刚刚结束了京东的笔试,发现很多知识点都不太了解,所以在这篇文章做一个汇总学习。
目录

1 哈夫曼树
给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
参考百度百科
题目考察的要点是如何计算哈夫曼树的带权路径长度。
(参考文章:https://blog.csdn.net/u013011841/article/details/38226099)
1)路径长度:一个结点到另一个结点的分支数目。如下图所示(根节点到D之间的路径长度为4):
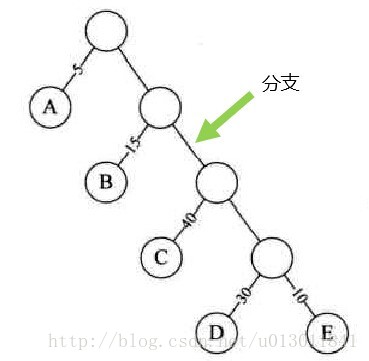
2)树的路径长度:根节点到每一个结点的路径长度之和。如下图所示(树的路径长度为1+2+3+4+1+2+3+4 = 20):
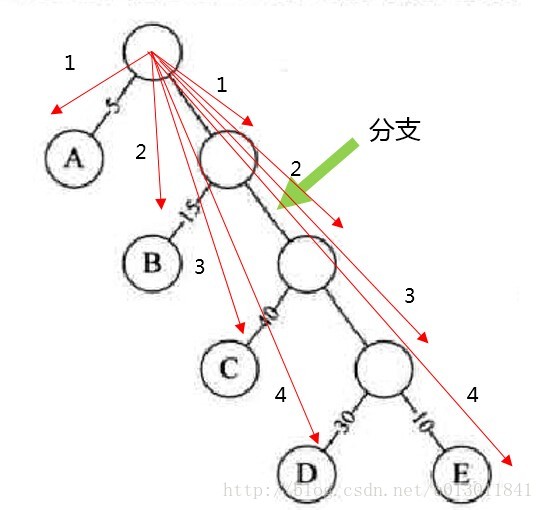
3)带权路径长度:上图所示的例子中,带权路径的长度为5*1+15*2+40*3+30*4+10*4=315
4)哈夫曼树:带权路径长度最小的二叉树。
5)构造哈夫曼树
1、根据给定的n个权值{w[1],w[2],…,w[n]}构成n棵二叉树的集合F={T[1],T[2],…T[n]},其中每棵二叉树T[i];中只有一个带权为w[i]的根结点,其左右子树均为空。
2、在F中选取两棵根结点的权值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根结点的权值为其左右子树上根结点的权值之和。
3、在F中删除这两棵树,同时将新得到的二义树加入F中。
4重复2和3步骤,直到F只含一棵树为止。这棵树便是哈夫曼树。
用画图表示上面的步骤:
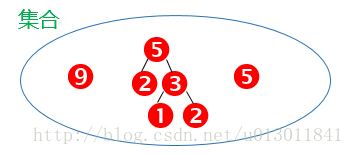
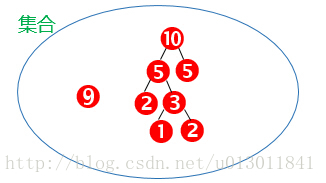
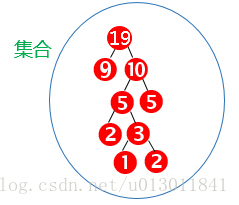
结果为:
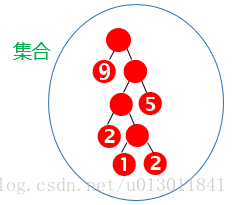
2 循环链表
参考内容为维基百科。
链表的种类包括:
1)单向链表:(又名单链表、线性链表)是链表的一种,其特点是链表的链接方向是单向的,对链表的访问要通过从头部开始,依序往下读取。

