JDK8开始定义了很多新的操作List Set Map的接口,方便集合的运算。
1. Stream 接口
1.1 原理
java.util.Stream 表示能应用在一组元素上,一次执行的操作序列。//及其难懂
Stream 运算分为中间运算和最终运算,最终运算返回方法的计算结果值;而中间运算返回Stream,可以进行多次stream运算。
Stream 基于一组元素计算,比如 java.util.Collection的子类,List或者Set, Map不支持。
public interface Collection<E> extends Iterable<E> {
/**
* Returns a sequential {@code Stream} with this collection as its source.
*
* <p>This method should be overridden when the {@link #spliterator()}
* method cannot return a spliterator that is {@code IMMUTABLE},
* {@code CONCURRENT}, or <em>late-binding</em>. (See {@link #spliterator()}
* for details.)
*
* @implSpec
* The default implementation creates a sequential {@code Stream} from the
* collection's {@code Spliterator}.
*
* @return a sequential {@code Stream} over the elements in this collection
* @since 1.8
*/
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
/**
* Returns a possibly parallel {@code Stream} with this collection as its
* source. It is allowable for this method to return a sequential stream.
*
* <p>This method should be overridden when the {@link #spliterator()}
* method cannot return a spliterator that is {@code IMMUTABLE},
* {@code CONCURRENT}, or <em>late-binding</em>. (See {@link #spliterator()}
* for details.)
*
* @implSpec
* The default implementation creates a parallel {@code Stream} from the
* collection's {@code Spliterator}.
*
* @return a possibly parallel {@code Stream} over the elements in this
* collection
* @since 1.8
*/
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}Collection的源码可以看出支持stream运算,流式接口的核心原理是fork/join基础,基于大数据运算的算法,拆分collection,多管路分别运算,组装结果。
stream方法支持串行化运算,parallelStream方法支持并行化运算。
static class IteratorSpliterator<T> implements Spliterator<T> {
static final int BATCH_UNIT = 1 << 10; // batch array size increment
static final int MAX_BATCH = 1 << 25; // max batch array size;
private final Collection<? extends T> collection; // null OK
private Iterator<? extends T> it;
private final int characteristics;
private long est; // size estimate
private int batch; // batch size for splits
/**
* Creates a spliterator using the given given
* collection's {@link java.util.Collection#iterator()) for traversal,
* and reporting its {@link java.util.Collection#size()) as its initial
* size.
*
* @param c the collection
* @param characteristics properties of this spliterator's
* source or elements.
*/
public IteratorSpliterator(Collection<? extends T> collection, int characteristics) {
this.collection = collection;
this.it = null;
this.characteristics = (characteristics & Spliterator.CONCURRENT) == 0
? characteristics | Spliterator.SIZED | Spliterator.SUBSIZED
: characteristics;
}Spliterator的本质:分离器,按照某种字节大小分离集合
如在Windows下
Spliterator.CONCURRENT就是4096,刚好是4K,磁盘的最小单位。这里我理解也比较吃力,需要对磁盘硬件和硬件软件驱动模式有一定的了解才行。
下面看 StreamSupport.stream的本质
/**
* Creates a new sequential or parallel {@code Stream} from a
* {@code Spliterator}.
*
* <p>The spliterator is only traversed, split, or queried for estimated
* size after the terminal operation of the stream pipeline commences.
*
* <p>It is strongly recommended the spliterator report a characteristic of
* {@code IMMUTABLE} or {@code CONCURRENT}, or be
* <a href="../Spliterator.html#binding">late-binding</a>. Otherwise,
* {@link #stream(java.util.function.Supplier, int, boolean)} should be used
* to reduce the scope of potential interference with the source. See
* <a href="package-summary.html#NonInterference">Non-Interference</a> for
* more details.
*
* @param <T> the type of stream elements
* @param spliterator a {@code Spliterator} describing the stream elements
* @param parallel if {@code true} then the returned stream is a parallel
* stream; if {@code false} the returned stream is a sequential
* stream.
* @return a new sequential or parallel {@code Stream}
*/
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}/**
* Constructor for the head of a stream pipeline.
*
* @param source {@code Spliterator} describing the stream source
* @param sourceFlags the source flags for the stream source, described in
* {@link StreamOpFlag}
* @param parallel {@code true} if the pipeline is parallel
*/
AbstractPipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
this.previousStage = null;
this.sourceSpliterator = source;
this.sourceStage = this;
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;
this.parallel = parallel;
}应该是管道存储。Pipeline,也就是说stream的本质就是Pipeline。根据spliterator的方式切分集合,存储为Pipeline,便与运算。
中间态运算都是构造函数实现的,应该在别的地方有实现逻辑,源码直接追踪就是构造函数
最终态运算结果是调用方法可以直接看到核心原理。
AbstractPipeline类定义了实际的处理逻辑,如evaluate方法
/**
* Evaluate the pipeline with a terminal operation to produce a result.
*
* @param <R> the type of result
* @param terminalOp the terminal operation to be applied to the pipeline.
* @return the result
*/
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}有一下实现方式

@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
@Override
@SuppressWarnings("unchecked")
final <P_IN> void copyIntoWithCancel(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
@SuppressWarnings({"rawtypes","unchecked"})
AbstractPipeline p = AbstractPipeline.this;
while (p.depth > 0) {
p = p.previousStage;
}
wrappedSink.begin(spliterator.getExactSizeIfKnown());
p.forEachWithCancel(spliterator, wrappedSink);
wrappedSink.end();
}进一步查看本质
default void forEachRemaining(Consumer<? super T> action) {
do { } while (tryAdvance(action));
} 
@Override
final void forEachWithCancel(Spliterator<P_OUT> spliterator, Sink<P_OUT> sink) {
do { } while (!sink.cancellationRequested() && spliterator.tryAdvance(sink));
}本质是函数式接口参数的循环。
Stream运算可以串行、并行执行。
Stream的操作不会改变list原本的结构,只会在Pipeline内存存储。
1.2 forEach
使用evaluate方法,上章有介绍原理。
void forEach(Consumer<? super T> action);
@Override
public void forEach(Consumer<? super P_OUT> action) {
evaluate(ForEachOps.makeRef(action, false));
}
@FunctionalInterface
public interface Consumer<T> {
/**
* Performs this operation on the given argument.
*
* @param t the input argument
*/
void accept(T t);forEach使用函数式接口参数。forEach是一个最终操作,输出操作后没有返回值,不能执行其他操作。
List<String> list = new ArrayList<>();
list.add("d-2");
list.add("a-2");
list.add("b-1");
list.add("a-1");
list.add("b-3");
list.add("rrr");
list.add("kkk");
list.add("d-1");
list.stream().forEach(System.out::println);
list.stream().forEach((s)->System.out.println(s));1.3 Filter
/**
* Returns a stream consisting of the elements of this stream that match
* the given predicate.
*
* <p>This is an <a href="package-summary.html#StreamOps">intermediate
* operation</a>.
*
* @param predicate a <a href="package-summary.html#NonInterference">non-interfering</a>,
* <a href="package-summary.html#Statelessness">stateless</a>
* predicate to apply to each element to determine if it
* should be included
* @return the new stream
*/
Stream<T> filter(Predicate<? super T> predicate);中间态运算,运算结果为Stream。
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}看起来像流运算,需要仔细研究一下。
示例
List<String> list = new ArrayList<>();
list.add("d-2");
list.add("a-2");
list.add("b-1");
list.add("a-1");
list.add("b-3");
list.add("rrr");
list.add("kkk");
list.add("d-1");
list.stream().filter((s) -> s.startsWith("a"))
.forEach(System.out::println);
list.stream().forEach(System.out::println);Stream的操作filter(包括其他操作)不会改变list原本的结构,只会在Pipeline内存存储。
1.4 Sort
/**
* Returns a stream consisting of the elements of this stream, sorted
* according to natural order. If the elements of this stream are not
* {@code Comparable}, a {@code java.lang.ClassCastException} may be thrown
* when the terminal operation is executed.
*
* <p>For ordered streams, the sort is stable. For unordered streams, no
* stability guarantees are made.
*
* <p>This is a <a href="package-summary.html#StreamOps">stateful
* intermediate operation</a>.
*
* @return the new stream
*/
Stream<T> sorted();
/**
* Returns a stream consisting of the elements of this stream, sorted
* according to the provided {@code Comparator}.
*
* <p>For ordered streams, the sort is stable. For unordered streams, no
* stability guarantees are made.
*
* <p>This is a <a href="package-summary.html#StreamOps">stateful
* intermediate operation</a>.
*
* @param comparator a <a href="package-summary.html#NonInterference">non-interfering</a>,
* <a href="package-summary.html#Statelessness">stateless</a>
* {@code Comparator} to be used to compare stream elements
* @return the new stream
*/
Stream<T> sorted(Comparator<? super T> comparator); OfRef(AbstractPipeline<?, T, ?> upstream, Comparator<? super T> comparator) {
super(upstream, StreamShape.REFERENCE,
StreamOpFlag.IS_ORDERED | StreamOpFlag.NOT_SORTED);
this.isNaturalSort = false;
this.comparator = Objects.requireNonNull(comparator);
}
/**
* Sort using natural order of {@literal <T>} which must be
* {@code Comparable}.
*/
OfRef(AbstractPipeline<?, T, ?> upstream) {
super(upstream, StreamShape.REFERENCE,
StreamOpFlag.IS_ORDERED | StreamOpFlag.IS_SORTED);
this.isNaturalSort = true;
// Will throw CCE when we try to sort if T is not Comparable
@SuppressWarnings("unchecked")
Comparator<? super T> comp = (Comparator<? super T>) Comparator.naturalOrder();
this.comparator = comp;
}
@Override
public final Stream<P_OUT> sorted() {
return SortedOps.makeRef(this);
}
OfRef(AbstractPipeline<?, T, ?> upstream, Comparator<? super T> comparator) {
super(upstream, StreamShape.REFERENCE,
StreamOpFlag.IS_ORDERED | StreamOpFlag.NOT_SORTED);
this.isNaturalSort = false;
this.comparator = Objects.requireNonNull(comparator);
}
@Override
public final Stream<P_OUT> sorted(Comparator<? super P_OUT> comparator) {
return SortedOps.makeRef(this, comparator);
}有默认比较器Comparator.naturalOrder();
List<String> list = new ArrayList<>();
list.add("d-2");
list.add("a-2");
list.add("b-1");
list.add("a-1");
list.add("b-3");
list.add("rrr");
list.add("kkk");
list.add("d-1");
list.stream()
.sorted()
.forEach((s)->System.out.println(s));1.5 map
将集合的元素替换,比如转大小写,String转int等。
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
@Override
@SuppressWarnings("unchecked")
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
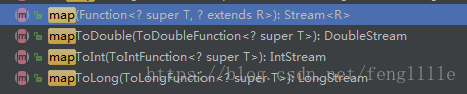
默认实现有3种,如上图
list.stream().map(String::trim)
.forEach((s)->System.out.println(s));1.6 match
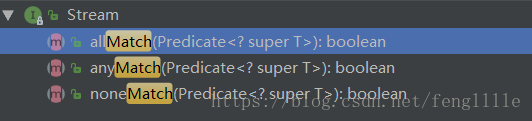
match是最终操作,返回boolean值。
源码只是,枚举类型不一样,实现逻辑一致。
@Override
public final boolean anyMatch(Predicate<? super P_OUT> predicate) {
return evaluate(MatchOps.makeRef(predicate, MatchOps.MatchKind.ANY));
}
@Override
public final boolean allMatch(Predicate<? super P_OUT> predicate) {
return evaluate(MatchOps.makeRef(predicate, MatchOps.MatchKind.ALL));
}
@Override
public final boolean noneMatch(Predicate<? super P_OUT> predicate) {
return evaluate(MatchOps.makeRef(predicate, MatchOps.MatchKind.NONE));
}示例
List<String> list = new ArrayList<>();
list.add("d-2");
list.add("a-2");
list.add("b-1");
list.add("a-1");
list.add("b-3");
list.add("c33");
list.add("bgg33");
list.add("dffff");
boolean flag = list.stream().anyMatch((s -> s.startsWith("a")));
System.out.println(flag);1.7 count
@Override
public final long count() {
return mapToLong(e -> 1L).sum();
}
@Override
public final long sum() {
// use better algorithm to compensate for intermediate overflow?
return reduce(0, Long::sum);
}
@Override
public final long reduce(long identity, LongBinaryOperator op) {
return evaluate(ReduceOps.makeLong(identity, op));
}
/**
* Constructs a {@code TerminalOp} that implements a functional reduce on
* {@code long} values.
*
* @param identity the identity for the combining function
* @param operator the combining function
* @return a {@code TerminalOp} implementing the reduction
*/
public static TerminalOp<Long, Long>
makeLong(long identity, LongBinaryOperator operator) {
Objects.requireNonNull(operator);
class ReducingSink
implements AccumulatingSink<Long, Long, ReducingSink>, Sink.OfLong {
private long state;
@Override
public void begin(long size) {
state = identity;
}
@Override
public void accept(long t) {
state = operator.applyAsLong(state, t);
}
@Override
public Long get() {
return state;
}
@Override
public void combine(ReducingSink other) {
accept(other.state);
}
}
return new ReduceOp<Long, Long, ReducingSink>(StreamShape.LONG_VALUE) {
@Override
public ReducingSink makeSink() {
return new ReducingSink();
}
};
}
源码风格跟JDK1.8之前大相径庭,偏向C语言风格。
代码上看是使用mapToLong将集合元素转成所有元素为1L的值,然后初始化0,求Long::sum静态方法求和。
调用了reduce方法计算。
示例
long count = list.stream().count();
System.out.println(count);1.8 reduce
public final Optional<P_OUT> reduce(BinaryOperator<P_OUT> accumulator) {
return evaluate(ReduceOps.makeRef(accumulator));
}返回Optional结果,上面的count计算其实就是reduce的一种运用
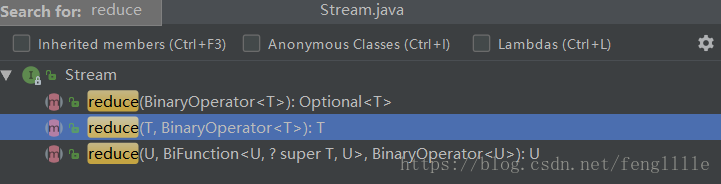
将所有值运算,得到一个值,是最终操作的结果,可以是count,sum,avg等。函数是接口如下:
@FunctionalInterface
public interface BiFunction<T, U, R> {
/**
* Applies this function to the given arguments.
*
* @param t the first function argument
* @param u the second function argument
* @return the function result
*/
R apply(T t, U u);我们实现上面的count计算,示例如下:
List<String> list = new ArrayList<>();
list.add("d-2");
list.add("a-2");
list.add("b-1");
list.add("a-1");
list.add("b-3");
list.add("c33");
list.add("bgg33");
list.add("dffff");
//OptionalLong result = list.stream().mapToLong(e->1L).reduce((s1, s2)->s1+s2);
OptionalLong result = list.stream().mapToLong(e->1L).reduce(Long::sum);
result.ifPresent(System.out::println);这样我们自己就根据count的原理实现了count运算。
2. parallelStream并行化
Stream有串行和并行,对应Stream的两个方法stream方法和parallelStream方法。
stream方法的操作是在一个线程中依次完成,而parallelStream方法则是在多个线程上同时执行。
原理很简单,大任务的时候,多个线程同时干活肯定比单个线程快;任务少的时候多线程的开销,创建销毁等比较大,可能性能还比较低。运用要根据实际情况。
/**
* Creates a new sequential or parallel {@code Stream} from a
* {@code Spliterator}.
*
* <p>The spliterator is only traversed, split, or queried for estimated
* size after the terminal operation of the stream pipeline commences.
*
* <p>It is strongly recommended the spliterator report a characteristic of
* {@code IMMUTABLE} or {@code CONCURRENT}, or be
* <a href="../Spliterator.html#binding">late-binding</a>. Otherwise,
* {@link #stream(java.util.function.Supplier, int, boolean)} should be used
* to reduce the scope of potential interference with the source. See
* <a href="package-summary.html#NonInterference">Non-Interference</a> for
* more details.
*
* @param <T> the type of stream elements
* @param spliterator a {@code Spliterator} describing the stream elements
* @param parallel if {@code true} then the returned stream is a parallel
* stream; if {@code false} the returned stream is a sequential
* stream.
* @return a new sequential or parallel {@code Stream}
*/
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}@param parallel if {@code true} then the returned stream is a parallel stream; if {@code false} the returned stream is a sequential stream.
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}这里为true,意味着多线程运算。
效率的示例,大任务量:
int max = 3000000;
UUID uuid;
List<String> list = new ArrayList<>(max);
for (int i = 0; i < max; i++) {
uuid = UUID.randomUUID();
list.add(uuid.toString());
}
System.out.println("------------------------------start------------------------");
long st = System.currentTimeMillis();
list.stream().sorted().count();
long et = System.currentTimeMillis();
System.out.println("用时:\t"+(et-st)+"\tms");
------------------------------start------------------------
用时: 3131 ms而
System.out.println("------------------------------start------------------------");
long st = System.currentTimeMillis();
list.parallelStream().sorted().count();
long et = System.currentTimeMillis();
System.out.println("用时:\t"+(et-st)+"\tms");
------------------------------start------------------------
用时: 1102 ms此demo,parallelStream并行运算仅用了1/3的时间,另外增大计算的量,差距会更明显。(List,如果我们知道容量大小,一次性初始化比扩容效率高太多,推荐在知道容量时,初始化容量)
3. map
3.1 forEach
/**
* Performs the given action for each entry in this map until all entries
* have been processed or the action throws an exception. Unless
* otherwise specified by the implementing class, actions are performed in
* the order of entry set iteration (if an iteration order is specified.)
* Exceptions thrown by the action are relayed to the caller.
*
* @implSpec
* The default implementation is equivalent to, for this {@code map}:
* <pre> {@code
* for (Map.Entry<K, V> entry : map.entrySet())
* action.accept(entry.getKey(), entry.getValue());
* }</pre>
*
* The default implementation makes no guarantees about synchronization
* or atomicity properties of this method. Any implementation providing
* atomicity guarantees must override this method and document its
* concurrency properties.
*
* @param action The action to be performed for each entry
* @throws NullPointerException if the specified action is null
* @throws ConcurrentModificationException if an entry is found to be
* removed during iteration
* @since 1.8
*/
default void forEach(BiConsumer<? super K, ? super V> action) {
Objects.requireNonNull(action);
for (Map.Entry<K, V> entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch(IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
action.accept(k, v);
}
}JDK 1.8自带了forEach方法,Map接口的default方法。
根据代码,使用函数式接口处理结果,使用entrySet遍历。
示例
Map<Integer, String> map = new HashMap<>();
for (int i = 1; i <= 12; i++) {
map.putIfAbsent(i, "val" + i);
}
map.forEach((s1,s2)->
System.out.println("key:"+s1+"\tvalue:"+s2)
);3.2 putIfAbsent
这里使用putIfAbsent源码如下:
/**
* @since 1.8
*/
default V putIfAbsent(K key, V value) {
V v = get(key);
if (v == null) {
v = put(key, value);
}
return v;
}putIfAbsent根据value == null来设定值。
3.3 computeIfAbsent
/** @since 1.8
*/
default V computeIfAbsent(K key,
Function<? super K, ? extends V> mappingFunction) {
Objects.requireNonNull(mappingFunction);
V v;
if ((v = get(key)) == null) {
V newValue;
if ((newValue = mappingFunction.apply(key)) != null) {
put(key, newValue);
return newValue;
}
}key的value值==null,新的value值不为null,设置key新的value值。
还有一种通过旧value计算新value,如下:
/** @since 1.8
*/
default V computeIfPresent(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
V oldValue;
if ((oldValue = get(key)) != null) {
//这里是函数接口的本质
V newValue = remappingFunction.apply(key, oldValue);
if (newValue != null) {
put(key, newValue);
return newValue;
} else {
remove(key);
return null;
}
} else {
return null;
}
}key的旧值不为null,新value值不为null则put,否则移除key。
3.4 remove
/** @since 1.8
*/
default boolean remove(Object key, Object value) {
Object curValue = get(key);
if (!Objects.equals(curValue, value) ||
(curValue == null && !containsKey(key))) {
return false;
}
remove(key);
return true;
}多了一步校验,没其他区别。
3.5 getForDefault
/** @since 1.8
*/
default V getOrDefault(Object key, V defaultValue) {
V v;
return (((v = get(key)) != null) || containsKey(key))
? v
: defaultValue;
}塞个默认值,不需要自己实现,已经自带了。
3.6 merge
/** @since 1.8
*/
default V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
Objects.requireNonNull(value);
V oldValue = get(key);
//这一步体现本质
V newValue = (oldValue == null) ? value :
remappingFunction.apply(oldValue, value);
if(newValue == null) {
remove(key);
} else {
put(key, newValue);
}
return newValue;
}value值merge,排除value为null的key。
3.7 总结
map增加了参数为函数式接口的default方法,体现了观察者模式,这种设计模式。
我们也可以default方法,自己定义函数式接口参数,实现自己的特定功能。