContainerCreating 0 1s 部署chart后,查看已创建的Pods,您应该看到对应的一些列Pods,以及监视所有窗格的单个TensorBoard实例:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
module8-tensorboard-7ccb598cdd-6vg7h 1/1 Running 0 16s
module8-tf-paint-0-0-master-juc5-0-hw5cm 0/1 Pending 0 4s
module8-tf-paint-0-1-master-pu49-0-jp06r 1/1 Running 0 14s
module8-tf-paint-0-2-master-awhs-0-gfra0 0/1 Pending 0 6s
module8-tf-paint-1-0-master-5tfm-0-dhhhv 1/1 Running 0 16s
module8-tf-paint-1-1-master-be91-0-zw4gk 1/1 Running 0 16s
module8-tf-paint-1-2-master-r2nd-0-zhws1 0/1 Pending 0 7s
module8-tf-paint-2-0-master-7w37-0-ff0w9 0/1 Pending 0 13s
module8-tf-paint-2-1-master-260j-0-l4o7r 0/1 Pending 0 10s
module8-tf-paint-2-2-master-jtjb-0-5l84q 0/1 Pending 0 9s
注意:由于群集中可用的GPU资源,某些pod正在等待处理。如果群集中有3个GPU,则在给定时间最多只能有3个TFJob(每个TFJob请求了一块gpu)并行训练。
通过TensorBoard尽早识别最优的超参数组合
TensorBoard Service也会在Helm install执行时自动完成创建,您可以使用该Service的External-IP连接到TensorBoard。
$ kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
module8-tensorboard LoadBalancer 10.0.142.217 <PUBLIC IP> 80:30896/TCP 5m
通过浏览器访问TensorBoard的Public IP地址,你会看到类似如下的页面(TensorBoard需要一点时间才能显示图像。)
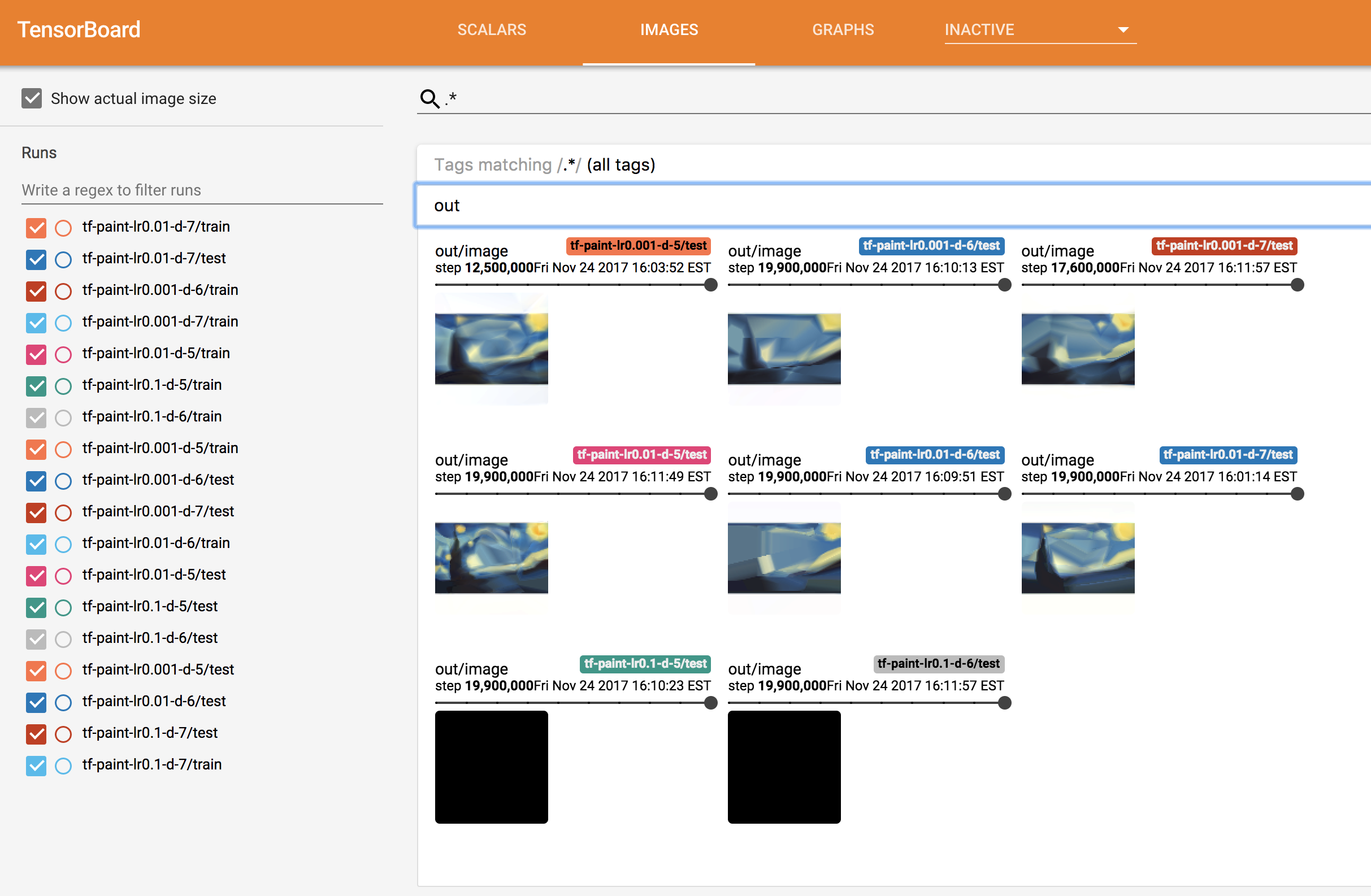
在这里我们可以看到一些超参数对应的模型比其他模型表现更好。例如,所有learning rate为0.1对应的模型全部产生全黑图像,模型效果极差。几分钟后,我们可以看到两个表现最好的超参数组合是:
- hidden layers = 5,learning rate = 0.01
- hidden layers = 7,learning rate = 0.001
此时,我们可以立刻Kill掉其他表现差的模型训练,释放宝贵的gpu资源。
总结
通过本文简单利用Helm进行Hyperparameter Sweep的使用方法介绍,希望能帮助大家更高效的进行超参数调优。
参考