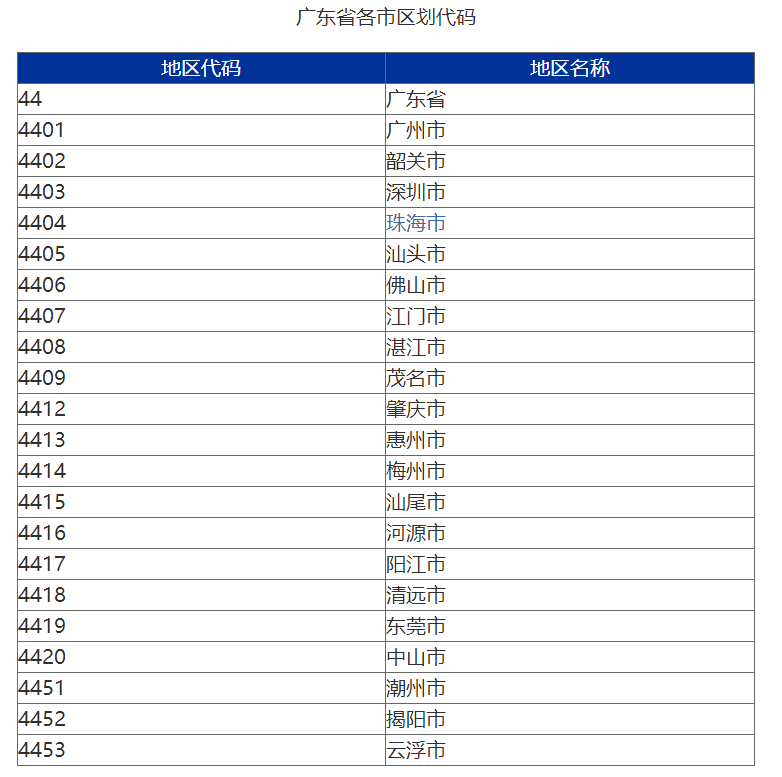
最近在做广东省XXX项目,包含21个地市的数据,其中有些表每个有月总共有几千万的数据产生,讨论后,决定按地区进行分库分表,id由地区编码+yyyyMMdd+XXXXXXXXX格式组成,其他条件查询的时候,必须指明是哪个地区的等相关细节规则,刚开始时间紧急,只有一个星期的开发时间,所以采取了spring的动态路由AbstractRoutingDataSource这技术实现数据源的动态切换。
现在尝试用mycat模拟实现下。在mysql中创建广州库gz_4401,深圳库sz_4403,他们都有一个产品表product(id,areaCode,productName,produceDate)为了简单点,字段就不搞那么多。资源有限,这两个库在同一个server上。
CREATE TABLE `product` (
`id` varchar(50) NOT NULL,
`area_code` int(11) DEFAULT '0',
`product_name` varchar(50) DEFAULT NULL,
`product_date` int(11) DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='产品表';mycat是个中间件,它负责连接管理mysql,应用程序连接mycat,把mycat当作mysql服务那样连接操作。

上2篇博文,我们学习centos7和eclipse下运行mycat,现在为了方便修改配置及查看源码,使用eclipse运行源码模式来学习。先把server.xml,schema.xml,rule.xml都复制备份一份,便于查看原例子的配置,然后把server.xml,schema.xml,rule.xml里面的一些配置都清空,根据实际自己配置一次。
看rule.xml发现已经有10种分配规则已经定义好了,当然还可以自定义,毕竟源码都拿到手了。至于10中规则具体是什么,下一篇博文学习。现在先简单弄好按地区编码进行分库分表保存数据先,看看效果先。
schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 逻辑库配置 -->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!-- 按地区编码规则进行分片 -->
<table name="product" dataNode="dn1,dn2" rule="sharding-areacode" />
</schema>
<!-- 分片节点配置 -->
<dataNode name="dn1" dataHost="mysql101" database="gz_4401" />
<dataNode name="dn2" dataHost="mysql101" database="sz_4403" />
<!-- 数据库服务器配置 -->
<dataHost name="mysql101" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.0.101:3306" user="root" password="paas">
<!-- 可以在这配置它对应的多个读库 -->
<!-- <readHost host="hostS2" url="192.168.1.200:3306" user="root" password="xxx" /> -->
</writeHost>
</dataHost>
</mycat:schema> dataHost标签上属性释义:
-
balance:负载均衡类型-
0:不开启读写分离机制,所有读操作都发送到当前可用的writeHost上
-
1:全部的readHost与stand by writeHost参与select语句的负载均衡,
-
2:所有读操作都随机在writeHost、readHost上分发
-
3:所有读请求随机分发到writeHost对应的readHost执行,writeHost不负担读压力
-
-
writeType:负载均衡类型-
0:所有写操作发送到配置的第一个writeHost,当第一个writeHost宕机时,切换到第二个writeHost,重新启动后以切换后的为准,切换记录在配置文件:
dnindex.properties中 -
1:所有写操作都随发送到配置的writeHost
-
2:尚未实现
-
-
switchType:切换方式-
-1:不自动切换
-
1:自动切换(默认)
-
2:基于MySql主从同步的状态来决定是否切换
-
dn1,dn2这名称不是固定的,可以自定义,比如改为dn4401,dn4403也是OK的
rule.xml
<!-- 按地区分片规则 -->
<tableRule name="sharding-areacode">
<rule>
<!-- 数据库表字段名称 -->
<columns>area_code</columns>
<!-- function name名称 -->
<algorithm>rang-areacode</algorithm>
</rule>
</tableRule>
<!-- 按地区分片规则实现 -->
<function name="rang-areacode"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-areacode.txt</property>
</function>
autopartition-areacode.txt,resources文件夹下
# range start-end ,data node index
# K=1000,M=10000.
#0-500M=0
#500M-1000M=1
#1000M-1500M=2
4401-4401=0
4403-4403=1start-end=index,代码判断的时候是 start<= n <= end,包含开始点和结束点,index是schema.xml中配置dataNode的顺序
navicat连接mycat,但是点击打开TESTDB的时候
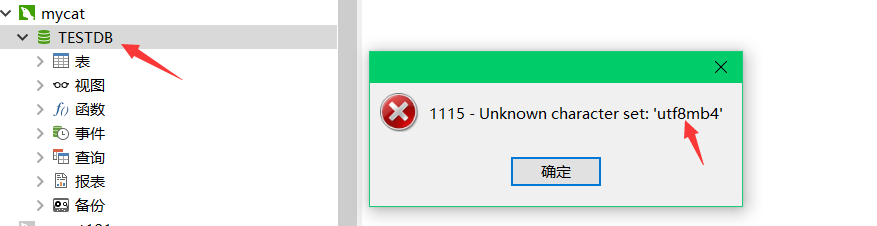
很明显是编码问题,首先查询下mysql的编码,我的mysql编码是utf8,那确保下mycat也是utf8,在server.xml的<system>中加入
<property name="charset">utf8</property><!-- 指定字符集 -->
这样navicat连接mycat就OK了。
在mycat中执行sql测试
insert into product(id,area_code,product_name,product_date) values
('4401201708300001',4401,'辣条',20170830),
('4403201708300001',4403,'老干妈',20170830);