第11章 持有对象
11.2 基本概念
Java容器类类库的用途是“保存对象”,并将其划分为两个不同的概念:
1)Collection。一个独立多元素的序列,这些元素都服从一条或多条规则。List必须按照插入的顺序保存元素,而Set不能有重复元素。Queue按照排队规则来确定对象产生的顺序(通常与他们被插入的顺序相同)。
2)Map。一组成对的“键值对”对象,允许你使用键来查找值。ArrayList允许你使用数字来查找值,因此在某种意义上将,它将数字与对象关联在了一起。映射表允许我们是用来另一个对象来查找某个对象,它也被称为“关联数组”,因为它将某些对象与另外一些对象关联在了一起;或者被称为“字典”,因为你可以使用键对象来查找值对象,就像在字典中使用单词来定义一样。Map是强大的编程工具。
11.4容器的打印
/**
* 作者:LKP
* 时间:2018/9/5
*/
public class PrintingContainers {
static Collection fill(Collection<String> collection){
collection.add("rat");
collection.add("cat");
collection.add("dog");
collection.add("dog");
return collection;
}
static Map fill(Map<String,String> map){
map.put("rat","Fuzzy");
map.put("cat","Rags");
map.put("dog","Bosco");
map.put("dog","Spot");
return map;
}
public static void main(String[] args){
/**
* //List,它以特定的顺序保存一组元素
*/
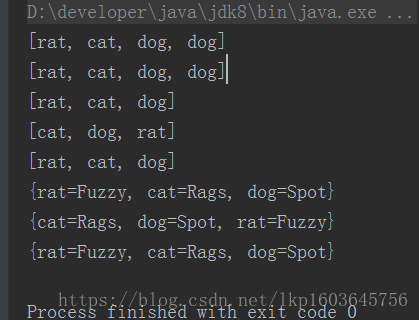
System.out.println(fill(new ArrayList<>())); //ArrayList和LinkedList都是List类型,从输出可以看出,它们都按照被插入的顺序来保存元素。
System.out.println(fill(new LinkedList<>())); //两者的不同之处不仅在于执行某些类型的操作时的性能,而且LinkedList包含的操作也多于ArrayList。
/**
* //Set,元素不能重复
*/
System.out.println(fill(new HashSet<>())); //HashSet使用的是当前复杂的方式来存储元素的,这种技术是最快的获取方式,无序的
System.out.println(fill(new TreeSet<>())); //如果存储顺序重要,那么可以使用TreeSet,它按照比较结果的升序保存对象
System.out.println(fill(new LinkedHashSet<>())); //LinkedHashSet它按照被添加的顺序保存对象。
/**
* //Map在每个槽内保存了两个对象,即键和与之相关联的值
*/
System.out.println(fill(new HashMap<>())); //HashMap也提供了最快的查找技术,也没有按照任何明显的顺序来保存其元素。
System.out.println(fill(new TreeMap<>())); //TreeMap按照比较结果的升序保存键
System.out.println(fill(new LinkedHashMap<>())); //LinkedHashMap则按照插入顺序保存键,同时还保留了HashMap的查询速度。
}
}
输出结果:
11.5 List
List承诺可以将元素维护在特定的序列中。List接口在Collection的基础上添加了大量的方法,使得可以在List的中间插入和移除元素。
有两种类型的List:
- 基本的ArrayList,它长于随机访问元素,但是在List的中间插入和移除要还俗时较慢。
- LinkedList,它通过代价较低的在List中间进行的插入和删除操作,提供了优化的顺序访问。LinkedList在随机访问方面相对较慢,但是它的特性集较ArrayList更大。
11.6 迭代器
迭代器(也是一种设计模式)的概念可以用于达成此目的。迭代器是一个对象,它的工作是遍历并选择序列中的对象,而客户端程序员不必须知道或关心该序列底层的结构。此外,迭代器通常被称为轻量级对象:创建它的代价小。因此,经常可以见到对迭代器有些奇怪的限制;
例如,Java的Iterator只能单向移动,这个Iterator只能用来:

- 使用方法iterator()要求容器返回一个Iterator。Iterator将准备好返回序列的第一个元素。
- 使用next()获得序列中的下一个元素。
- 使用hasNext()检索序列中是否还有元素。
