深度学习框架概述
author: jason_ql
Blog: https://blog.csdn.net/lql0716
1、引言
- Machine learning = looking for a Function
机器学习,其实就是寻找一个能够描述整个数据集状态的函数,这个函数可以是线性,也可以是非线性
1.1 应用领域
语音识别(speech recognition)
图片识别(image recognition)
围棋(playing go)
问答系统(dialogue system)




1.2 图片识别框架
A set of function Model:
流程
如下图所示,训练出一些函数之后,筛选出效果较好的函数作为训练之后的最终模型,利用模型对输入的图片进行处理判断识别
训练与测试的流程图
由以上流程可以发现,深度学习可以分为三步,如下图
其中第一步定义函数的过程即为定义一个神经网络(如下图)
这就类比于人类的大脑的神经网络(如下图)





1.3 神经网络(neural network)
1.3.1 神经元(neuron)
- 数据:
- 权重参数:
- 偏差(bias):
- 函数:
- 激活函数:
- 参数:

其中激活函数为 S 型函数,其曲线如下图
常用的激活函数有:


1.3.2 神经网络
- 将神经元连接起来,就组成了一个神经网络结构,不同的神经元可以有不同的数值,网络结构图如下

1.3.3 全连接前馈神经网络(full connect feedforward network)
全连接前馈神经网络示例
图1
图2
图3
如上图所示,如果输入数据 ,则神经网络会输出全连接神经网络结构示意图
其中 Layer 1表示全连接第一层,这里一共有 L 层输出层(output layer)
如上图,即选择 最大的对于神经网络的层次L、偏差 b 确定,一般是根据经验来确定的





1.3.4 应用示例
- 手写数字识别
- 训练识别图片中的数字2



1.4 goodness of function
训练集与对应的标签
训练的最终目标如下图
损失函数(训练好的模型应该使得损失函数值达到最小)




1.5 pick the best function
- 如何找到参数
使得损失函数
最小化?

1.5.2 梯度下降法(Gradient Descent)
初始化权重
计算损失函数对权重的梯度
添加学习率系数 (即梯度下降的步长)
下降到梯度接近于0即可停止
梯度下降示例
但是,梯度下降并不能保证全局最优









1.5.2.1 梯度下降法的示例解释
- 假如对于游戏中的地图


1.5.2.2 反向传播(Backpropagation)计算梯度
- 利用反向传播来高效的计算梯度

1.6 网络的深度层次是不是越大越好?
深度对错误率的影响(Thin型网络)
Fat 型网络(即深度小,单层的参数足够多)
“Thin” 与 “Fat” 型网络哪一种好?




神经网络与逻辑电路的类比
深度就相当于将目标模块儿化






1.7 深度学习框架 Keras
keras
keras 文档及示例


1.7.1 应用示例(手写字体识别)
- 手写字体识别






2、神经网络的训练方法
训练流程图
不要总归咎于过拟合,也可能是其他原因
调参过程



2.1 选择合适的损失函数
- 选择合适的损失函数


- 精确度(accuracy)对比


- 常见的损失函数

2.2 Mini-batch 小批量的更新参数

- epoch 与 batch
- epoch
当一个完整的数据集 通过了神经网络一次并且返回了一次,这个过程称为一个 epoch - batch
当一个 epoch 对于计算机而言太庞大的时候,就需要把它分成 个小块( 个子集 ),一个小块 就是一个batch,一个batch通过神经网络一次就是一个epoch,那么全部数据 要通过神经网络一次,那就需要迭代 次才能使得这 个 batch 全部通过神经网络一次,也就是需要经过 个 epoch
- 例子
比如对于一个有 2000 个训练样本的数据集。将 2000 个样本分成大小为 500 的 batch,那么完成一个 epoch 需要 4 个 iteration。
- epoch


- 为什么不真正的进行最小化损失函数?





2.3 新的激活函数






ReLU
改进的ReLU
ReLU是Maxout的一种特殊情况,Max网络中的激活函数可以是任何分段线性凸函数








2.4 自适应学习率(Adaptive learning rate)

一定要注意学习率的设置,如果过大,容易导致损失函数向增大的方向发展,如果过小,则会训练的比较慢
在训练刚开始的时候,使用较大的学习率,当进行epchs一段时间之后,将学习率逐渐调小







2.6 Momentum(动量)

在平稳的位置、鞍点、局部极小的位置很难找到最优的网络参数
利用物理中的动量来优化梯度




2.7 Early Stopping

- 过拟合的原因





2.8 权重衰退(weight decay)
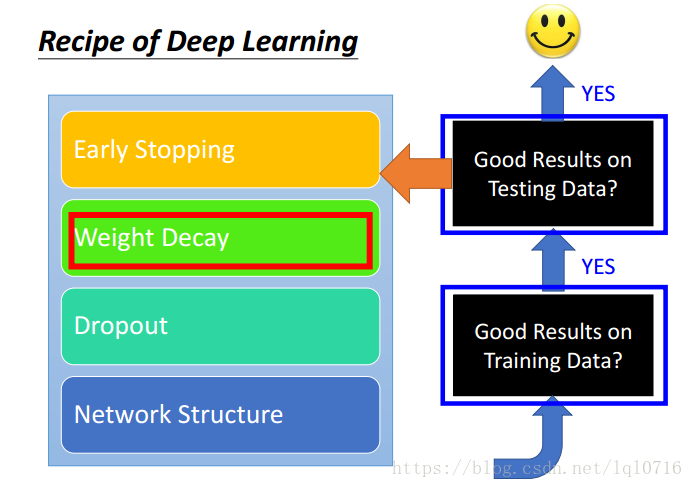- 我们的大脑可以筛出无用的神经元,同样的,对机器学习也这样做



2.9 Dropout(清理掉无用的神经元)
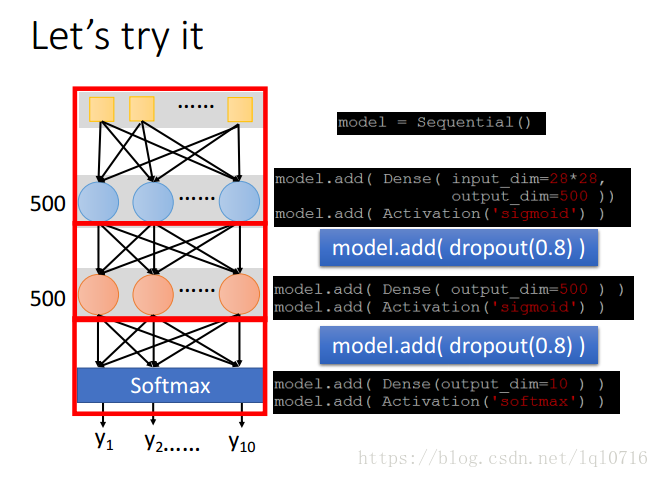
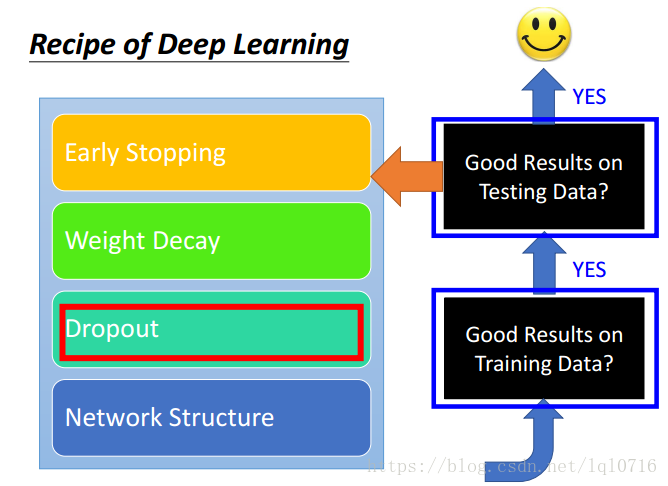每次在更新参数之前,神经元有 的概率会被抛弃
去掉无用的神经元之后,会产生一个新的神经网络,利用新的神经网络继续训练
参数的调整




