版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/sileixinhua/article/details/78819002
爬虫:爬取豆果网和美食网的菜单
所有代码请到我的github中下载,欢迎star,谢谢。
https://github.com/sileixinhua/SpiderRecipes
前言
本文主要是介绍如果爬取豆果网和美食网的菜单,并保存在本地,我是以列表的形式保存在TXT文件里,大家有兴趣的可以改一改,下载入数据库或者CSV,json等文件都可以。
这里爬出的数据主要是为了下一阶段做菜谱推荐,智能冰箱用的,根据用户以往的饮食习惯的数据,可以推荐今天吃什么,让用户或者自动化下单购买哪些食材,或者直接用appium+Python的方式直接连接安卓手机饿了么自动化下单。
开发环境
windows10
Python3.5
https://www.python.org/downloads/

BeautifulSoup
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html

Requests
http://docs.python-requests.org/en/master/#

可能需要的python包安装(Python3环境)
pip3 install BeautifulSoup
pip3 install requests
pip3 install lxml这里还是推荐使用Python3,但是用Python2的同学,把上述命令的“pip3”改成“pip”就可以了。
爬虫目标网页结构分析
豆果网
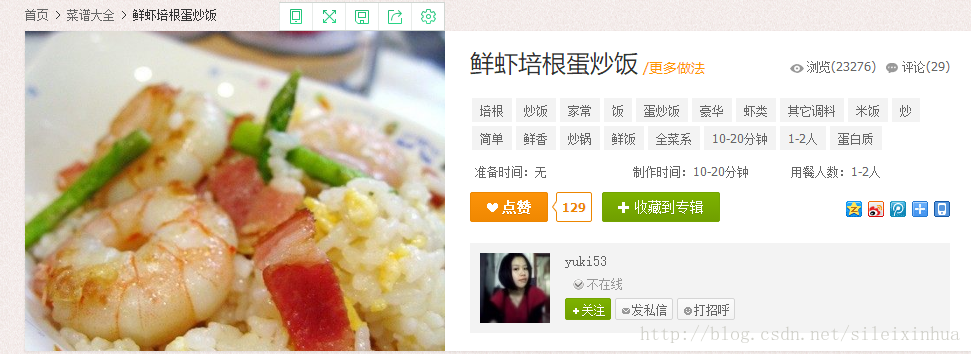



美食网
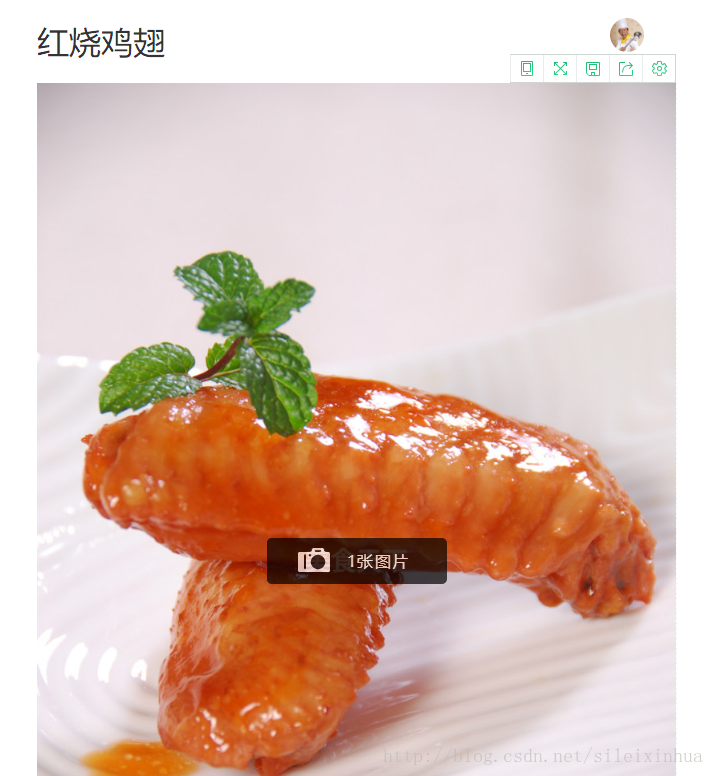





代码分析
豆果网
# 2017年12月6日 00点51分
# 作者:橘子派_司磊
# 爬虫:抓好豆菜谱
# 目标网址:http://www.haodou.com/recipe/30/
from bs4 import BeautifulSoup
import requests
import os
import urllib.request
import re
# C:\Code\Recipes\Data\HaoDou\490
# C:\Code\Recipes\Data\HaoDou\14059_1201100
# 30-490 为页面简单
# 14059-1201100 为复杂
# id = 29
id = 29
# error_number为抓取错误的页面
error_number = 0
while(id <= 490):
id = id + 1
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
url = requests.get('http://www.haodou.com/recipe/'+str(id)+'/', headers=headers)
print("当前爬取的网址为:" + url.url)
html_doc = url.text
soup = BeautifulSoup(html_doc,"lxml")
recipe_name = soup.find(id="showcover").get('alt')
print("菜谱的名字为:" + recipe_name)
img_html = soup.find(id="showcover").get('src')
print("获取图片为:" + img_html)
file = open('C:\\Code\\Recipes\\Data\\HaoDou\\490\\' + recipe_name + '.jpg',"wb")
req = urllib.request.Request(url=img_html, headers=headers)
try:
image = urllib.request.urlopen(req, timeout=10)
pic = image.read()
except Exception as e:
print(e)
print(recipe_name + "下载失败:" + img_html)
# 遇到错误,网站反爬虫
# urllib.error.HTTPError: HTTP Error 403: Forbidden
# 原因是这里urllib.request方法还需要加入“, headers=headers”
# 头文件来欺骗,以为我们是客户端访问
file.write(pic)
print("图片下载成功")
file.close()
drop_html = re.compile(r'<[^>]+>',re.S)
full_text = []
recipe_text = soup.find_all('dd')
for text_str in recipe_text:
text = drop_html.sub('',str(text_str.find_all('p')))
text = text.replace("[", "")
text = text.replace("]", "")
if text != '':
print(text)
full_text.append(text)
# print(recipe_text)
file = open('C:\\Code\\Recipes\\Data\\HaoDou\\490\\' + recipe_name + '.txt', 'w')
file.writelines(str(full_text))
file.close()
except Exception as e:
print(e)
error_number = error_number + 1
else:
continue
print("抓取错误的页面数量为:" + str(error_number))
while(id < 1201100):
id = id + 1
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
url = requests.get('http://www.haodou.com/recipe/'+str(id)+'/', headers=headers)
print("当前爬取的网址为:" + url.url)
html_doc = url.text
soup = BeautifulSoup(html_doc,"lxml")
# http://www.haodou.com/recipe/14059/
recipe_name = soup.find(id="showcover").get('alt')
print("菜谱的名字为:" + recipe_name)
img_html = soup.find(id="showcover").get('src')
print("获取图片为:" + img_html)
file = open('C:\\Code\\Recipes\\Data\\HaoDou\\14059_1201100\\' + recipe_name + '.jpg',"wb")
req = urllib.request.Request(url=img_html, headers=headers)
try:
image = urllib.request.urlopen(req, timeout=10)
pic = image.read()
except Exception as e:
print(e)
print(recipe_name + "下载失败:" + img_html)
else:
continue
# 遇到错误,网站反爬虫
# urllib.error.HTTPError: HTTP Error 403: Forbidden
# 原因是这里urllib.request方法还需要加入“, headers=headers”
# 头文件来欺骗,以为我们是客户端访问
file.write(pic)
print("图片下载成功")
file.close()
# 爬取 简介 full_text_introduction
full_text_introduction = []
full_text_introduction = soup.find(id="sintro").get('data')
print("简介")
print(full_text_introduction)
# 爬取 食材 主料 full_text_ingredients
full_text_ingredients = []
full_text_ingredients = soup.findAll("li", { "class" : "ingtmgr" })
print("主料")
for text in full_text_ingredients:
print(text.text)
# 爬取 食材 辅料 full_text_accessories
full_text_accessories = []
full_text_accessories = soup.findAll("li", { "class" : "ingtbur" })
print("辅料")
for text in full_text_accessories:
print(text.text)
# 爬取 步骤 图 full_text_step_img
full_text_step_img = soup.findAll("img", { "width" : "190" })
print("图")
img_number = 0
for text in full_text_step_img:
print(text.get('src'))
img_html = text.get('src')
file = open('C:\\Code\\Recipes\\Data\\HaoDou\\14059_1201100\\' + recipe_name + '_' + str(img_number) + '.jpg',"wb")
req = urllib.request.Request(url=img_html, headers=headers)
img_number = img_number + 1
try:
image = urllib.request.urlopen(req, timeout=10)
pic = image.read()
file.write(pic)
print("图片下载成功")
file.close()
except Exception as e:
print(e)
print(recipe_name + "下载失败:" + img_html)
# else:
# continue
# 爬取 步骤 文字 full_text_step_text
full_text_step_text = []
full_text_step_text = soup.findAll("p", { "class" : "sstep" })
print("文字")
for text in full_text_step_text:
print(text.text)
# 爬取 小贴士 full_text_tip
full_text_tip = []
full_text_tip = soup.find(id="stips").get('data')
print("小贴士")
print(full_text_tip)
# 全部写入TXT文件
file = open('C:\\Code\\Recipes\\Data\\HaoDou\\14059_1201100\\' + recipe_name + '.txt', 'w')
full_text = []
full_text.append(full_text_introduction)
full_text.append(full_text_ingredients)
full_text.append(full_text_accessories)
full_text.append(full_text_step_text)
full_text.append(full_text_tip)
full_text = BeautifulSoup(str(full_text),"lxml").text
file.writelines(str(full_text))
file.close()
except Exception as e:
print(e)
error_number = error_number + 1
else:
continue美食网
# 2017年12月6日 00点51分
# 作者:橘子派_司磊
# 爬虫:抓美食天下菜谱
# 目标网址:http://home.meishichina.com/recipe-1.html
from bs4 import BeautifulSoup
import requests
import os
import urllib.request
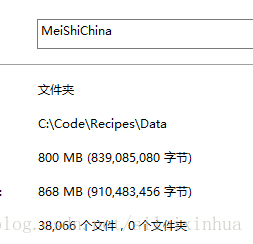
# C:\Code\Recipes\Data\MeiShiChina
# 1-363298 页面
id = 1
# error_number为抓取错误的页面
error_number = 0
while(id < 363298):
id = id + 1
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
url = requests.get('http://home.meishichina.com/recipe-'+str(id)+'.html', headers=headers)
print("当前爬取的网址为:"+url.url)
html_doc = url.text
soup = BeautifulSoup(html_doc,"lxml")
# 爬取 菜名 recipe_name
recipe_name = []
recipe_name = soup.find(id="recipe_title").get("title")
print(recipe_name)
# 爬取 菜图片
recipe_img = soup.findAll("a", { "class" : "J_photo" })
for img in recipe_img:
img_html = img.find("img").get("src")
print(img_html)
file = open('C:\\Code\\Recipes\\Data\\MeiShiChina\\' + recipe_name + '.jpg',"wb")
req = urllib.request.Request(url=img_html, headers=headers)
try:
image = urllib.request.urlopen(req, timeout=10)
pic = image.read()
except Exception as e:
print(e)
print(recipe_name + "下载失败:" + img_html)
# 遇到错误,网站反爬虫
# urllib.error.HTTPError: HTTP Error 403: Forbidden
# 原因是这里urllib.request方法还需要加入“, headers=headers”
# 头文件来欺骗,以为我们是客户端访问
file.write(pic)
print("图片下载成功")
file.close()
# 爬取 食材明细
recipe_material = []
# tip: 如果 div后面加空格的话 即 "div " ,则结果汉字都变成乱码 且 进行不下去
# 最终发现输出结果是乱码的原因是使用了get_text()函数,应该用 .text
recipe_material = soup.findAll("div", { "class" : "recipeCategory_sub_R clear" })
for material in recipe_material:
print(material.text)
# 爬取 评价 recipe_judgement
recipe_judgement = []
recipe_judgement = soup.findAll("div", { "class" : "recipeCategory_sub_R mt30 clear" })
for judgement in recipe_judgement:
print(judgement.text)