- 使用remove()将迭代器新近返回的元素删除。
11.6.1 ListIterator
ListIterator是一个更加强大的Iterator的子类型,它只能用于各种List类的访问。尽管Iterator只能向前移动,但是LinstIterator可以双向移动。它还可以产生相对于迭代器在列表中指向的当前位置的前一个和后一个元素的索引,并且可以使用set()方法替换它访问过的最后一个元素。你可以通过调用listIterator()方法产生一个指向List开始处的ListIterator,并且还可以通过调用listIterator(n)方法创建一个一开始就指向列表索引为n的元素处的ListIterator。
11.7 LinkedList
LinkedList也像ArrayList一样实现了基本的List接口,但是它执行某些操作(在List的中间插入和移除)时比ArrayList更高效,但在随机访问操作方面却要逊色一些。
LinkedList还添加了可以使其用作栈,队列或双端队列的方法。
这些方法中有些彼此之间只是名称有些差异,或者只存在些许差异,以使得这些名字在特定用法的上下文环境中更加适用(特别是在Queue中)。例如,getFirst()和element()完全一样,它们都返回列表的头(第一个元素),而并不移除它,如果List为空,则抛出异常。peek()方法与这两个方式只是稍有差异,它在列表为空时返回null。
removeFirst()与remove()也是完全一样的,它们移除并返回列表的头,而在列表为空时抛出异常。poll()稍有差异,它在列表为空时返回null。
addFirst()与add()和addLast()相同,它们都将某个元素插入到列表的尾(端)部。
removeLast()移除并返回列表的最后一个元素。
/**
* 作者:LKP
* 时间:2018/9/6
*/
public class LinkedLIstFeatures {
public static void main(String[] args){
LinkedList<Pet> pets = new LinkedList<Pet>(Pets.arrayList(5));
System.out.println(pets);
System.out.println("pets.getFirst():"+pets.getFirst());
System.out.println("pets.element():"+pets.element());
System.out.println("pets.peek():"+pets.peek());
System.out.println("pets.remove():"+pets.remove());
System.out.println("pets.removeFirst():"+pets.removeFirst());
System.out.println("pets.poll():"+pets.poll());
System.out.println(pets);
pets.addFirst(new Rat());
System.out.println("After addFirst():"+pets);
pets.offer(Pets.randomPet());
System.out.println("After offer():"+pets);
pets.add(Pets.randomPet());
System.out.println("After add():"+pets);
pets.addLast(new Hamster());
System.out.println("After addLast():"+pets);
System.out.println("pets.removeLast():"+pets.removeLast());
}
}需要导入一个jar包才能使用Pets类。
jar包地址:https://download.csdn.net/download/lkp1603645756/10650365
11.8 Stack
“栈”通常是值“后进后出”的容器。有时栈也成为叠加栈,因为最后“压人”栈的元素,第一个“弹出”栈。经常用来类比栈的事物是装有弹簧的储放器中的自助餐托盘,最后装入的托盘总是最先拿出使用的。
LinkedList具有能够直接实现栈的所有功能的方法,因此可以直接将LinkedList作为栈使用。不过,有时一个真正的“栈”更够把事情将清楚。
11.9 Set
Set不保存重复的元素(至于如何判断元素相同则较为复杂)。如果你试图将相同对象的多个实例添加到Set中,那么它就会阻止这种重复现象。Set中最常被使用的是测试归属性,你可以很容易地询问某个对象是否在某个Set中。正因如此,查找就成为了Set中最重要的操作,因此你通常都会选择一个HashSet的实现,它专门对快速查找进行了优化。
Set具有与Collection完全一样的接口,因此没有任何额外的功能,不像前面有两个不同的List。实际上Set就是Collection,只是行为不同。(这是继承与多态思想的典型应用:表现不同的行为。)Set是基于对象的值来确定归属性的。
下面是使用存放Integer对象的HashSet的实例:
/**
* 作者:LKP
* 时间:2018/9/10
*/
public class SetOfInteger {
public static void main(String[] args){
Random rand = new Random(47);
Set<Integer> intset = new HashSet<>();
for (int i = 0; i < 10000; i++) {
intset.add(rand.nextInt(30));
}
System.out.println(intset);
}
}运行结果:

在0-29之间的10000个随机数被添加到了Set中,因此你可以想象,每一个数都重复了许多次。但是你可以看到,每一个数只有一个实例出现在结果中。
注意:输出的顺序没有任何规律可循,这是因为处于速度原因的考虑,HashSet使用了散列。HashSet所维护的顺序TreeSet与LinkedHashSet都不同,因为它们的实现具有不同的元素存储方式。TreeSet将元素存储在红——黑树结构中,而HashSet使用的是散列函数。LinkedHashList因为查询速度的原因也使用了散列,但是看起来它使用了链表来维护元素的插入顺序。
如果想对结果排序,一种方式是使用TreeSet来代替HashSet;
11.11 Queue
队列是一个典型的先进先出的容器。即从容器的一端放入事物,从另一端取出,并且事物放入容器的顺序与去除的顺序是相同的。队列常备当做一种可靠的将对象从程序的某个区域传递到另一个区域的途径。队列在并发编程中特别重要,它们可以安全地将对象从一个任务传输给另一个任务。
LinkedList提供了方法已支持队列的行为,并且它实现了Queue接口,因此LinkedList可以用作Queue的一种实现。通过将LinkedList向上转型为Queue。
/**
* 作者:LKP
* 时间:2018/9/10
*/
public class QueueDemo {
public static void printQ(Queue queue){
while(queue.peek() != null){
System.out.print(queue.remove()+" ");
}
System.out.println();
}
public static void main(String[] args){
Queue<Integer> queue = new LinkedList<Integer>();
Random rand = new Random(47);
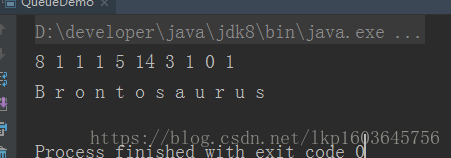
for (int i = 0; i < 10; i++) {
queue.offer(rand.nextInt(i+10));
}
printQ(queue);
Queue<Character> qc = new LinkedList<>();
for (char c : "Brontosaurus".toCharArray()) {
qc.offer(c);
}
printQ(qc);
}
}
offer()方法是与Queue相关的方法之一,它在允许的情况下,将一个元素插入到队尾,或者返回false。peek()和element()都将在不移除的情况下返回队头,但是peek()方法在队列为空时返回null,而element()会抛出NoSuchElementException异常。poll()和remove()方法将移除并返回队头,但是poll()在队列为空时返回null,而remove()会抛出NoSuchElementException异常。
11.11.1 PriorityQueue
新进先出描述了最典型的队列规则。队列规则是指在给定一组队列中的元素的情况下,确定下一个弹出队列的元素的情况下,确定下一个弹出队列的元素的规则。先进先出声明的是下一个元素应该是等待时间最长的元素。
优先级队列声明下一个弹出元素是最重要的元素(具有最高的优先级)。例如,在飞机场,当飞机临近起飞时,这架飞机的乘客可以在办理登记手续时排到队头。如果构建了一个消息系统,某些消息比其他消息更重要,因而应该更快得到处理,那么它们何时得到处理就与它们何时到达无关。PriorityQueue添加到Java SE5中,是为了提供这种行为的一种自动实现。
当你在PriorityQueue上调用offer()方法来传入一个对象时,这个对象会在队列中被排序。默认的排序将使用对象在队列中的自然顺序,但是你可以通过提供自己的Comparator来修改这个顺序。PriorityQueue可以确保当你调用peek(),poll()和remove()方法时,获取的元素将是队列中优先级最高的元素。
/**
* 作者:LKP
* 时间:2018/9/10
*/
public class PriorityQueueDemo {
public static void main(String[] args){
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
Random rand = new Random(47);
for (int i = 0; i < 10; i++) {
priorityQueue.offer(rand.nextInt(i+10));
}
QueueDemo.printQ(priorityQueue);
List<Integer> ints = Arrays.asList(25,22,20,18,13,9,3,1,1,2,3,9,14,18,21,34,25);
priorityQueue = new PriorityQueue<>(ints);
QueueDemo.printQ(priorityQueue);
priorityQueue = new PriorityQueue<>(ints.size(),Collections.reverseOrder());
priorityQueue.addAll(ints);
QueueDemo.printQ(priorityQueue);
String fact = "EDUCATIONSHOULDESCHEWOBFUSCATION";
List<String> strings = Arrays.asList(fact.split(""));
PriorityQueue<String> stringPQ = new PriorityQueue<>(strings);
QueueDemo.printQ(stringPQ);
stringPQ = new PriorityQueue<>(strings.size(),Collections.reverseOrder());
stringPQ.addAll(strings);
QueueDemo.printQ(stringPQ);
Set<Character> charSet = new HashSet<>();
for (char c : fact.toCharArray()) {
charSet.add(c);
}
PriorityQueue<Character> characterPQ = new PriorityQueue<>(charSet);
QueueDemo.printQ(characterPQ);
}
}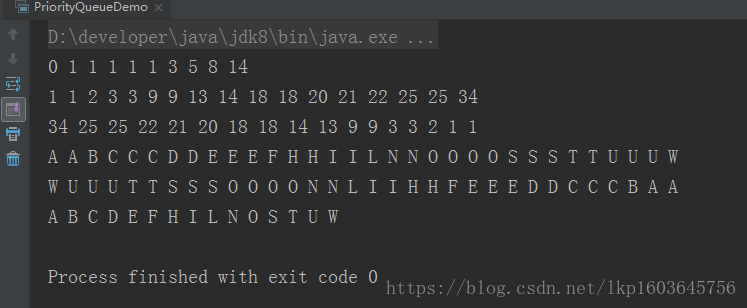
重复是允许的,最小的值拥有最高的优先级(如果是String,空格也可以算作值,并且比字母的优先级高)。
11.12 Collection和Iterator
Collection是描述所有序列容器的共性的根接口,它可能会被认为是一个“附属接口”,即因为要表示若干个接口的共性而出现的接口。另外,java.util.AbstractCollection类提供了Collection的默认实现,使得你可以创建AbstractCollection的子类型,而其中没有不必要的代码重复。
11.13 Foreach与迭代器
到目前为为止,foreach语法主要用于数组,但是它也可以应用于任何Collection对象。
11.14 总结
Java提供了大量持有对象的方式:
1) 数组将数字与对象联系起来。它保存类型明确的对象,查询对象时,不需要对结果做类型转换。它可以是多维的,可以保存基本数据类型的数据。但是,数组一旦生成,其容量就不能改变。
2)Collection保存单一的元素,而Map保存相关联的键值对。有了Java的泛型,你就可以指定容器中存放的对象类型,因此你就不会将错误类型的对象放置到容器中,并且在从容器中获取元素时,不必进行类型转换。各种Collection和各种Map都可以在你向其中添加更多的元素时,自动调整其尺寸。容器不能持有基本类型,但是自动包装机制会仔细地执行基本类型到容器中所持有的包装器类型之间的双向转换。
3)像数组一样,List也建立数字索引与对象的关联,因此,数组和List都是排好序的容器。List能够自动扩充容量。
4)如果要进行大量的随机访问,就是用ArrayList;如果要经常从表中间插入或删除元素,则应该使用LinkedList。
5)各种Queue以及栈的行为,由LinkedList提供支持。
6)Map是一种将对象(而非数字)与对象相关联的设计。HashMap设计用来快速访问;而TreeMap保持“键”始终处于排序状态,所以没有HashMap快。LinkedHashMap保持元素插入的顺序,但是也通过散列体用了快速访问能力。
7)Set不接受重复元素。HashSet提供最快的查询速度,而TreeSet保持元素处于排序状态。LinkedHashSet以插入顺序保存元素。
8)新程序中不应该使用过时的Vector、HashSet和Statck。