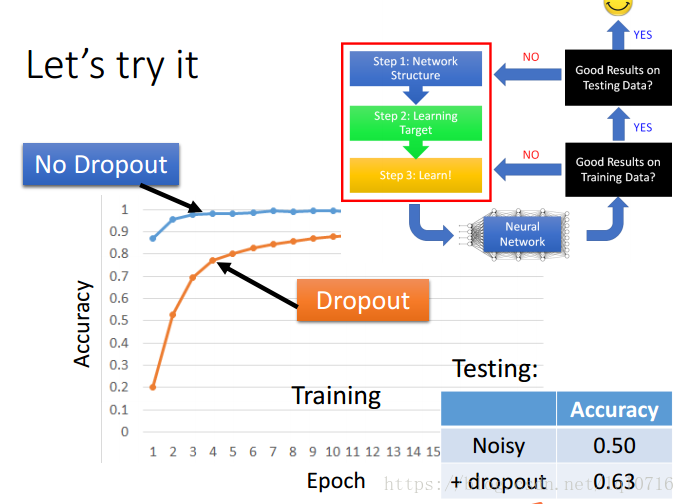
- dropout在训练集与测试集直接的关系

 
2.10 网络结构(network structure)
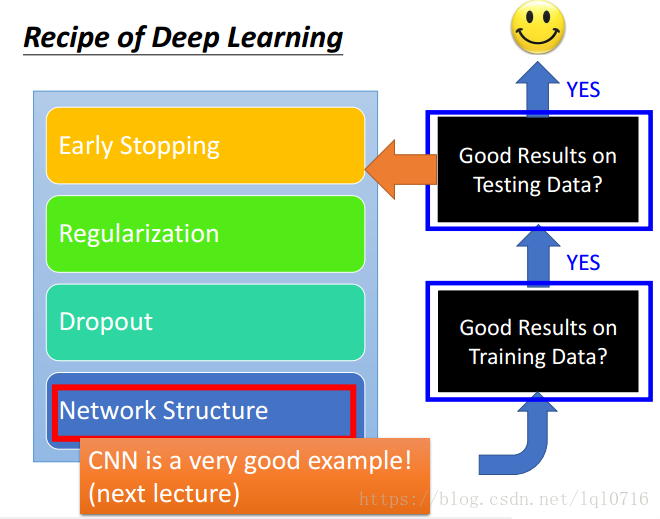- 文档分类示例






3、改进的神经网络
3.1 CNN (卷积神经网络,Convolutional Neural network)
为何要用CNN,全连接网络过于庞大
相似的区域可以共享参数
缩放图片可以减少参数量
CNN也可分为如下三步
CNN流程图








3.1.1 CNN卷积

滤波器移动的步长为1
滤波器移动的步长为2
卷积后,会出现相似的区域
对滤波器2也做同样的操作
边界填充0
对彩色图像在三个通道分别做同样的滤波操作






3.1.2 CNN pooling (池化)

- max poolling


- 卷积池化之后生成一个新的图像


3.1.3 flatten
- 矩阵向量化,作为训练数据传入网络进行训练




- 共享权重




3.1.4 goodness of function

- 可以用全连接网络来训练围棋,但是使用CNN效果会更好




3.2 RNN(循环神经网络,Recurrent Neural Network)





3.2.1 双向(Bidirectional)RNN

3.3 LSTM(Long Short-term Memory )网络








4、其他网络简介
- 监督学习(supervised learning)
Ultra deep network, attention model 强化学习(reinforcement learning)
无监督学习(unsupervised learning)





参考资料
- deep learning tutorial (李宏毅)