1.梯度爆炸
原因:在学习过程中,梯度变得非常大,使得学习的过程偏离了正常的轨迹。
症状:观察输出日志中每次迭代的loss值,发现loss随着迭代有明显的增长,最后因为loss值太大以致于不能用浮点数去表示,所以变成NaN。
可采取的方法: 1.降低学习率,比如solver.prototxt中base_lr,降低一个数量级。如果在你的模型中有多个loss层,就不能降低基础的学习率base_lr,而是需要检查日志,找到产生梯度爆炸的层,然后降低train_val.prototxt中该层的loss_weight。
2.错误的学习率策略及参数
原因: 在学习过程中,caffe不能得出一个正确的学习率,相反会得到inf或者nan的值,这些错误的学习率乘上所有的梯度使得所有的参数变成无效的值。
症状:观察输出日志,可以看到学习率变为NaN
可采取的方法: 修改solver.prototxt文件中所有能影响学习率的参数。比如,如果你设置的学习率策略是 lr_policy: “poly” ,而你又忘了设置最大迭代次数max_iter,那么最后你会得到lr=NaN…
关于caffe学习率及其策略的内容,可以在github的/caffe-master/src/caffe/proto/caffe.proto 文件中看到传送门
3.错误的损失函数
原因:有时,在损失层计算损失值时会出现NaN的情况。比如,像infogainLoss层没有归一化输入值,使用自定义的损失层等。
症状: 观察输出日志的时候,可能不会发现任何异常:loss逐渐下降,然后突然出现NaN。
可采取的方法:尝试重现该错误,打印损失层的值并调试。
举个例子:根据批量数据中标签出现的频率去归一化惩罚值并以此计算loss。如果有个label并没有在批量数据中出现,频率为0,结果loss出现了NaN的情况。在这种情况下,需要用足够大的batch来避免这个错误。
4.错误的输入
原因:你的输入中存在NaN
症状:一旦学习过程中碰到这种错误的输入,输出就会变成NaN。观察输出日志的时候,可能不会发现任何异常:loss逐渐下降,然后突然出现NaN。
可采取的方法: 重新建立你的输入数据集,确保你的训练集、验证集中没有脏数据(错误的图片文件)。调试时,使用一个简单的网络去读取输入,如果有一个输入的错误,这个网络的loss也会出现NaN。
5.Pooling层的步长大于核的尺寸
由于一些原因,步长stride>核尺寸kernel_size的pooling层会出现NaN。比如:
layer{
name:"faulty_pooling"
type:"Pooling"
bottom:"x"
top:"y"
pooling_param{
pool:AVE
stride:5
kernel:3
}
}结果y会出现NaN。
在271云服务平台训练出现的结果及解决办法
问题
在Linux虚拟机上跑,同样的代码不会出现NaN的情况。
训练的结果
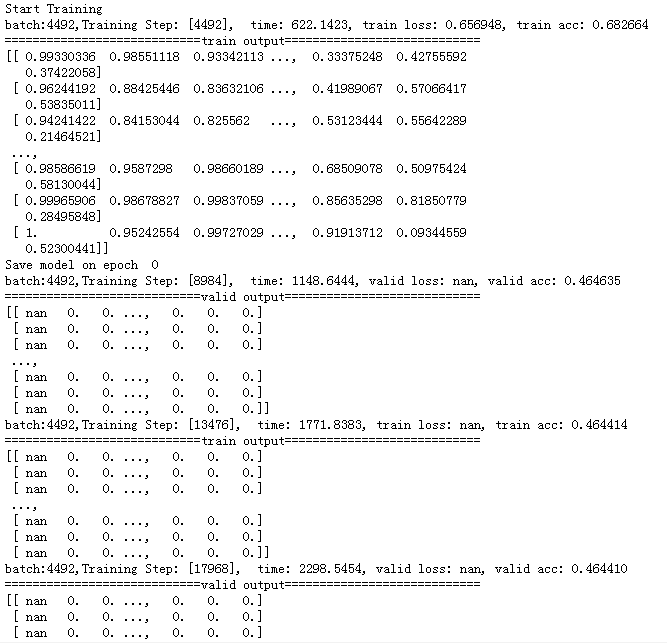
train output:表示训练时网络的最后一层输出,即logits,取值在0~1之间,表示1+4+16=21个CU划分的概率。
valid output:表示验证时网络的最后一层输出,可以看出,包含0值。
尝试
1.程序中输入x表示残差,数值较小,在正负10以内,进行归一化处理之后,乘10进行数值扩大;
没有效果
2.程序中valid数据集跟train数据集是一样的,更换valid数据集;
没有效果
结果
代码没有问题,数据集也没有问题,云服务器可能是读不到数据,== 最近公司在升级,经常出故障。emmmm