HA Flume流程图
搭载详细流程
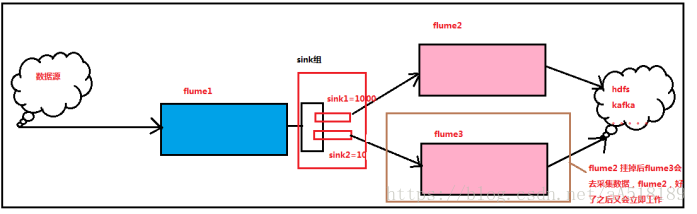
在 flume1的sink中设置一个组group,这个组里面有两个sink,sink1和sink2.其中sink1负责把数据下沉到flume2。
Sink2负责把数据下沉到flume3。并且设置优先级,比如 设置sink1的优先级为1000,设置sink2的优先级为10,谁的优先级大,谁负责采集数据。最后设置一个乘法因子,设置为1000,当优先级高的机器宕机时,优先级要减去乘法因子,比如本案例,sink1宕机后,优先级变成 1000-1000=0,此时sink2的优先级高,则又sink2负责把数据下沉到flume3,当flume2恢复好时,又会立即工作。
设置组的处理类型为 failover,可选的还有load_balance和default,也就是k1、k2在使用过程中只有一个可用,且k1优先级高于k2,如果k1宕机之后恢复之后,可以使用的仍然是k1,而不是k2。
(说明,惩罚因子和优先级的设置是随便,只要能区分说的优先级高就行)。
采集方案
Flume2和flume3 的采集方案:这两个是一样的,都是采集flume1的数据,然后下沉到hdfs
a1.sources.r1.bind = wangzhihua3
a1.sources.r1.interceptors.i1.value = wangzhihua3
这两个必须一样
a1.sources = r1 a1.channels = c1 a1.sinks = k1
#set channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
# other node,nna to nns a1.sources.r1.type = avro a1.sources.r1.bind = wangzhihua3 a1.sources.r1.port = 52020 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = static a1.sources.r1.interceptors.i1.key = Collector a1.sources.r1.interceptors.i1.value = wangzhihua3 a1.sources.r1.channels = c1
#set sink to hdfs a1.sinks.k1.type=hdfs a1.sinks.k1.hdfs.path=/home/hdfs/flume/logdfs a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.writeFormat=TEXT a1.sinks.k1.hdfs.rollInterval=10 a1.sinks.k1.channel=c1 a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d |
Flume1 的采集方案:设置一个sink组:g1,组内有两个sink1和sink2.分别下沉到flume2,flume3
#agent的名字 a1.channels = c1 a1.sources = r1 a1.sinks = k1 k2
#设置sink组 a1.sinkgroups = g1
#设置 channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /root/test.log a1.sources.r1.interceptors = i1 i2 a1.sources.r1.interceptors.i1.type = static a1.sources.r1.interceptors.i1.key = Type a1.sources.r1.interceptors.i1.value = LOGIN a1.sources.r1.interceptors.i2.type = timestamp
# 设置下沉组件 sink1,将端口绑定到wangzhihua2上的52020 a1.sinks.k1.channel = c1 a1.sinks.k1.type = avro a1.sinks.k1.hostname = wangzhihua2 a1.sinks.k1.port = 52020 # 设置下沉组件 sink2 ,将端口绑定到wangzhihua3上的52020 a1.sinks.k2.channel = c1 a1.sinks.k2.type = avro a1.sinks.k2.hostname =wangzhihua3 a1.sinks.k2.port = 52020
#设置 sink group a1.sinkgroups.g1.sinks = k1 k2
#设置组的处理类型为 failover,可选的还有load_balance和default #k1、k2在使用过程中只有一个可用,且k1优先级高于k2,如果k1宕机之后恢复之后 #可以使用的仍然是k1,而不是k2 a1.sinkgroups.g1.processor.type = failover a1.sinkgroups.g1.processor.priority.k1 = 10 a1.sinkgroups.g1.processor.priority.k2 = 1 a1.sinkgroups.g1.processor.maxpenalty = 10000 |