它的结构可以分为数据域和指针域,数据域存储数据,指针域指向下一个储存节点的地址。
2)双向链表:也叫双链表,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。
3)循环链表:一种链式存储结构,它的最后一个结点指向头结点,形成一个环。因此,从循环链表中的任何一个结点出发都能找到任何其他结点。
更详细的线性表(顺序存储+链式存储结构)可以参考这篇文章,此处不再赘述。
3 堆
3.1 大顶堆、小顶堆
(参考文章为http://bubkoo.com/2014/01/14/sort-algorithm/heap-sort/
https://www.cnblogs.com/dolphin0520/archive/2011/10/06/2199741.html)
堆可以看做一个满足特殊条件的完全二叉树。它满足双亲结点大于等于孩子结点(大顶堆),或者双亲结点小于等于孩子结点(小顶堆)。
- 父节点i的左子节点在位置
;
- 父节点i的右子节点在位置
;
- 子节点i的父节点在位置
;

二叉树的相关内容可以参考这篇文章,此处不再赘述。
3.2 堆排序
大顶堆产生顺序序列,小顶堆产生生逆序序列。此处以大顶堆为例进行说明。
1)将初始待排序关键字序列(R[1],R[2]....R[n])构建成大顶堆,此堆为初始的无序区;
2)将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R[1],R[2],......R[n-1])和新的有序区(R[n]),且满足R[1,2...n-1]<=R[n];
3)由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R[1],R[2],......R[n-1])调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R[1],R[2]....R[n-2])和新的有序区(R[n-1],R[n])。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
接下来以数组{16,7,3,20,17,8}为例,解释上面的步骤:
①由无序数组创建与其等价的完全二叉树

②构造初始堆(每次调整都是从父节点、左子节点、右子节点三者中选择最大者跟父节点进行交换)

此时由于16与20的交换,我们需要继续比较、交换16及其子节点,然后得到初始堆:

③构建无序区和有序区
初始堆的R[1]一定是最大的,所以我们首先把它和最后一位R[n-1]交换。此时无序区为R[1, 2…n-1],有序区为R[n]:

此时3(父节点)不再是父节点、左子节点、右子节点中最大的了,所以3和17交换:


此时3作为父节点还是比它的子节点要小,我们进一步让它与16交换:

然后我们就可以让17与3交换,使得17进入有序区:

接下来就是不断重复③中的上述步骤,使得无序区结点不断减少,有序区则不断增加,直到有序区有n-1个结点:


最后一次交换后,排序结束:

3.3 堆排序时间复杂度分析
为了从R[1...n]中选择最大记录,需比较n-1次,然后从R[1...n-2]中选择最大记录需比较n-2次。事实上这n-2次比较中有很多已经在前面的n-1次比较中已经做过,而树形选择排序恰好利用树形的特点保存了部分前面的比较结果,因此可以减少比较次数。对于n个关键字序列,最坏情况下每个节点需比较log2(n)次,因此其最坏情况下时间复杂度为nlogn。堆排序为不稳定排序,不适合记录较少的排序。
4 唯一确定二叉树
京东的原题有点类似牛客网上的这道题:

答案选AC,原因是:
前序(先序):根左右
中序: 左根右
后序: 左右根
一定要有中序,这样才能区分左右子树,否则得到的是左右子树的混合。
5 SQL绑定变量
6 递归和递推的区别
从理论上说,所有的递归函数都可以转换为迭代函数,反之亦然,然而代价通常都是比较高的。当递归次数较多时,内存占用也会随之增加。
递推与递归:
1,从程序上看,递归表现为自己调用自己,递推则没有这样的形式。
2,递归是从问题的最终目标出发,逐渐将复杂问题化为简单问题,最终求得问题
是逆向的。递推是从简单问题出发,一步步的向前发展,最终求得问题。是正向的。
3,递归中,问题的n要求是计算之前就知道的,而递推可以在计算中确定,不要求计算前就知道n。
4,一般来说,递推的效率高于递归(当然是递推可以计算的情况下)
作者:kickers18
链接:https://www.zhihu.com/question/20651054/answer/260181892
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
7 Python中range&xrange的区别
xrange用法与range完全相同,所不同的是生成的不是一个数组,而是一个生成器。
要生成很大的数字序列的时候,用xrange会比range性能优很多,因为不需要一上来就开辟一块很大的内存空间。
8 隐含狄利克雷分布(LDA)
参考维基百科LDA词条。