# 爬取 做法步骤 图片
# <img alt="鸭脚、鸡爪煲的做法步骤:6" src="http://i3.meishichina.com/attachment/recipe/201007/201007052343079.JPG@!p320"/>
recipe_step_img = soup.findAll("div", { "class" : "recipeStep_img" })
number = 0
for img in recipe_step_img:
img = img.find_all("img")
for img_html in img:
img_html = img_html.get("src")
print(img_html)
file = open("C:\\Code\\Recipes\\Data\\MeiShiChina\\" + recipe_name + "_" + str(number) + ".jpg","wb")
req = urllib.request.Request(url=img_html, headers=headers)
number = number + 1
try:
image = urllib.request.urlopen(req, timeout=10)
pic = image.read()
except Exception as e:
print(e)
print(recipe_name + "下载失败:" + img_html)
# 遇到错误,网站反爬虫
# urllib.error.HTTPError: HTTP Error 403: Forbidden
# 原因是这里urllib.request方法还需要加入“, headers=headers”
# 头文件来欺骗,以为我们是客户端访问
file.write(pic)
print("图片下载成功")
file.close()
# 爬取 做法步骤 文字 recipe_step_text
recipe_step_text = []
recipe_step_text = soup.findAll("div", { "class" : "recipeStep_word" })
for step_text in recipe_step_text:
print(step_text.text)
# 爬取 小窍门 recipe_tip
recipe_tip = []
recipe_tip = soup.findAll("div", { "class" : "recipeTip" })
for tip in recipe_tip:
print(tip.text)
# 全部写入TXT文件
file = open("C:\\Code\\Recipes\\Data\\MeiShiChina\\" + recipe_name + ".txt", "w")
full_text = []
full_text.append(recipe_name)
full_text.append(recipe_material)
full_text.append(recipe_judgement)
full_text.append(recipe_step_text)
full_text.append(recipe_tip)
full_text = BeautifulSoup(str(full_text),"lxml").text
file.writelines(str(full_text))
file.close()
except Exception as e:
print(e)
error_number = error_number + 1
else:
continue
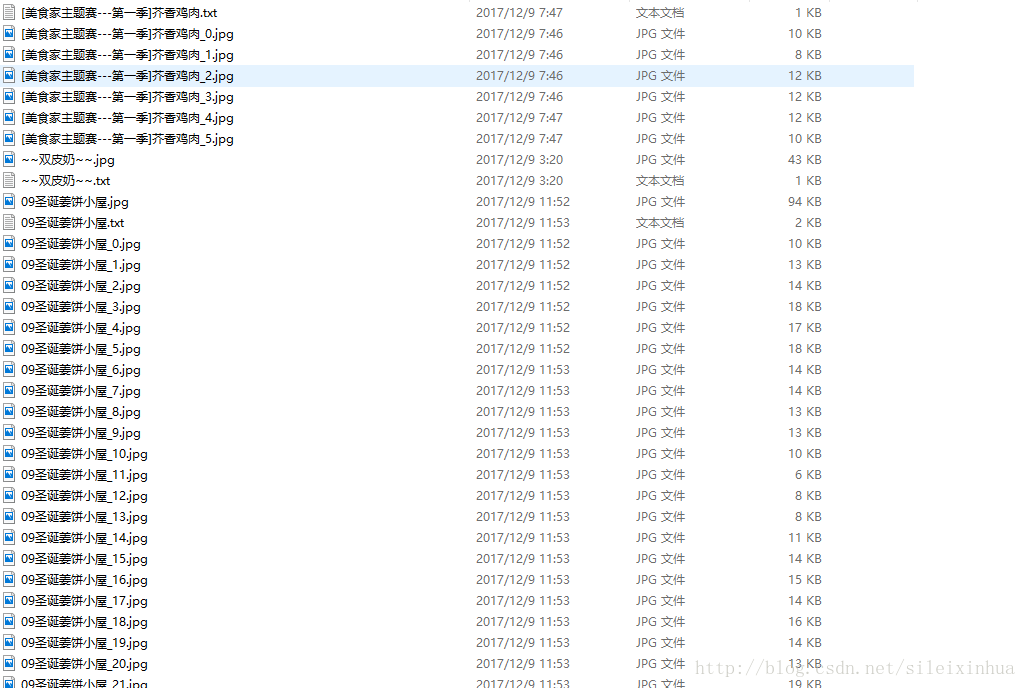
实验结果
豆果网
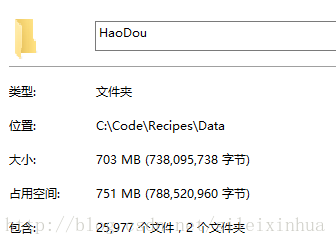
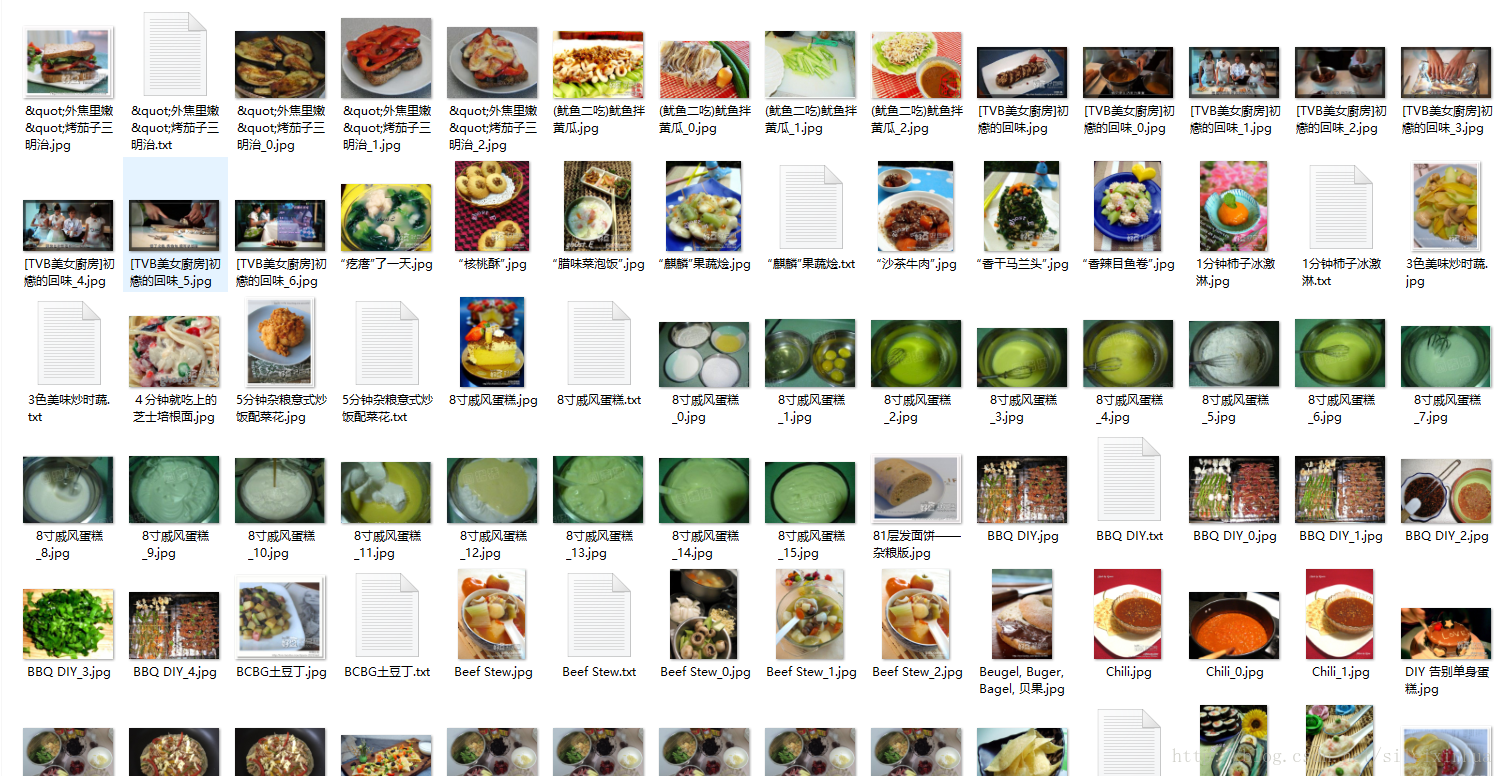

美食网

——————————————————————————————————-
有学习机器学习相关同学可以加群,交流,学习,不定期更新最新的机器学习pdf书籍等资源。
QQ群号: 657119450
