目标检测方法比较:
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别。object detection要解决的问题就是物体在哪里,是什么这整个流程的问题。
首先我们可以看一下CNN,它主要用来提取图像特征做分类。
(一)图像分类:CNN
https://blog.csdn.net/liangchunjiang/article/details/79030681
https://blog.csdn.net/ice_actor/article/details/78648780
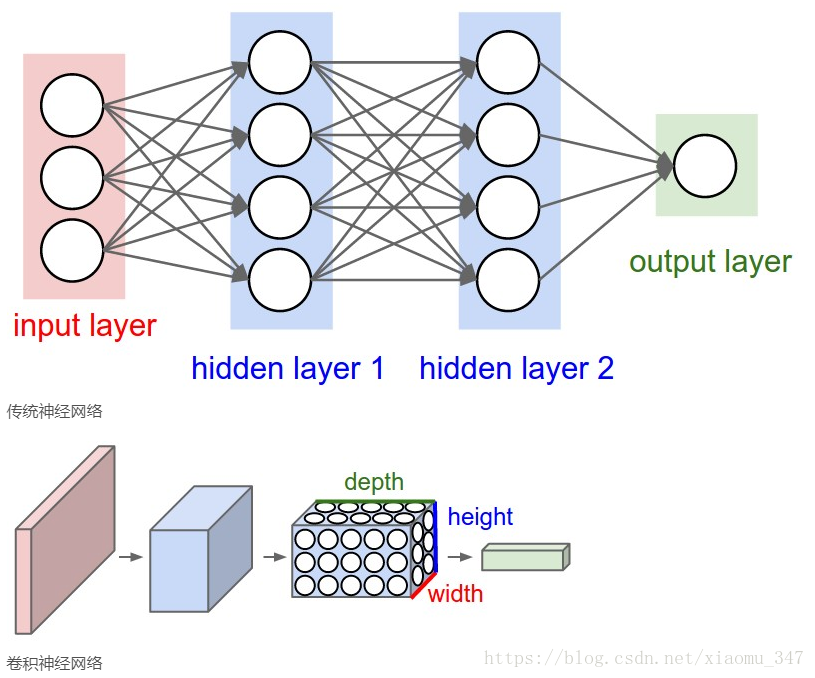
CNN(卷积神经网络)由卷积层、池化层、全连接层等网络结构组成,通过卷积层提取图像特征,全连接层将特征整合扁平化,最后利用分类器输出图像所属类别的概率,取最大的为物体分类结果。
常见的卷积神经网络架构可以这样构建:
INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC
堆叠几个卷积和激励函数(整流层),再加一个池化层,重复这个模式知道图片已经被合并得比较小了,然后再用全连接层控制输出。
上述表达式中 ? 意味着0次或1次,通常情况下:N >= 0 && N <= 3, M >= 0, K >= 0 && K < 3。
(二)目标检测(RCNN->SppNET->Fast-RCNN->Faster-RCNN)
https://www.cnblogs.com/skyfsm/p/6806246.html
例:
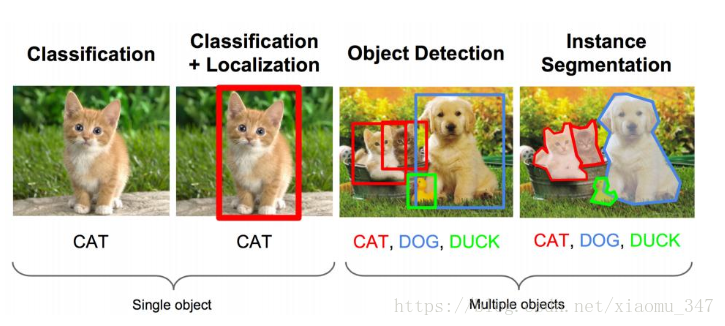
我们要做的就是:图像识别(classification)+目标定位(location)
输入:图片
输出:物体的类别
评估方法:准确率
结果如下:

卷积神经网络CNN已经帮我们完成了图像识别(判定是猫还是狗)的任务了,我们只需要添加图像定位的功能来完成定位任务即可。
针对图像定位(x,y,w,h)常见的方法是采取不同的图像窗口,然后取得分最高的窗口位置作为图像的位置。
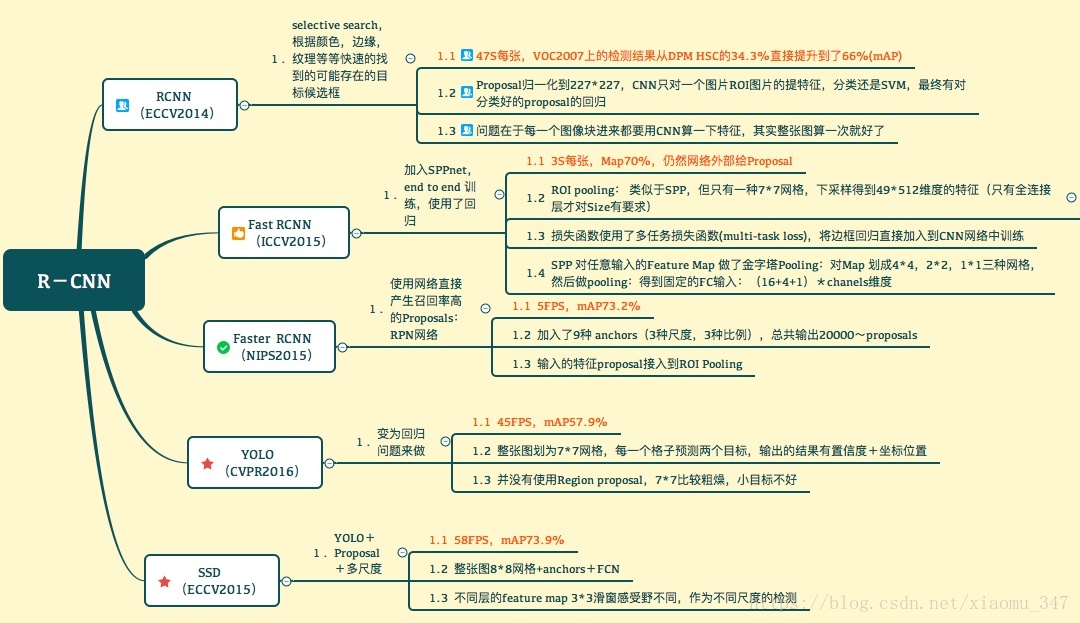
Rcnn:
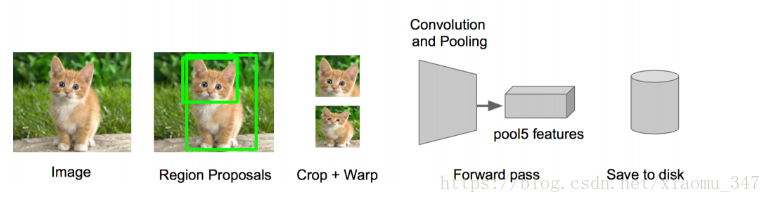
最早的物体识别,是通过窗口扫描的方式进行,并且需要对图片进行几个级别的缩放来重复进行。 这种方式非常暴力,计算量大。
RCNN主要解决的是去掉窗口扫描,用聚类方式,对图像进行分割分组,得到多个侯选框的层次组。 分割分组方法有很多,RCNN用到的是Selective Search。
- 从原始图片,通过Selective Search提取出区域候选框,有2000个左右
- 把所有侯选框缩放成固定大小
- 然后通过CNN网络,提取特征
- 再添加两个全链接层,然后再用SVM分类,回归来微调选框位置与大小
其中SPP:Spatial Pyramid Pooling(空间金字塔池化)思想很重要,下面做简单介绍:
它的特点有两个:
1.结合空间金字塔方法实现CNNs的对尺度输入。
一般CNN后接全连接层或者分类器,他们都需要固定的输入尺寸,因此不得不对输入数据进行crop或者warp,这些预处理会造成数据的丢失或几何的失真。SPP Net的第一个贡献就是将金字塔思想加入到CNN,实现了数据的多尺度输入。
如下图所示,在卷积层和全连接层之间加入了SPP layer。此时网络的输入可以是任意尺度的,在SPP layer中每一个pooling的filter会根据输入调整大小,而SPP的输出尺度始终是固定的。

2.只对原图提取一次卷积特征
在R-CNN中,每个候选框先resize到统一大小,然后分别作为CNN的输入,这样是很低效的。所以SPP Net根据这个缺点做了优化:只对原图进行一次卷积得到整张图的feature map,然后找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层。节省了大量的计算时间,比R-CNN有一百倍左右的提速。

Fast RCNN
先说RCNN的缺点:即使使用了selective search等预处理步骤来提取潜在的bounding box作为输入,但是RCNN仍会有严重的速度瓶颈,原因也很明显,就是计算机对所有region进行特征提取时会有重复计算,Fast-RCNN正是为了解决这个问题诞生的。

R-CNN有一些相当大的缺点(把这些缺点都改掉了,就成了Fast R-CNN)。
大缺点:由于每一个候选框都要独自经过CNN,这使得花费的时间非常多。
解决:共享卷积层,现在不是每一个候选框都当做输入进入CNN了,而是输入一张完整的图片,在第五个卷积层再得到每个候选框的特征
原来的方法:许多候选框(比如两千个)-->CNN-->得到每个候选框的特征-->分类+回归
现在的方法:一张完整图片-->CNN-->得到每张候选框的特征-->分类+回归
所以容易看见,Fast RCNN相对于RCNN的提速原因就在于:不过不像RCNN把每个候选区域给深度网络提特征,而是整张图提一次特征,再把候选框映射到conv5上,而SPP只需要计算一次特征,剩下的只需要在conv5层上操作就可以了。
Faster R-CNN
Fast R-CNN存在的问题:存在瓶颈:选择性搜索,找出所有的候选框,这个也非常耗时。那我们能不能找出一个更加高效的方法来求出这些候选框呢?
解决:加入一个提取边缘的神经网络,也就说找到候选框的工作也交给神经网络来做了。
做这样的任务的神经网络叫做Region Proposal Network(RPN)。
具体做法:
• 将RPN放在最后一个卷积层的后面
• RPN直接训练得到候选区域

RPN简介:
• 在feature map上滑动窗口
• 建一个神经网络用于物体分类+框位置的回归
• 滑动窗口的位置提供了物体的大体位置信息
• 框的回归提供了框更精确的位置

一种网络,四个损失函数;
• RPN calssification(anchor good.bad)
• RPN regression(anchor->propoasal)
• Fast R-CNN classification(over classes)
• Fast R-CNN regression(proposal ->box)

最后总结一下各大算法的步骤:
RCNN
1. 在图像中确定约1000-2000个候选框 (使用选择性搜索)
2. 每个候选框内图像块缩放至相同大小,并输入到CNN内进行特征提取
3. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4. 对于属于某一特征的候选框,用回归器进一步调整其位置
Fast RCNN
1. 在图像中确定约1000-2000个候选框 (使用选择性搜索)
2. 对整张图片输进CNN,得到feature map
3. 找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层
4. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
5. 对于属于某一特征的候选框,用回归器进一步调整其位置
Faster RCNN
1. 对整张图片输进CNN,得到feature map
2. 卷积特征输入到RPN,得到候选框的特征信息
3. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4. 对于属于某一特征的候选框,用回归器进一步调整其位置
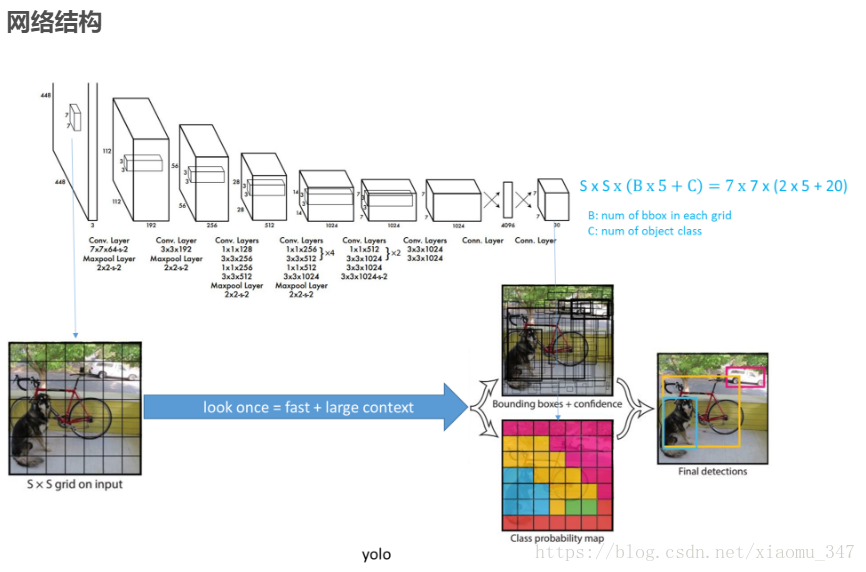
YOLO模型https://blog.csdn.net/qq_23225317/article/details/79552956
YOLO之前的物体检测方法主要是通过region proposal产生大量的可能包含待检测物体的 potential bounding box,再用分类器去判断每个 bounding box里是否包含有物体,以及物体所属类别的 probability或者 confidence,如R-CNN,Fast-R-CNN,Faster-R-CNN等。
YOLO不同于这些物体检测方法,它将物体检测任务当做一个regression问题来处理,使用一个神经网络,直接从一整张图像来预测出bounding box 的坐标、box中包含物体的置信度和物体的probabilities。因为YOLO的物体检测流程是在一个神经网络里完成的,所以可以end to end来优化物体检测性能。
相较于其他的物体检测系统,YOLO在物体定位时更容易出错,但是在背景上预测出不存在的物体(false positives)的情况会少一些。而且,YOLO比DPM、R-CNN等物体检测系统能够学到更加抽象的物体的特征,这使得YOLO可以从真实图像领域迁移到其他领域,如艺术。

使用YOLO来检测物体,其流程是非常简单明了的:
1、将图像resize到448 * 448作为神经网络的输入
2、运行神经网络,得到一些bounding box坐标、box中包含物体的置信度和class probabilities
3、进行非极大值抑制(NMS),筛选Boxes。
注意:非极大值抑制(NMS)
(1)将所有框的得分排序,选中最高分及其对应的框
(2)遍历其余的框,如果和当前最高分框的重叠面积(IOU)大于一定阈值,我们就将框删除。
(3)从未处理的框中继续选一个得分最高的,重复上述过程。
SSD(The Single Shot Detector)
https://blog.csdn.net/lk123400/article/details/53814488
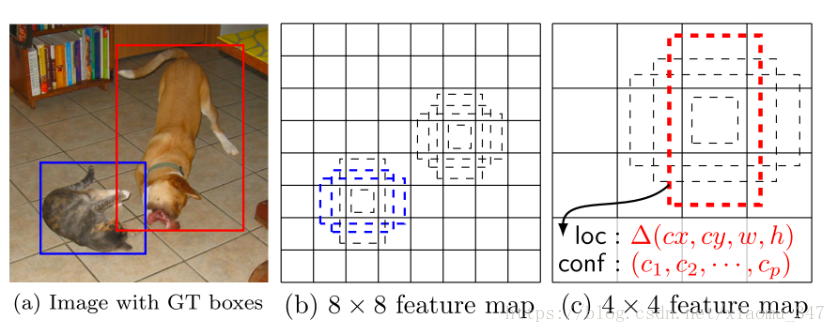
这里,先弄清楚下文所说的 default box 以及 feature map cell 是什么。看下图:
feature map cell 就是将 feature map 切分成 或者 之后的一个个 格子;
而 default box 就是每一个格子上,一系列固定大小的 box,即图中虚线所形成的一系列 boxes。
SSD 是基于一个前向传播 CNN 网络,产生一系列 固定大小(fixed-size) 的 bounding boxes,以及每一个 box 中包含物体实例的可能性,即 score。之后,进行一个 非极大值抑制(Non-maximum suppression) 得到最终的 predictions。
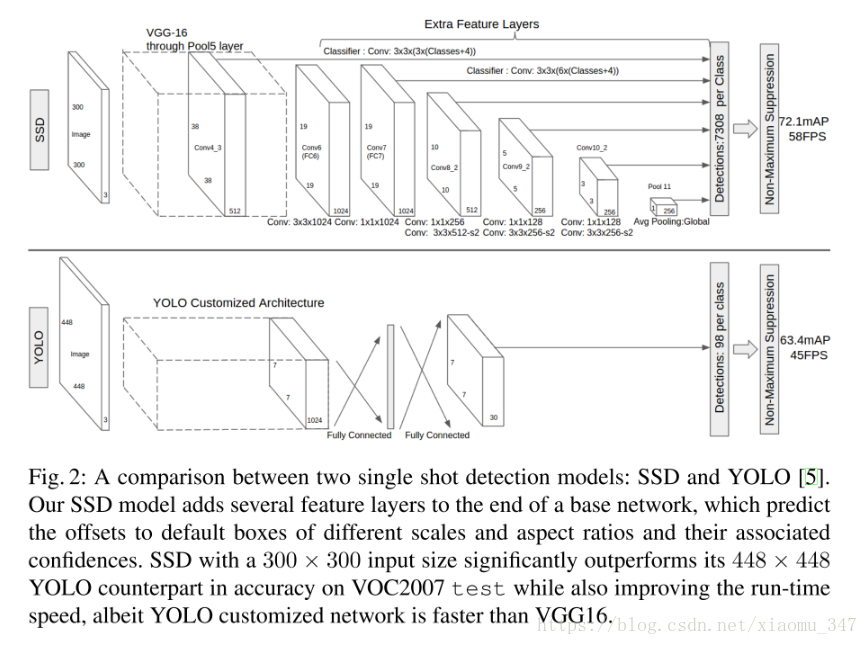
从图上看,SSD和YOLO不同的地方是,YOLO只是对最后一层特征图用来预测回归框,而SSD则是多层,不同大小的特征图都用来做预测和回归。YOLO的缺点是定位不准,对小物体检测效果差,而SSD一定长度上克服了这些难点,因为使用了不同特征图进行预测,SSD的多尺度,用的多层的特征图,是stride=2,不断缩小特征图的长和宽,越靠后的卷积特征图,他的感受野越大,越靠前感受野越小,同时越靠前检测小物体效果更好。但是SSD对小物体检测也并不好,因为前面VGG的已经把特征图下降了16倍。
今天就贴到这,下次继续。总之各种各种检测算法一直在更新,多学习多看论文,向大佬看齐。