由于最近在工作中刚接触到scala和Spark,并且作为python中毒者,爬行过程很是艰难,所以这一系列分为几个部分记录下学习《Spark快速大数据分析》的知识点以及自己在工程中遇到的小问题,以下阶段也是我循序了解Spark的一个历程。
先抛出几个问题:
- 什么是Spark?
- Spark内部是怎么实现集群调度的?
- 如何调用Saprk?
- Spark支持的数据集,以及常用的操作有哪些?
- 容易踩到哪些坑?
一、Spark简介
1、Spark是什么
Spark是一个用来实现快速而通用的集群计算平台。它一个主要特点是能够在内存中进行计算,并且提供了基于Python、Java、Scala和SQL的API,可以和其他大数据工具配合使用。由于Spark的核心引擎有着速度快和通用的特点,因此它还支持各种不同应用场景专门设计的高级组件,比如SQL和机器学习等。组件其实可以理解为Spark针对常见的任务场景而封装好的模块,这些模块提供了各场景的基本功能。组件之间可以相互调用,各组件如图1-1:
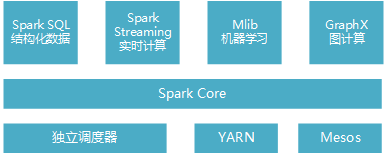
图1-1 Spark软件栈
- Spark Core实现了任务调度、内存管理、错误恢复、与存储系统交互等模块,并且还包含了对弹性分布式数据集(Resilient Distributed Dataset,简称RDD)的API定义。它主要担任了系统管理员的角色。
- Spark SQL 主要用来操作结构化数据的程序包,通过Spark SQL可以使用SQL或者hive版本的HQL来查询数据库。
- Spark Streaming 主要是对实时数据进行流式计算。
- MLib提供了很多机器学习算法。
- GraphX用来操作图,可以并行的进行图计算,支持了图的各种操作。
其中,Spark SQL组件是经常用到的,使用hql语句从hadoop数仓中读取结构化的数据,存为RDD数据集,进行一些操作后分布式存储到hdfs中。
2、Spark核心概念
分布式环境下,Spark集群采用主/从结构。有一个驱动器(Driver)节点负责中央协调,调度各个分布式工作节点,这里的工作节点也叫作执行器(executor)节点。驱动器节点可以和大量的执行器节点通信,这些节点一起被称为一个Spark应用。
Spark应用主要是由一个驱动器节点的程序来发起集群上的各种并行操作,驱动器程序也就是你写的代码,包含了应用的main函数,定义了分布式数据集以及进行相关操作。那这个程序哪里体现出能够操作集群的功能呢?主要通过实例化一个SparkContext 对象来访问Spark,这个对象可以用来连接计算集群。在shell交互式环境下,会自动创建这个对象,叫做sc的变量。否则,需要自己定义。如下代码展示了如何查看交互式shell环境下sc的类型。


下图1-2展示了Spark如何在一个集群上运行。
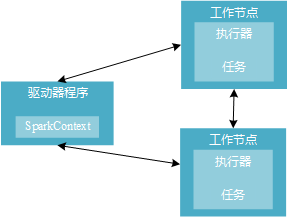
图1-2 Spark分布式组件
驱动器节点的任务:
(1)把用户程序转为任务
隐式地创建一个由操作组成的逻辑上的有向无环图,当驱动程序运行时,会把这个逻辑图转为物理执行计划。
(2)为执行器节点调度任务
执行器进程启动后,会向驱动器进程注册自己。驱动器程序会根据当前执行器节点集合,把所有任务基于数据所在位置分配给合适的执行器进程。当任务执行时,执行器进程把缓存数据存储,驱动器进程会跟踪这些缓存数据的位置,并利用这些信息调度以后的任务。
执行器节点的任务:
(1)负责运行组成Spark应用的任务,并将结果返回给驱动器进程。
(2)通过自身的块管理器为用户程序中要求缓存的RDD提供内存式存储。
3、调用Spark
(1)spark-shell(交互窗口模式: 逐行敲模式)
运行spark-shell需要指向申请资源的standalone spark集群信息,其参数为MASTER,还可以指定executor及driver的内存大小。
yarn模式:
1 sudo spark-shell --executor-memory 5g --driver-memory 1g --master yarn
local模式:
1 sudo spark-shell --executor-memory 5g --driver-memory 1g --master local
spark-shell已经默认生成sc对象,可以用如下代码读取数据资源。
1 val user_rdd1 = sc.textFile(inputpath, 10)
(2)spark-shell(脚本运行模式:批量运行模式--适用大部分线下需求)
上面方法需要在交互窗口中一条一条的输入scala程序;如果想把scala程序保存在test.scala文件中,一次运行该文件中的程序代码,可通过如下方式:
1 sudo spark-shell --executor-memory 5g --driver-memory 1g --master yarn < test.scala
1 sudo spark-shell --executor-memory 5g --driver-memory 1g --master local < HelloWorld.scala
local 模式在本地运行,可加载本地文件。
(3)spark-submit (程序部署模式:与shell无关模式--适用线上需要执行的例行流程)
Spark提供了一个容易上手的应用程序部署工具bin/spark-submit,可以完成Spark应用程序在local、Standalone、YARN、Mesos上的快捷部署。可以指定集群资源master,executor/ driver的内存资源等。
1 sudo spark-submit --masterspark://192.168.180.216:7077 --executor-memory 5g --class mypackage.test workcount.jar hdfs://192.168.180.79:9000/user/input.txt
workcount .scala 代码打包workcount.jar,并将文件需要上传到spark的安装目录下面; hdfs://192.168.180.79:9000/user/input.txt为输入参数;