版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/wwlhz/article/details/79403785
在处理国际化时,处理不当就会产生乱码,通用的做法是都转换为UTF-8编码,对于高层开发语言十分简单,对于底层编程语言则有些复杂。其中涉及的概念也有很多。
字符是指计算机中使用的字母、数字、字和符号,包括:1、2、3、A、B、C、~!·#¥%……—*()——+等等。在 ASCII 编码中,一个英文字母字符存储需要1个字节。在 GB 2312 编码或 GBK 编码中,一个汉字字符存储需要2个字节。在UTF-8编码中,一个英文字母字符存储需要1个字节,一个汉字字符储存需要3到4个字节。在UTF-16编码中,一个英文字母字符或一个汉字字符存储都需要2个字节(Unicode扩展区的一些汉字存储需要4个字节)。在UTF-32编码中,世界上任何字符的存储都需要4个字节。
- ASCII 字符
- Unicode 字符
宽字符
- 用多个字节来代表的字符称之为宽字符,而Unicode只是宽字符编码的一种实现,宽字符并不一定是Unicode。
- 宽字符字符串表示为一个 wchar_t[] 数组。可以通过用字母 L 作为字符的前缀将任何 ASCII 字符表示为宽字符形式。例如,L’\0’ 是宽终止NULL 字符。同样,可以通过用字母 L 作为 ASCII 字符串的前缀 (L”Hello”) 将任何 ASCII 字符串表示为宽字符字符串形式。
- wchar_t的宽度属于编译器的特性。对于Windows是16位宽;类Unix系统中,默认是32位宽。
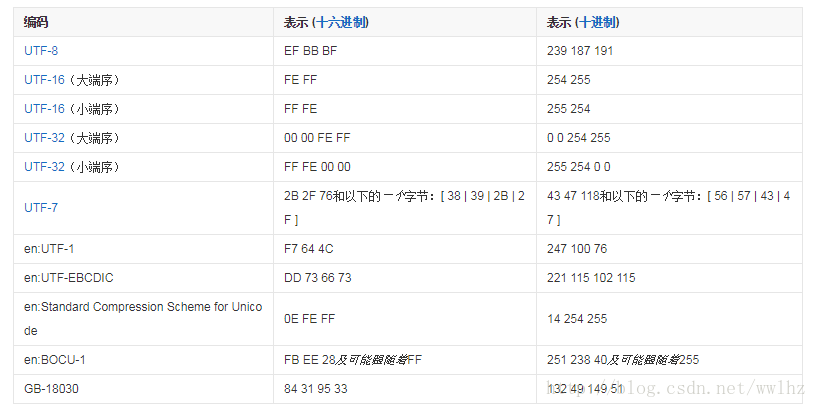
字节顺序
字节顺序涉及到字节的大小端,一个文件会在前面加上一个字符用来表明该文件采用的是大端还是小端。这个字符的名字叫做”零宽度非换行空格”(zero width no-break space),用FEFF表示。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大端方式;如果头两个字节是FF FE,就表示该文件采用小端方式。
“零宽度非换行空格” 又叫 BOM(Byte Order Mark),不同的编码方式,会有不同的BOM格式。
参考: