前言
Http 缓存机制作为 web 性能优化的重要手段,对于从事 Web 开发的同学们来说,应该是知识体系库中的一个基础环节,同时对于有志成为前端架构师的同学来说是必备的知识技能。
但是对于很多前端同学来说,仅仅只是知道浏览器会对请求的静态文件进行缓存,但是为什么被缓存,缓存是怎样生效的,却并不是很清楚。
在此,我会尝试用简单明了的文字,像大家系统的介绍HTTP缓存机制,期望对各位正确的理解前端缓存有所帮助。
在介绍HTTP缓存之前,作为知识铺垫,先简单介绍一下HTTP报文
HTTP报文就是浏览器和服务器间通信时发送及响应的数据块。
浏览器向服务器请求数据,发送请求(request)报文;服务器向浏览器返回数据,返回响应(response)报文。
报文信息主要分为两部分
1.包含属性的首部(header)--------------------------附加信息(cookie,缓存信息等)与缓存相关的规则信息,均包含在header中
2.包含数据的主体部分(body)-----------------------HTTP请求真正想要传输的部分
http报文中与缓存相关的首部字段
我们先来瞅一眼RFC2616规定的47种http报文首部字段中与缓存相关的字段,事先了解一下能让咱在心里有个底:
1. 通用首部字段(就是请求报文和响应报文都能用上的字段)

2. 请求首部字段

3. 响应首部字段

4. 实体首部字段

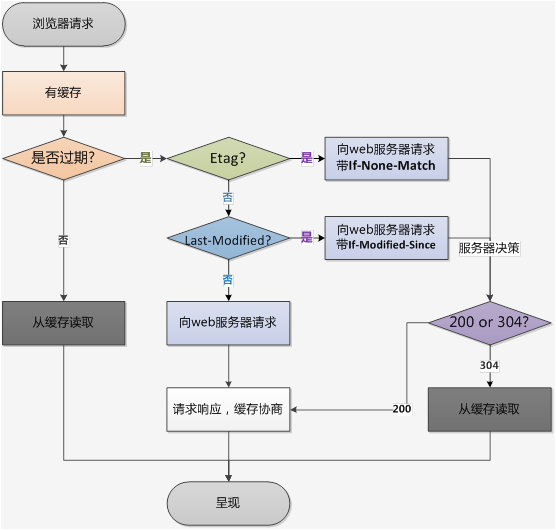
缓存规则解析
为方便大家理解,我们认为浏览器存在一个缓存数据库,用于存储缓存信息。
在客户端第一次请求数据时,此时缓存数据库中没有对应的缓存数据,需要请求服务器,服务器返回后,将数据存储至缓存数据库中。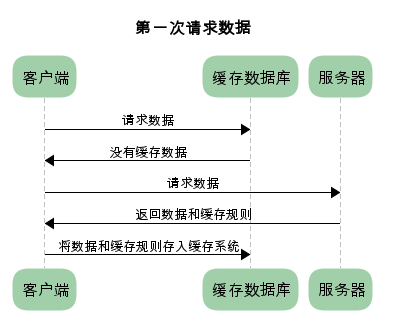
HTTP缓存有多种规则,根据是否需要重新向服务器发起请求来分类,我将其分为两大类(强制缓存,对比缓存)
在详细介绍这两种规则之前,先通过时序图的方式,让大家对这两种规则有个简单了解。
已存在缓存数据时,仅基于强制缓存,请求数据的流程如下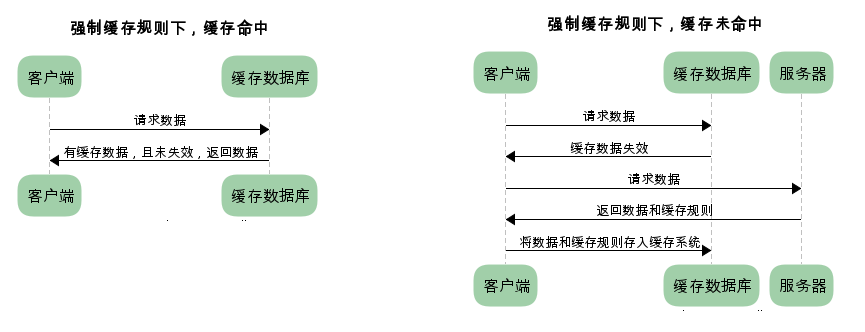
已存在缓存数据时,仅基于对比缓存,请求数据的流程如下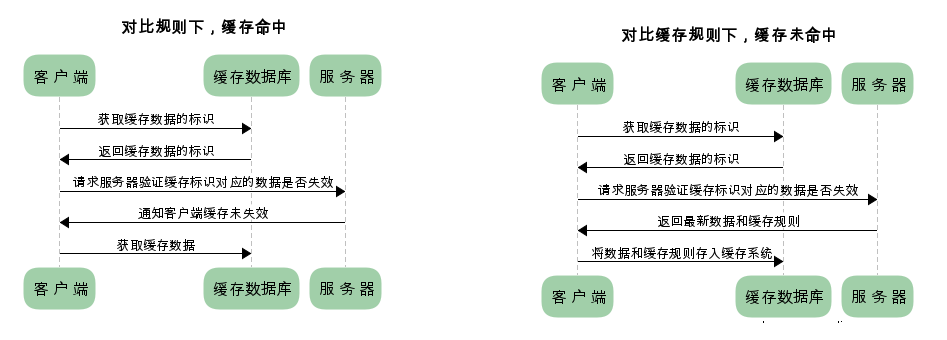
对缓存机制不太了解的同学可能会问,基于对比缓存的流程下,不管是否使用缓存,都需要向服务器发送请求,那么还用缓存干什么?
这个问题,我们暂且放下,后文在详细介绍每种缓存规则的时候,会带给大家答案。
我们可以看到两类缓存规则的不同,强制缓存如果生效,不需要再和服务器发生交互,而对比缓存不管是否生效,都需要与服务端发生交互。
