最近研究深度学习,对tensorflow的CPU版本和GPU版本一直很疑惑。
CPU大家都很熟悉,这里重点介绍下GPU。
--------------------------------------------------------------------------------------------
为什么GPU比CPU更diao呢?
这就需要从他们的区别入手
那他们的区别是什么呢?
这就需要从他的原理出发了,由于其设计目标的不同,它们分别针对了两种不同的应用场景
CPU 需要很强的通用性
为了处理各种不同的数据类型,同时又要逻辑判断而引入大量的分支跳转和中断的处理。
这些都使得CPU的内部结构异常复杂。
While GPU 面对的是类型高度统一的、互相无依赖的大规模数据和不需要被打断的纯净的计算环境 。
于是乎:CPU和GPU就呈现出非常不同的架构(看图)
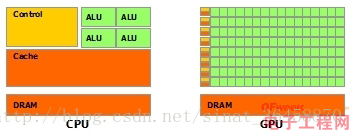
- 鲜绿色:计算单元ALU(Arithmetic Logic Unit)
- 橙红色:存储单元(cache)
- 橙黄色:控制单元(control)
GPU:数量众多的计算单元和超长的流水线,只有简单的控制逻辑并省去了Cache
CPU:被Cache占据了大量空间,而且还有有复杂的控制逻辑和诸多优化电路。
结果可想而知。
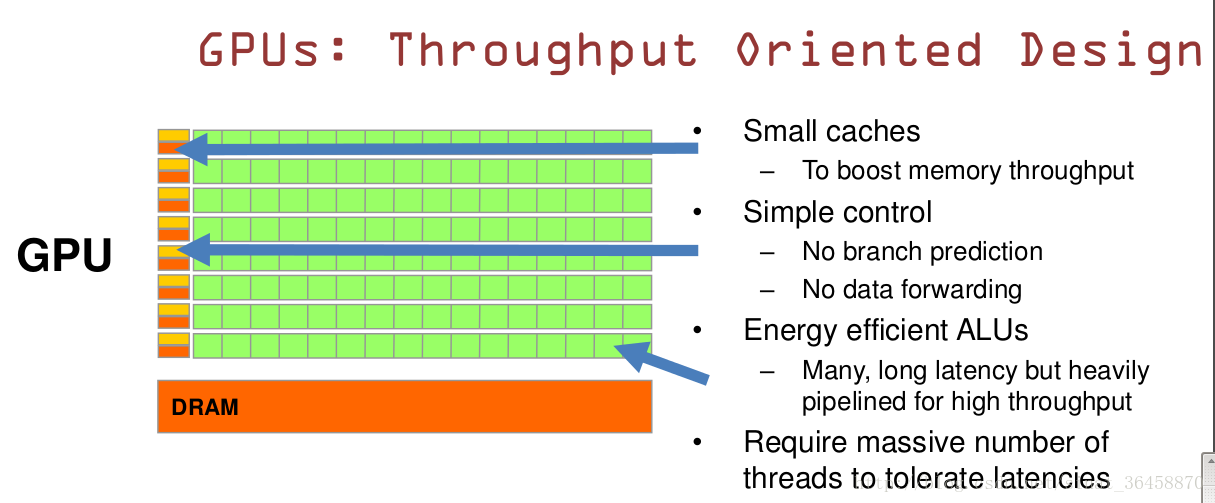
GPU是基于大的吞吐量
特点:很多的ALU和很少的cache
-
缓存的目的不是保存后面需要访问的数据,这点和CPU不同,而是为thread提高服务
如果有很多线程需要访问同一个相同的数据?
缓存会合并这些访问,然后再去访问dram(因为需要访问的数据保存在dram中而不是cache里面)获取数据后cache会转发这个数据给对应的线程,这个时候是数据转发的角色。
GPU的控制单元(左边黄色区域块)可以把多个的访问合并成少的访问。
有一个例子说的很好:
-
GPU的工作大部分就是这样,计算量大,而且要重复很多很多次。就像你有个工作需要算几亿次一百以内加减乘除一样,最好的办法就是雇上几十个小学生一起算,一人算一部分
-
CPU就像老教授,积分微分都会算,就是工资高,一个老教授资顶二十个小学生,你要是富士康你雇哪个
- CPU和GPU因为最初用来处理的任务就不同,所以设计上有不小的区别,而某些任务和GPU最初用来解决的问题比较相似,所以用GPU来算了
- - GPU的运算速度取决于雇了多少小学生,CPU的运算速度取决于请了多么厉害的教授。教授处理复杂任务的能力是碾压小学生的,但是对于没那么复杂的任务,还是顶不住人多。
- - 当然现在的GPU也能做一些稍微复杂的工作了,相当于升级成初中生高中生的水平。但还需要CPU来把数据喂到嘴边才能开始干活,究竟还是靠CPU来管的。
GPU适合干什么活?
(1)计算密集型的程序
所谓计算密集型(Compute-intensive)的程序,就是其大部分运行时间花在了寄存器运算上,寄存器的速度和处理器的速度相当,从寄存器读写数据几乎没有延时。
可以做一下对比,读内存的延迟大概是几百个时钟周期;读硬盘的速度就不说了,即便是SSD, 也实在是太慢了。
(2)易于并行的程序。
GPU其实是一种SIMD(Single Instruction Multiple Data)架构, 他有成百上千个核,每一个核在同一时间最好能做同样的事情。