java关于并发的总结之一
多线程不一定快
从大多数运行实力来看(这里不做演示),当并发执行的操作累加不超过百万次的时候,速度并不会比串行执行累加操作要快(也就是单线程)。这是因为多线程的创建、线程之间的操作时会有上下文切换的情况,这些情况都会有时间的开销。所以当操作次数不大的时候可以不用考虑多线程。
死锁
private void deadLock(){
Thread t1 = new Thread(new Runnable(){
@Override
public void run(){
synchronized(A){
try{
Thread.currentThread().sleep(2000);
}catch(InterruptedException e){
e.printStackTrace();
}
synchronized(B){
System.out.println("1");
}
}
}
};
Thread t2 = new Thread(new Runnable(){
@Override
public void run(){
synchronized(B){
try{
Thread.currentThread().sleep(1000);
}catch(InterruptedException e){
e.printStackTrace();
}
synchronized(A){
System.out.println("2");
}
}
}
};
}当运行上面的代码之后,我们会发现,t1拿到锁A,之后等待t2释放锁B,t2拿到锁B,等待t1释放锁A,这样就产生了两者都拿不到锁的情况,也就是所谓的死锁。
避免死锁的几个常见方法
+ 避免一个线程同时获取多个锁
+ 避免一个线程在锁内同时占用多个资源,尽量保证每个锁只占用一个资源
+ 尝试使用定时锁,使用lock.tryLock(timeout) 来代替使用内部锁机制
+ 对于数据库锁,加锁和解锁必须在同一个数据库链接里,否则会出现解锁失败的情况
volatile 的应用
首先来看一些CPU术语的定义
| 术语 | 术语描述 |
|---|---|
| 内存屏障 | 是一组处理器指令,用于实现对内存操作的顺序限制 |
| 缓冲行 | CPU告诉缓存中可以分配的最小存储单位。处理器填写缓存行时会夹在整个缓存行,现代CPU需要执行几百次CPU指令 |
| 原子操作 | 不可中断的一个或一系列操作 |
| 缓存行填充 | 当处理器识别到从内存中读取操作数是可缓存的,处理器读取整个高速缓存行到适当的缓存 |
| 缓存命中 | 如果进行高速缓存行填充操作的内存位置仍然是下次处理器访问的地址时,处理器从缓存中读取操作数,而不是从内存中读取 |
| 写命中 | 当处理器将操作数写回到一个内存缓存的区域时,它首先会检查这个缓存的内存地址是否在缓存行中,如果存在一个有效的缓存行,则处理器将这个操作数写回到缓存,而不是写回到内存 |
| 写缺失 | 一个有效的缓存行被写入到不存在的内存区域 |
volatile 的两条实现原则
- 当前处理器缓存行的数据写回到系统内存
- 这个写回内存的操作会使在其他CPU里缓存了该内存地址的数据无效
instance = new SIngleton(); //这个变量被volatile修饰//将它转变成汇编代码后会发现,和普通变量不同的是多了后面一行汇编代码
lock add1$0x0,(%esp)
我们要注意的就是这个lock,因为这个lock,便会执行上面的两条实现原则
由此可知,当被volatile修饰的时候,转变为汇编代码时会有lock前缀的一行汇编代码。在多处理器下,为保证各个处理器的缓存是一致的,就会实现缓存一致性原则。这里用一个小例子来叙述:
用volatile修饰的变量a1起始值为3,则各个处理器将会缓存这个值为3地址,这个时候当处理器1将a1的值修改为4的时候,正在修改的这个时候,将会把对应的缓存锁住,其他处理器暂时不能修改这片缓存上的值。修改成功后释放锁,并将缓存行的数据写回到系统内存中。这个时候,处理器2和处理器3嗅探总线上传播的数据,并检查自己缓存的值对应是否相同,当发现自己内存上对应的值被修改的时候,就会将当前缓存行设置成无效状态,重新从系统中把数据读取到处理器缓存里。
synchronized 的应用
对象头
- 对象自身的运行时数据
如:哈希吗(HashCode)、GC分代年龄(Generational GC Age)等,这部分数据的长度在32位和64位的虚拟机中分别为32bit和64bit,简称“Mark Word” - 如果对象是数组类型,则虚拟机用3个Word(字宽)存储对象头,如果对象是非数组类型,则用2Word存储对象头。
- 指向方法区对象类型数据的指针,如果是数组对象的话,还会有一个额外的部分用于存储数组长度。
- 对象头信息是与对象自身定义的数据无关的额外存储成本。它会根据对象的状态复用自己的存储空间。例如:在32位的HotSpot虚拟机中对象未被锁定的状态下,Mark Word的32bit空间中的25bit用于存储对象哈希吗(HashCode),4bit用于存储对象分代年龄,2bit用于存储锁标志位,1bit固定为0
synchronized 也就是所说的重量级锁,在javaSE 1.6之后引入了“偏向锁”和“轻量级锁”,如今锁一共有四种状态:无状态锁、偏向锁状态、轻量级锁和重量级锁状态。
偏向锁
大多数情况下,锁不仅不存在多线程竞争,而且总是有同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。当一个线程访问同步块的时候并获得锁时,会在对象头和栈桢中的锁记录里存储锁偏向的线程ID,以后该线程在进入和推出同步块的时候不需要进行CAS操作来加锁和解锁,只要简单测试一下对象头的Mark Word里是否储存着指向当前线程的偏向锁。如果测试成功则获得了锁,如果测试失败则要查看Mark Word中标识是否设置为偏向锁,如果是则尝试用CAS将锁指向当前线程,如果不是则升级为竞争锁。
轻量级锁
- 加锁:线程在进行同步块之前,JVM会现在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中,然后将线程尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功则当前线程获得锁,否则表示其他线程在竞争锁,当前线程便尝试使用自旋来获取锁。
- 解锁
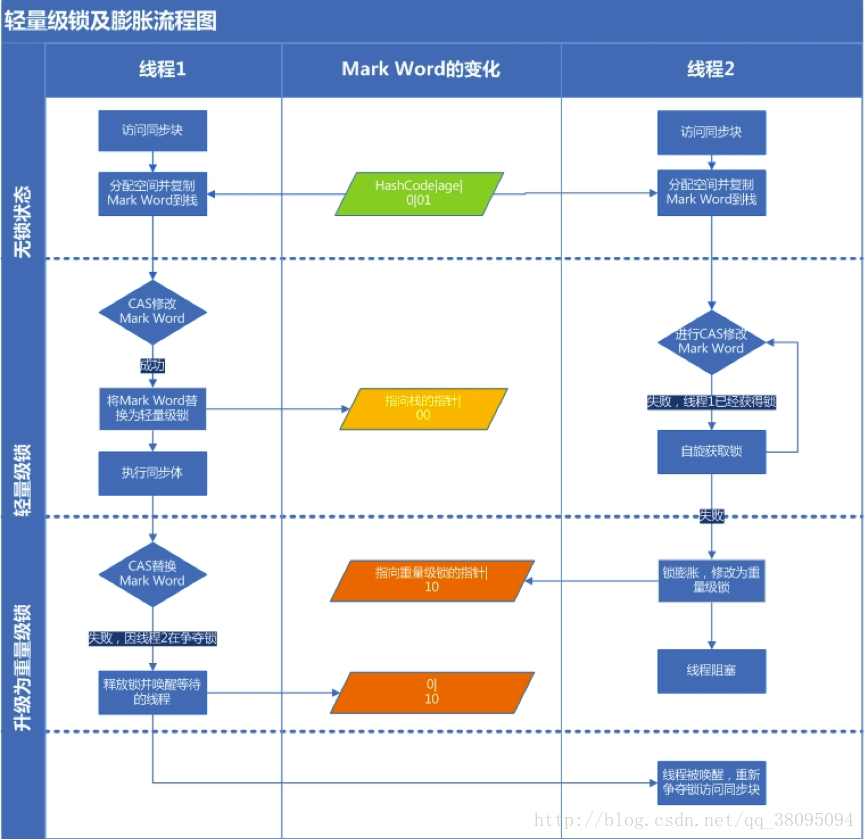
解锁时,会使用原子的CAS操作将对象头复制到锁记录的操作替换到对象头,如果成功就表示没有竞争发生,如果失败则表示当前锁存在竞争,锁就会膨胀成重量级锁。
这是我的第一个总结,最近再看《java并发编程的艺术》这本书,根据我自己的理解做出的总结,可能有些理解会有一点错误,希望各位大牛们看完后可以在评论区中指出我的理解错误,谢谢~~
参考《java并发编程的艺术》