两类缓存规则可以同时存在,强制缓存优先级高于对比缓存,也就是说,当执行强制缓存的规则时,如果缓存生效,直接使用缓存,不再执行对比缓存规则。
强制缓存
从上文我们得知,强制缓存,在缓存数据未失效的情况下,可以直接使用缓存数据,那么浏览器是如何判断缓存数据是否失效呢?
我们知道,在没有缓存数据的时候,浏览器向服务器请求数据时,服务器会将数据和缓存规则一并返回,缓存规则信息包含在响应header中。
对于强制缓存来说,响应header中会有两个字段来标明失效规则(Expires/Cache-Control)
使用chrome的开发者工具,可以很明显的看到对于强制缓存生效时,网络请求的情况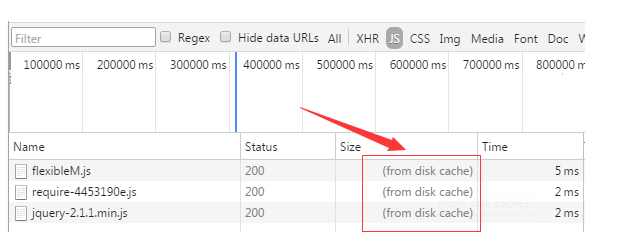
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
在 http1.0 时代,给客户端设定缓存方式可通过两个字段——“Pragma”和“Expires”来规范。虽然这两个字段早可抛弃,但为了做http协议的向下兼容,你还是可以看到很多网站依旧会带上这两个字段。
Pragma
当该字段值为“no-cache”的时候(事实上现在RFC中也仅标明该可选值),会知会客户端不要对该资源读缓存,即每次都得向服务器发一次请求才行。
Pragma属于通用首部字段,在客户端上使用时,常规要求我们往html上加上这段meta元标签(而且可能还得做些hack放到body后面去):
<meta http-equiv="Pragma" content="no-cache">
它告诉浏览器每次请求页面时都不要读缓存,都得往服务器发一次请求才行。
BUT!!! 事实上这种禁用缓存的形式用处很有限:
1. 仅有IE才能识别这段meta标签含义,其它主流浏览器仅能识别“Cache-Control: no-store”的meta标签(见出处)。
2. 在IE中识别到该meta标签含义,并不一定会在请求字段加上Pragma,但的确会让当前页面每次都发新请求(仅限页面,页面上的资源则不受影响)。
做了测试后发现也的确如此,这种客户端定义Pragma的形式基本没起到多少作用。
不过如果是在响应报文上加上该字段就不一样了:

如上图红框部分是再次刷新页面时生成的请求,这说明禁用缓存生效,预计浏览器在收到服务器的Pragma字段后会对资源进行标记,禁用其缓存行为,进而后续每次刷新页面均能重新发出请求而不走缓存。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Expires
Expires的值为服务端返回的到期时间,即下一次请求时,请求时间小于服务端返回的到期时间,直接使用缓存数据。
