几个流行的VSM算法:
Term Frequency * Inverse Document Frequency, Tf-Idf
from gensim import corpora, models, similarities
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
tfidf = models.TfidfModel(corpus)
corpus_tfidf = tfidf[corpus]Latent Semantic Indexing, LSI (or sometimes LSA)
LSA是SVD在文本数据上的变体。
Those days we know that most current LSI models are not based on mere local weights, but on models that incorporate local, global and document normalization weights. Others incorporate entropy weights and link weights. We also know that modern models ignore stop words and terms that occur once in document. Term stemming and sorting in alphabetical order is optional.
lsi = models.LsiModel(corpus_tfidf, id2word=dictionary, num_topics=200)
corpus_lsi = lsi[corpus_tfidf]举例:用LSI来为docments和query排序:
- step 1. 计算文档向量矩阵A和查询矩阵q
- step 2. 对矩阵A进行SVD分解
- step 3. 用秩为N的矩阵来近似表示A,文档向量可以用V来表示。
- Step 4. 同样的对查询q进行表示:
- Step 5. 计算query-document的余弦相似度
doc = "Human computer interaction"
vec_bow = dictionary.doc2bow(doc.lower().split())
vec_lsi = lsi[vec_bow] # convert the query to LSI space
index = similarities.MatrixSimilarity(lsi[corpus]) # transform corpus to LSI space and index it
sims = index[vec_lsi] # perform a similarity query against the corpus
print(list(enumerate(sims))) # print (document_number, document_similarity) 2-tuples
sims = sorted(enumerate(sims), key=lambda item: -item[1])
print(sims) # print sorted (document number, similarity score) 2-tuplesProbabilistic Latent Semantic Analysis, PLSA
Hoffman 于 1999 年提出的PLSA,Hoffman 认为一篇文档(Document) 可以由多个主题(Topic) 混合而成, 而每个Topic 都是词汇上的概率分布,文章中的每个词都是由一个固定的 Topic 生成的。
文档和文档之间是独立可交换的,同一个文档内的词也是独立可交换的,这是一个 bag-of-words 模型。 存在K个topic-word的分布,我们可以记为 对于包含M篇文档的语料 中的每篇文档 ,都会有一个特定的doc-topic分布 。于是在 PLSA 这个模型中,第m篇文档 dm 中的每个词的生成概率为
所以整篇文档的生成概率为
由于文档之间相互独立,我们也容易写出整个语料的生成概率。求解PLSA 这个 Topic Model 的过程汇总,模型参数并容易求解,可以使用著名的 EM 算法进行求得局部最优解。
Latent Dirichlet Allocation, LDA
主题模型是一族生成式有向图模型,主要用于处理离散的数据(如文本集合),在信息检索、自然语言处理等领域有广泛应用。隐含狄利克雷分配模型(LDA)是主题模型的典型代表。
主题模型中的概念:词(word)、文档(document)、主题(topic)
任务:拿到一个文本集合并对它做反向工程,从中发现都有哪些主题,以及每个文档属于哪个主题。
假设数据集中一共包含K个话题和M篇文档,文档中的词来自一个包含N个词的词典。我们用M个N维向量W表示数据集(文档集合),用K个N维向量 表示话题。 LDA从生成模型的角度来看待文档和话题,LDA认为每篇文档包含多个话题,用 (K维)表示文档m中所包含的每个话题的比例, 即表示文档m中包含话题k的比例,进而通过下面步骤生成文档m:
- 根据参数为 的狄利克雷分布随机采样一个话题分布 (较大的 会导致每个文档中包含更多的主题)
- 按如下步骤生成文档中的N个词:
- 根据 进行话题指派,得到文档t中词n的话题
- 根据指派的话题所对应的词频分布 随机采样生成词
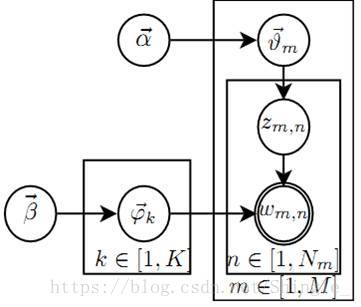
- is the parameter of the Dirichlet prior on the per-document topic distributions,
- is the parameter of the Dirichlet prior on the per-topic word distribution,
- is the topic distribution for document m,
- is the word distribution for topic k,
- is the topic for the n-th word in document m,
- is the specific word.
上述只有词 是观测变量,其他变量都是隐含变量。
显然,这样生成的文档自然地以不同比例包含多个主题,文档中的每个词来自一个主题,而这个主题是依据主题比例产生的。
LDA模型对应的概率分布为:
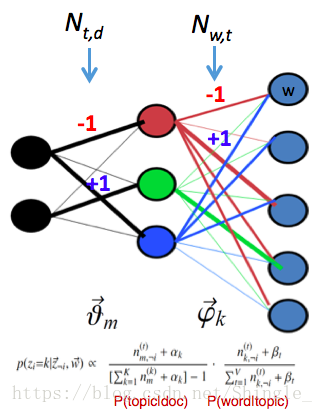
若模型已知,即参数 和 已确定,则根据词频 来推断文档集所对应的话题结构(即推断 , 和 )则可以通过求解:
然而分母上的 难以获取,上式难以直接求解,因此实践中通过采样吉布斯采样或变分法进行近似推断。
model = models.LdaModel(corpus, id2word=dictionary, num_topics=100)LDA可以视为PLSA的经验贝叶斯版本,由于PLSA不是指数族分布,而是其混合分布,因此其贝叶斯版本不能使用EM算法。
- Deterministic inference:可用变分近似,假设z和 的后验分布独立迭代求解过程与EM非常相似,称为VBEM;在大多数问题上无法保证收敛到局部最优
- Probabilistic inference:可用Gibbs-sampling(Markov-chain Monte-Carlo, MCMC, 的一种),以概率1收敛到局部最优。
Topic Model的并行化
EM及VBEM的并行化:(pLSA)
- E-step(mapper):可以方便地并行计算
- M-step(reducer):累加E-step各部分统计量后更新模型
- 将更新后的模型分发到新的E-step各个计算服务器上
AD-LDA: Gibbs sampling的并行化:
- Mapper:在部分data上分别进行Gibbs sampling
- Reducer:全局update:
文档的Topic model抽取可以认为是一个大量(而非海量)数据运算,采用类MPI架构的分布式计算架构(例如spark)会比map\reduce效率更高。
Distributed Algorithms for Topic Models
http://www.jmlr.org/papers/volume10/newman09a/newman09a.pdf
SparseLDA
《Efficient Methods for Topic Model Inference on Streaming Document Collections》 Limin Yao, David Mimno, and Andrew McCallum. In KDD’ 2009.
AliasLDA
《Reducing the sampling complexity of topic models》 Aaron Q. Li, Amr Ahmed, Sujith Ravi, and Alexander J. Smola. In KDD’ 2014. http://www.sravi.org/pubs/fastlda-kdd2014.pdf
LightLDA
Random Projections, RP
model = models.RpModel(tfidf_corpus, num_topics=500)Hierarchical Dirichlet Process, HDP
(a non-parametric bayesian method (note the missing number of requested topics))
层次狄利克雷过程:可以根据数据集自动确定主题的个数。
狄利克雷过程是非参数学习(non parameter)中非常流行的理论。
举例:中国餐馆过程(Chinese Restaurant Process ):
假设一个中国餐馆有无限的桌子,第一个顾客到来之后坐在第一张桌子上。第二个顾客来到可以选择坐在第一张桌子上,也可以选择坐在一张新的桌子上,假设第 个顾客到来的时候,已经有k张桌子上有顾客了,分别坐了 个顾客,那么第 个顾客可以以概率为 坐在第i张桌子上, 为第i张桌子上的顾客数;同时有概率为 选取一张新的桌子坐下。那么在n个顾客坐定之后,很显然CRP把这n个顾客分为了K个堆,即K个clusters,可以证明CRP就是一个DP。
注意这里有一个限制,每张桌子上只能有同一个dish,即一桌人喜欢吃同一道菜。
model = models.HdpModel(corpus, id2word=dictionary)如何计算两个文档的相似度
First
Wikipedia
TF-IDF, Cosine_similarity, VSM
《数学之美》第11章“如何确定网页和查询的相关性”
其中【延伸阅读:TF-IDF的信息论依据】很有趣。其中信息论部分又涉及到【第六章信息的度量和作用】。
《数学之美》第14章“余弦定理和新闻的分类”
http://www.ruanyifeng.com/blog/2013/03/tf-idf.html
http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
SVD, LSI
http://cs.fit.edu/~dmitra/SciComp/Resources/singular-value-decomposition-fast-track-tutorial.pdf
LDA
http://www.52nlp.cn/lda-math-%E6%B1%87%E6%80%BB-lda%E6%95%B0%E5%AD%A6%E5%85%AB%E5%8D%A6
相关:
https://en.wikipedia.org/wiki/Vector_space_model
https://en.wikipedia.org/wiki/Latent_semantic_analysis#Latent_semantic_indexing
https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation
《Latent Dirichlet Allocation》 http://www.jmlr.org/papers/volume3/blei03a/blei03a.pdf
https://radimrehurek.com/gensim/tutorial.html
《Building Machine Learning Systems With Python》 4
《机器学习》 14.6