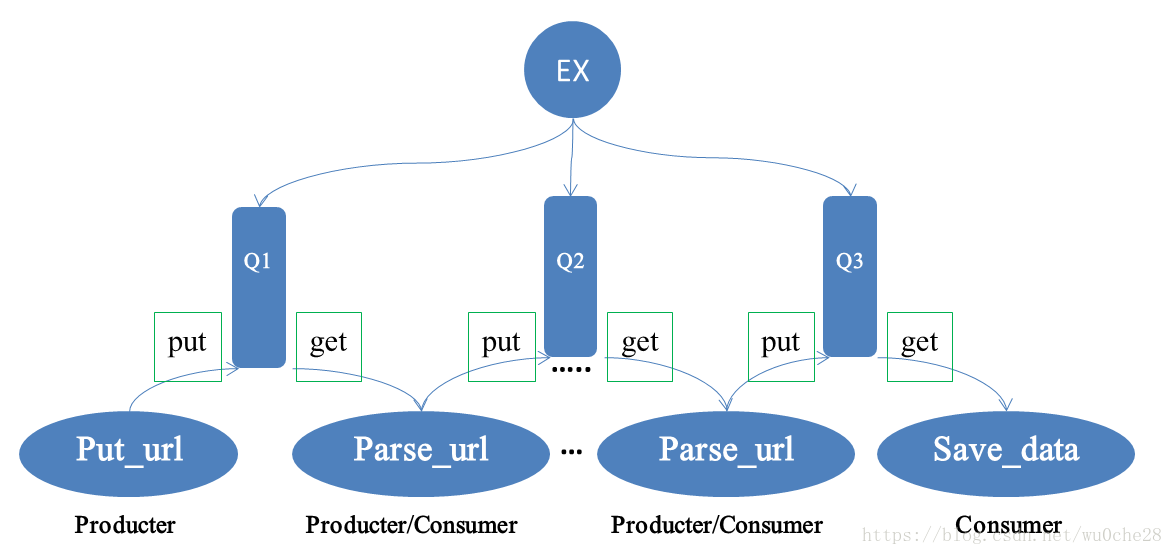
先来一张图,自己画的:
使用consumer自己即是消费者也是生产者,可以开多线程,产生多个consumer,既消费又产出,producter的消息应该是传到Ex中,方便说明问题,直接搭在Queue上了
代码:
只需要写callback里面的函数,以参数形式传到recv_task中就可以了
这里callback注意base_ack,及时通知rabbitmq,清理已经完成的任务,否则会造成队列堵塞.consumer中出现异常也会造成阻塞哦,问题会一大堆呢
import pika
def send_task(queue_name, task):
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()
# 声明一个exchange
channel.exchange_declare(exchange='messages', exchange_type='direct')
# 声明queue
channel.queue_declare(queue=queue_name, durable=True)
# n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
channel.queue_bind(exchange='messages',
queue=queue_name,
routing_key=queue_name)
channel.basic_publish(exchange='messages',
routing_key=queue_name,
body=task,
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
)
)
print(" [x] Sent %r" % task)
connection.close()
def recv_task(queue_name, callback):
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()
# 声明一个exchange
channel.exchange_declare(exchange='messages', exchange_type='direct')
# 声明queue
channel.queue_declare(queue=queue_name, durable=True)
# n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
channel.queue_bind(exchange='messages',
queue=queue_name,
routing_key=queue_name)
channel.basic_consume(callback,
queue=queue_name,
no_ack=False)
channel.basic_qos(prefetch_count=1)
channel.start_consuming()
print(' [*] Waiting for messages. To exit press CTRL+C')
# channel.start_consuming()
spider部分:
实力部分方便自己以后学习放上来,pornhub的爬取视屏资源
# -*- coding:utf-8 -*-
# @Author: YOYO
# @Time: 2018/9/9 10:34
# @说明:
# -*- coding:utf-8 -*-
# @Author: YOYO
# @Time: 2018/9/8 10:40
# @说明:
import json
import traceback
import re
import requests
from lxml import etree
import threading
from urllib3 import disable_warnings
from urllib3.exceptions import InsecureRequestWarning
from rq import send_task, recv_task
# 禁用安全请求警告
disable_warnings(InsecureRequestWarning)
class P_hub():
def __init__(self):
self.s = requests.session()
self.temp_url = "https://www.pornhub.com/video?page={}"
self.headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"cookie": "bs=99qo76aaczrxqzyt5kefg7tiu508vewy; ss=254860751071527261; _ga=GA1.2.1088829113.1535332614; ua=613782f5eec3022d3655b0953c1749a9; platform=pc; _gid=GA1.2.1320545763.1536366483; RNLBSERVERID=ded6648; performance_timing=video; _gat=1; RNKEY=1129409*1766179:1818133520:3580375550:1",
}
self.url_queue = "url_queue"
self.html_queue = "html_queue"
self.content_list_queue = "content_list_queue"
self.proxies = {
"https": "https://127.0.0.1:1080"
}
def get_url_list(self):
for i in range(1, 2):
send_task(self.url_queue, self.temp_url.format(i))
def parse_url_callback(self, ch, method, properties, body):
print("parse_url_callback", threading.current_thread().name)
url = body
try:
response = self.s.get(url, headers=self.headers, proxies=self.proxies, verify=False)
except Exception as e:
print(e)
send_task(self.url_queue, url)
else:
res = etree.HTML(response.text)
first_pages = res.xpath('//div[@class="sectionWrapper"]/ul/li')
