版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/baidu_27643275/article/details/81987155
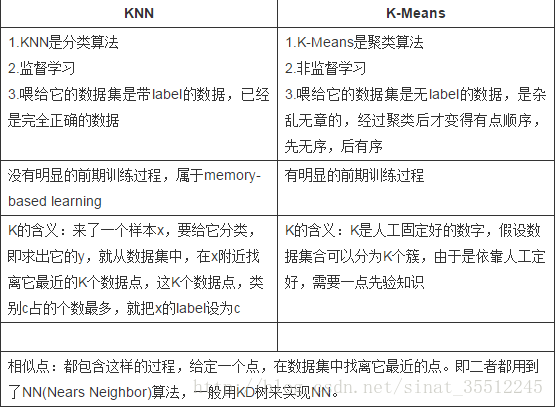
(摘自参考链接1)
k_means算法流程:
(1)随机选择K个点作为每个类的初始质心;
(2)在数据集中选择一个样本,计算其与每个类质心的距离,然后将该样本归到距离最短的那个中心所在的类。 重复此操作,直到所有样本全部归好类;
(3)利用均值等方法更新各个类的质心;
(4)重复(2)(3)步,直到某次的质心与上一次迭代的质心重合为止。
python实现:
python sklearn:
from sklearn import datasets
from sklearn.cluster import KMeans
iris = datasets.load_iris()
print(dir(iris))
print(iris.target)
model = KMeans(n_clusters=3)
model.fit(iris.data)
all_preditions = model.predict(iris.data)
print(all_preditions)
#效果好差啊KNN算法流程:
(1)计算测试数据与各个训练数据之间的距离;
(2)按照距离的递增关系进行排序;
(3)选取距离最小的K个点;
(4)确定前K个点所在类别的出现频率;
(5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
python实现: