在神经网络中,有许多超参数需要设置,比如学习率,网络层数,神经元节点数
所谓超参数,就是不需要训练的参数,需要人为设定的参数。
这些超参数对模型的训练和性能都有很大影响,非常重要,那么这些超参数该怎么设定呢?
一般我们可以根据经验来设定,但是经验毕竟有限,而且也不科学。
验证数据
在模型训练时,我们通常会有训练数据和测试数据,训练数据用来训练,测试数据用来测试,但是这两个数据都不能用来调参,为什么呢?因为如果用训练数据来调参,很容易过拟合,如果用测试数据来调参,模型的泛华能力很难保障。
所以只能用验证数据来调参。测试数据是用来评估模型的,而且最好只用一次。
在选取验证数据时要打乱数据,原因如下:
1. 使得类别分布均匀,避免选取数据中只有某些类别
2. 如果不打乱,比如样本按类别顺序0-10排列,那么刚开始模型很快找到类别0的权重,但是到类别1时,又成了类别1的权重,最后成了类别10的权重,当然没有这么极端,但是模型肯定会存在“偏向”
超参数的优化
超参数优化总体思路是重复探索,并且不断缩小探索范围。
具体怎么理解呢?
就是刚开始设置一个较大的范围,然后随机选择某个值,训练并评估模型的效果,然后重复该操作,从多个结果中选择效果好的对应的参数区间,这就缩小了探索范围,
然后重复上述操作,再次缩小范围,直到取到合适范围。(研究表明随机取值效果比有规律取值效果好)
此过程注意以下几点:
1. 初始范围设定以10的阶乘为尺度,如 10-3到104
2. 每次训练迭代次数不能太大,因为神经网络训练本来就比较慢,在优化过程中需要多次训练,如果每次训练迭代次数很多,总耗时会非常长,
而且我们只是为了选参数,如果参数合适,会很快收敛,只要收敛效果就会不错,没必要非得收敛到最小值
总结一下步骤
1. 设定初始范围,每个参数一个范围
2. 随机选择参数值
3. 训练模型验证精度
4. 重复2 3步,根据精度来缩小取值范围
5. 返回步骤1
图示如下
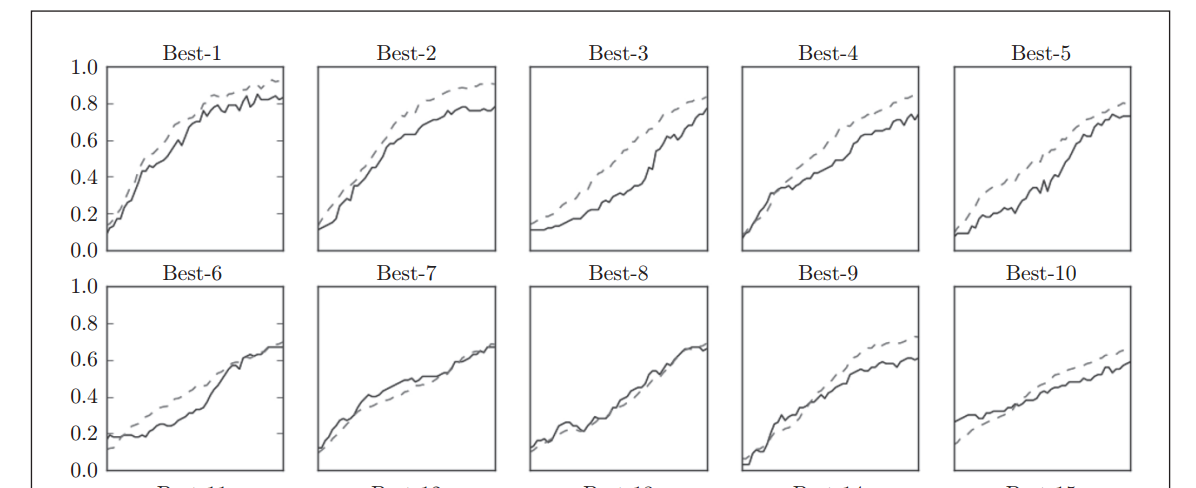
上图是多次试验后,按精度高低顺序画出的效果图,可以看到前5次准确率在0.8以上,从第6次开始,精度跌倒0.6以下
前5个图对于的参数如图
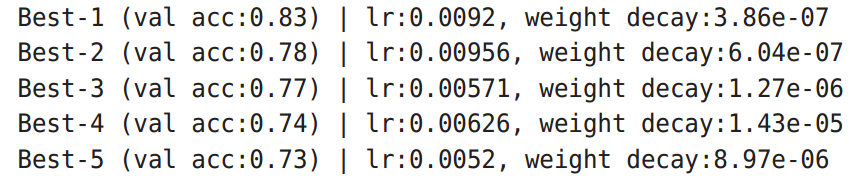
这个结果可以看出,学习率在 0.001 到0.01之间,等等
总结
其实无论是机器学习还是深度学习,调参思路都差不多,在实际项目中,要结合实际情况灵活运用。