url_list = []
print("length:",len(first_pages))
for i in first_pages:
url = i.xpath('./div/div/span[1]/a/@href')
url = "https://www.pornhub.com" + "".join(url)
url_list.append(url)
url_list = json.dumps(url_list)
send_task(self.html_queue, url_list)
ch.basic_ack(delivery_tag=method.delivery_tag) # 手动告诉rabbitmq确认任务完成
def parse_main_url(self):
recv_task(self.url_queue,self.parse_url_callback)
def parse_detail_url(self):
recv_task(self.html_queue,self.get_content_callback)
def get_content_callback(self, ch, method, properties, body):
urls=json.loads(body)
data = []
for url in urls:
print("ts",url)
if "http" not in url:
ch.basic_ack(delivery_tag=method.delivery_tag) # 手动告诉rabbitmq确认任务完成
return
item = {}
try:
response = self.s.get(url, headers=self.headers, proxies=self.proxies, verify=False)
except Exception as e:
urls.append(url) # 再放回去
# ch.basic_ack(delivery_tag=method.delivery_tag) # 手动告诉rabbitmq确认任务完成
continue
else:
try:
item["video_url"] = re.findall(r'"quality":"480","videoUrl":"(.*?)"}', response.text)[0]
item["video_url"] = item["video_url"].replace("\\", "")
item["title"] = "".join(re.findall(r'<span class="inlineFree">(.*?)</span>', response.text))
item["views"] = "".join(re.findall(r'<span class="count">(.*?)</span>', response.text))
item["score"] = "".join(re.findall(r'<span class="percent">(.*?)</span>', response.text))
print("item:", item)
data.append(item)
except Exception:
print('get_content erro :traceback.format_exc():\n%s' % traceback.format_exc())
print("meiyo:",url)
urls.append(url)
# send_task(self.html_queue, url) # 再放回去
print(response.text)
# ch.basic_ack(delivery_tag=method.delivery_tag) # 手动告诉rabbitmq确认任务完成
# return
data = json.dumps(data)
print("get_content_callback,send")
send_task(self.content_list_queue, data)
ch.basic_ack(delivery_tag=method.delivery_tag) # 手动告诉rabbitmq确认任务完成
def save_content(self): # 保存
recv_task(self.content_list_queue, self.save_data_callback)
def save_data_callback(self, ch, method, properties, body):
data = json.loads(body)
for item in data:
try:
with open("p_hub.csv", "a")as f:
f.write(item["title"].encode("utf8") + "," +
item["video_url"].encode("utf8") + "," +
item["views"].encode("utf8") + "," +
item["score"].encode("utf8") + "\n"
)
except Exception as e:
print("保存异常:", e)
continue
ch.basic_ack(delivery_tag=method.delivery_tag) # 手动告诉rabbitmq确认任务完成
def run(self):
thread_list = []
t_geturl = threading.Thread(target=self.get_url_list)
thread_list.append(t_geturl)
for i in range(5):
t_parse_main_url = threading.Thread(target=self.parse_main_url)
thread_list.append(t_parse_main_url)
for i in range(10):
print(i)
t_parse_detail_url = threading.Thread(target=self.parse_detail_url)
thread_list.append(t_parse_detail_url)
for i in range(10):
t_save = threading.Thread(target=self.save_content)
thread_list.append(t_save)
for t in thread_list:
t.start()
# for q in [self.url_queue, self.html_queue, self.content_list_queue]:
# q.join() # 让主线程阻塞,等待队列计数为0
if __name__ == '__main__':
p = P_hub()
p.run()