不过Expires 是HTTP 1.0的东西,现在默认浏览器均默认使用HTTP 1.1,所以它的作用基本忽略。
Expires的值对应一个GMT(格林尼治时间),比如“Mon, 22 Jul 2002 11:12:01 GMT”来告诉浏览器资源缓存过期时间,如果还没过该时间点则不发请求。
在客户端我们同样可以使用meta标签来知会IE(也仅有IE能识别)页面(同样也只对页面有效,对页面上的资源无效)缓存时间:
<meta http-equiv="expires" content="mon, 18 apr 2016 14:30:00 GMT">
如果希望在IE下页面不走缓存,希望每次刷新页面都能发新请求,那么可以把“content”里的值写为“-1”或“0”。
注意的是该方式仅仅作为知会IE缓存时间的标记,你并不能在请求或响应报文中找到Expires字段。
如果是在服务端报头返回Expires字段,则在任何浏览器中都能正确设置资源缓存的时间:

在上图里,缓存时间设置为一个已过期的时间点(见红框),则刷新页面将重新发送请求(见蓝框)。
那么如果Pragma和Expires一起上阵的话,听谁的?我们试一试就知道了:

我们通过Pragma禁用缓存,又给Expires定义一个还未到期的时间(红框),刷新页面时发现均发起了新请求(蓝框),这意味着Pragma字段的优先级会更高。
BUT,响应报文中Expires所定义的缓存时间是相对服务器上的时间而言的,如果客户端上的时间跟服务器上的时间不一致(特别是用户修改了自己电脑的系统时间),那缓存时间可能就没啥意义了(到期时间是由服务端生成的,但是客户端时间可能跟服务端时间有误差,这就会导致缓存命中的误差)。
所以HTTP 1.1 的版本,使用Cache-Control替代。
Cache-Control
针对上述的“Expires时间是相对服务器而言,无法保证和客户端时间统一”的问题,http1.1新增了 Cache-Control 来定义缓存过期时间,若报文中同时出现了 Pragma、Expires 和 Cache-Control,会以 Cache-Control 为准。
Cache-Control也是一个通用首部字段,这意味着它能分别在请求报文和响应报文中使用。在RFC中规范了 Cache-Control 的格式为:
"Cache-Control" ":" cache-directive
作为请求首部时,cache-directive 的可选值有:
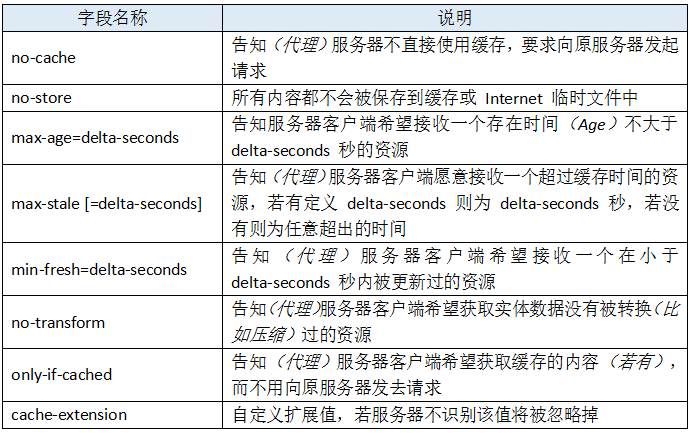
作为响应首部时,cache-directive 的可选值有:
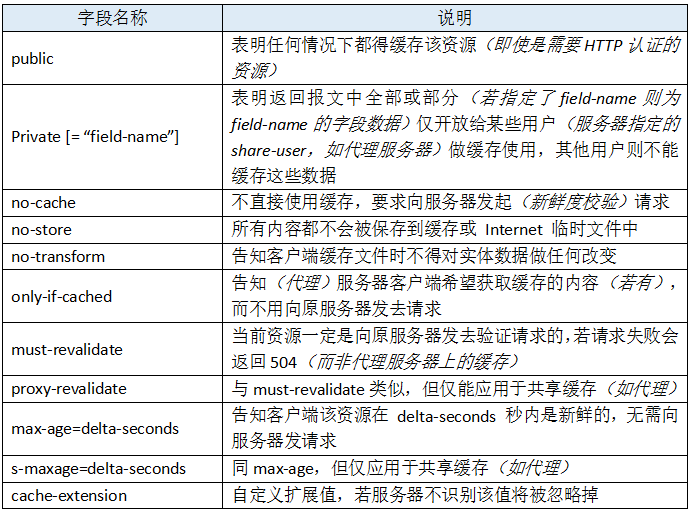
我们依旧可以在HTML页面加上meta标签来给请求报头加上 Cache-Control 字段:
另外 Cache-Control 允许自由组合可选值,例如:
Cache-Control: max-age=3600, must-revalidate
它意味着该资源是从原服务器上取得的,且其缓存(新鲜度)的有效时间为一小时,在后续一小时内,用户重新访问该资源则无须发送请求。
当然这种组合的方式也会有些限制,比如 no-cache 就不能和 max-age、min-fresh、max-stale 一起搭配使用。
组合的形式还能做一些浏览器行为不一致的兼容处理。例如在IE我们可以使用 no-cache 来防止点击“后退”按钮时页面资源从缓存加载,但在 Firefox 中,需要使用 no-store 才能防止历史回退时浏览器不从缓存中去读取数据,故我们在响应报头加上如下组合值即可做兼容处理:
Cache-Control: no-cache, no-store
Cache-Control 是最重要的规则。常见的取值有private、public、no-cache、max-age,no-store,默认为private。
private: 客户端可以缓存
public: 客户端和代理服务器都可缓存(前端的同学,可以认为public和private是一样的)
max-age=xxx: 缓存的内容将在 xxx 秒后失效
no-cache: 需要使用对比缓存来验证缓存数据(后面介绍)
no-store: 所有内容都不会缓存,强制缓存,对比缓存都不会触发(对于前端开发来说,缓存越多越好,so...基本上和它说886)
举个板栗
图中Cache-Control仅指定了max-age,所以默认为private,缓存时间为31536000秒(365天)
也就是说,在365天内再次请求这条数据,都会直接获取缓存数据库中的数据,直接使用。
对比缓存
对比缓存,顾名思义,需要进行比较判断是否可以使用缓存。
浏览器第一次请求数据时,服务器会将缓存标识与数据一起返回给客户端,客户端将二者备份至缓存数据库中。
再次请求数据时,客户端将备份的缓存标识发送给服务器,服务器根据缓存标识进行判断,判断成功后,返回304状态码,通知客户端比较成功,可以使用缓存数据。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
缓存校验字段
上述的首部字段均能让客户端决定是否向服务器发送请求,比如设置的缓存时间未过期,那么自然直接从本地缓存取数据即可(在chrome下表现为200 from cache),若缓存时间过期了或资源不该直接走缓存,则会发请求到服务器去。
我们现在要说的问题是,如果客户端向服务器发了请求,那么是否意味着一定要读取回该资源的整个实体内容呢?
我们试着这么想——客户端上某个资源保存的缓存时间过期了,但这时候其实服务器并没有更新过这个资源,如果这个资源数据量很大,客户端要求服务器再把这个东西重新发一遍过来,是否非常浪费带宽和时间呢?
答案是肯定的,那么是否有办法让服务器知道客户端现在存有的缓存文件,其实跟自己所有的文件是一致的,然后直接告诉客户端说“这东西你直接用缓存里的就可以了,我这边没更新过呢,就不再传一次过去了”。
为了让客户端与服务器之间能实现缓存文件是否更新的验证、提升缓存的复用率,Http1.1新增了几个首部字段来做这件事情:
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
第一次访问:
再次访问:
通过两图的对比,我们可以很清楚的发现,在对比缓存生效时,状态码为304,并且报文大小和请求时间大大减少。
原因是,服务端在进行标识比较后,只返回header部分,通过状态码通知客户端使用缓存,不再需要将报文主体部分返回给客户端。
对于对比缓存来说,缓存标识的传递是我们着重需要理解的,它在请求header和响应header间进行传递,
一共分为两种标识传递,接下来,我们分开介绍。
1、Last-Modified / If-Modified-Since
Last-Modified:
服务器在响应请求时,告诉浏览器资源的最后修改时间。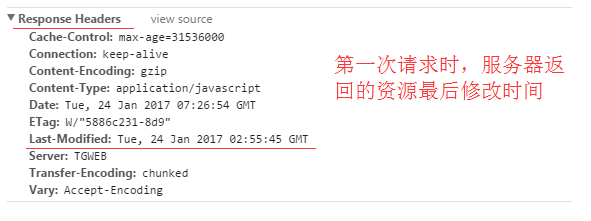
服务器将资源传递给客户端时,会将资源最后更改的时间以“Last-Modified: GMT”的形式加在实体首部上一起返回给客户端。
客户端会为资源标记上该信息,下次再次请求时,会把该信息附带在请求报文中一并带给服务器去做检查,若传递的时间值与服务器上该资源最终修改时间是一致的,则说明该资源没有被修改过,直接返回304状态码即可。
至于传递标记起来的最终修改时间的请求报文首部字段一共有两个:
⑴ If-Modified-Since:Last-Modified-value
再次请求服务器时,通过此字段通知服务器:上次请求时服务器返回的资源最后修改时间。
服务器收到请求后发现有头If-Modified-Since 则与被请求资源的最后修改时间进行比对。
若资源的最后修改时间大于If-Modified-Since,说明资源又被改动过,则响应整片资源内容,返回状态码200;
若资源的最后修改时间小于或等于If-Modified-Since,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。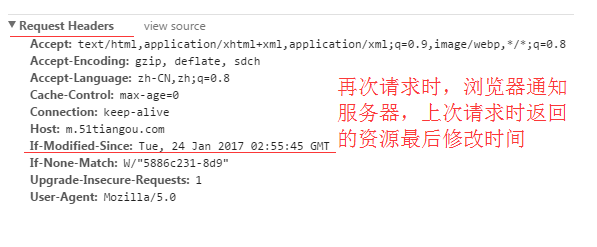
当前各浏览器均是使用的该请求首部来向服务器传递保存的 Last-Modified 值。
⑵ If-Unmodified-Since: Last-Modified-value
告诉服务器,若Last-Modified没有匹配上(资源在服务端的最后更新时间改变了),则应当返回412(Precondition Failed) 状态码给客户端。
当遇到下面情况时,If-Unmodified-Since 字段会被忽略:
1. Last-Modified值对上了(资源在服务端没有新的修改); 2. 服务端需返回2XX和412之外的状态码; 3. 传来的指定日期不合法
Last-Modified 说好却也不是特别好,因为如果在服务器上,一个资源被修改了,但其实际内容根本没发生改变,会因为Last-Modified时间匹配不上而返回了整个实体给客户端(即使客户端缓存里有个一模一样的资源)。
2、Etag / If-None-Match(优先级高于Last-Modified / If-Modified-Since)
Etag:
服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定)。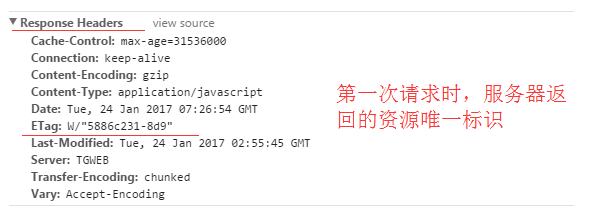
为了解决上述Last-Modified可能存在的不准确的问题,Http1.1还推出了 ETag 实体首部字段。
服务器会通过某种算法,给资源计算得出一个唯一标志符(比如md5标志),在把资源响应给客户端的时候,会在实体首部加上“ETag: 唯一标识符”一起返回给客户端。
客户端会保留该 ETag 字段,并在下一次请求时将其一并带过去给服务器。服务器只需要比较客户端传来的ETag跟自己服务器上该资源的ETag是否一致,就能很好地判断资源相对客户端而言是否被修改过了。
如果服务器发现ETag匹配不上,那么直接以常规GET 200回包形式将新的资源(当然也包括了新的ETag)发给客户端;如果ETag是一致的,则直接返回304知会客户端直接使用本地缓存即可。
那么客户端是如何把标记在资源上的 ETag 传去给服务器的呢?请求报文中有两个首部字段可以带上 ETag 值:
(1) If-None-Match:
再次请求服务器时,通过此字段通知服务器客户段缓存数据的唯一标识。
服务器收到请求后发现有头If-None-Match 则与被请求资源的唯一标识进行比对,
不同,说明资源又被改动过,则响应整片资源内容,返回状态码200;
相同,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。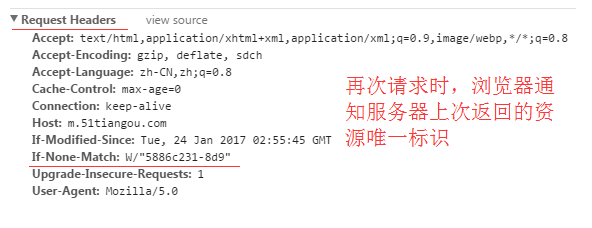
⑵ If-Match: ETag-value
告诉服务器如果没有匹配到ETag,或者收到了“*”值而当前并没有该资源实体,则应当返回412(Precondition Failed) 状态码给客户端。否则服务器直接忽略该字段。
If-Match 的一个应用场景是,客户端走PUT方法向服务端请求上传/更替资源,这时候可以通过 If-Match 传递资源的ETag。
需要注意的是,如果资源是走分布式服务器(比如CDN)存储的情况,需要这些服务器上计算ETag唯一值的算法保持一致,才不会导致明明同一个文件,在服务器A和服务器B上生成的ETag却不一样。
如果 Last-Modified 和 ETag 同时被使用,则要求它们的验证都必须通过才会返回304,若其中某个验证没通过,则服务器会按常规返回资源实体及200状态码。
总结
对于强制缓存,服务器通知浏览器一个缓存时间,在缓存时间内,下次请求,直接用缓存,不在时间内,执行比较缓存策略。
对于比较缓存,将缓存信息中的Etag和Last-Modified通过请求发送给服务器,由服务器校验,返回304状态码时,浏览器直接使用缓存。
浏览器第一次请求: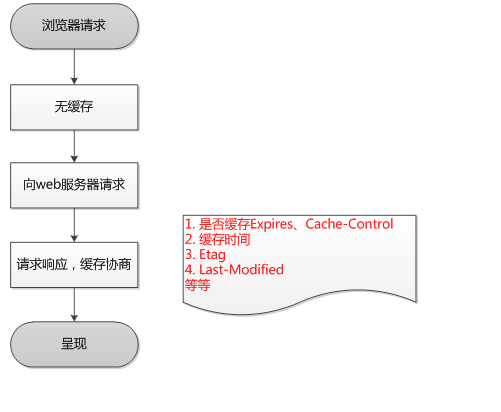
浏览器再次请求时: